
因为模拟宕机的时候,在事务开始的第一条SQL就会报错,而执行SQL都是在Worker线程里面,
所以并不会触发reactor线程中commit超时这种现象,所以测试的时候就遗漏了这一点。
系统一直跑的好好的,为什么突然commit就变慢了呢,而且笔者发现,这个commit变慢所关联的DB正好也是出现慢SQL的那个DB。于是笔者立马就去找了DBA,由于我们应用层和数据库层都没有commit时间的监控(因为一般都很快,很少出现慢的现象)。DBA在数据库打的日志里面进行了统计,发现确实变慢了,而且变慢的时间和我们应用报错的时间相符合!
顺藤摸瓜,我们又联系了SA,发现其中和存储相关的HBA卡有报错!如下图所示:
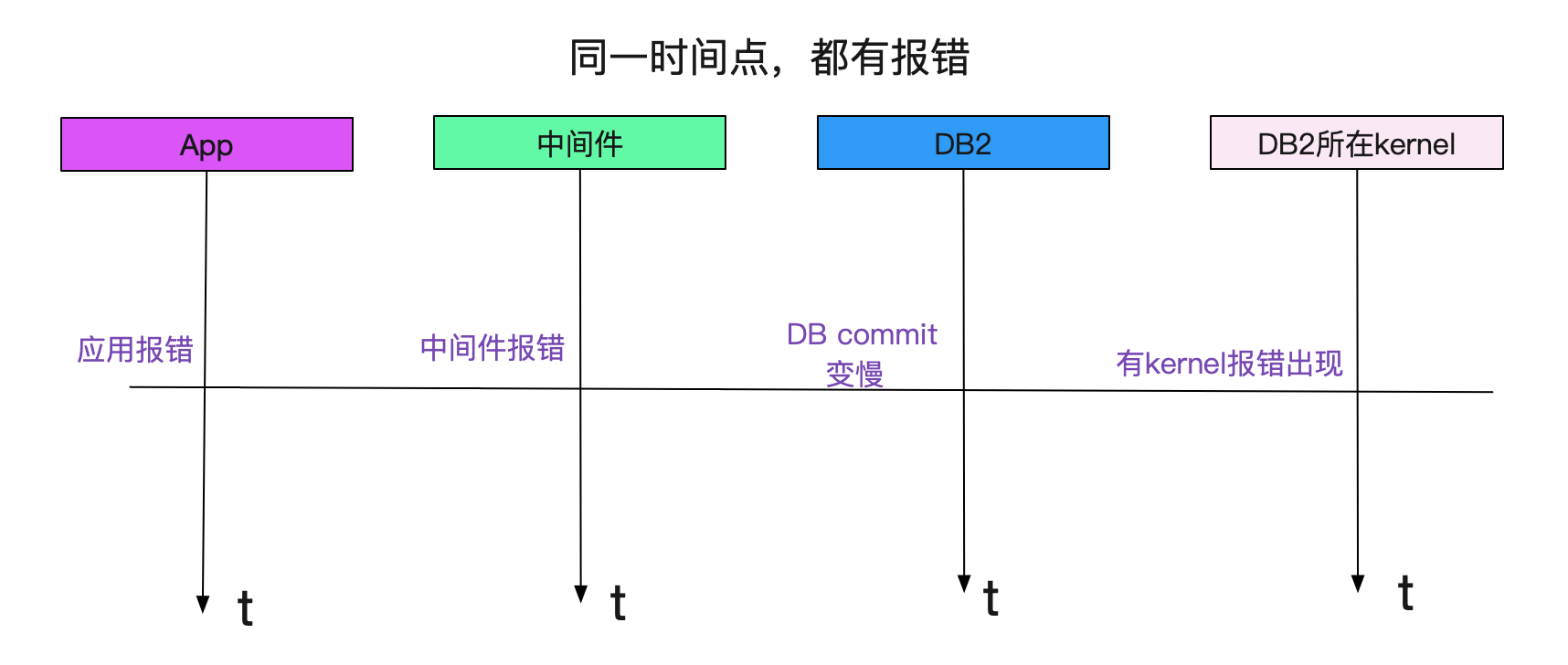
报错时间都是一致的! 紧急修复方案
由于是HBA卡报错了,属于硬件故障,而硬件故障并不是很快就能进行修复的。所以DBA做了一次紧急的主从切换,进而避免这一问题。

之前就有慢sql慢慢变多,而后突然数据库存储hba卡宕机导致业务不可用的情况。
而这一次到最后主从切换前为止,报错越来越频繁,感觉再过一段时间,HBA卡过段时间就完全不可用,重蹈之前的覆辙了!
我们在中间件层面将commit和rollback操作挪到Worker里面。这样,commit如果卡住就不再会引起创建连接失败这种应用报错了。
总结由于软件层面其实是比较信任硬件的,所以在硬件出问题时,就会产生很多诡异的现象,而且和硬件最终的原因在表面上完全产生不了关联。只有通过抽丝剥茧,慢慢的去探寻现象的本质才会解决最终的问题。要做到高可用真的是要小心评估各种细节,才能让系统更加健壮!
公众号关注笔者公众号,获取更多干货文章:
