
但是我们还有另外一种方式,就是使用注解的方式不用继承这个接口。
@RepositoryDefinition(domainClass = Student.class,idClass = Integer.class) public interface StudentRepository { } 2. 常用的子接口CrudRepository:继承Repository,实现了CRUD相关的方法
PagingAndSortingRepository:继承CrudRepository,实现了分页排序相关的方法
JpaRepository:继承PagingAndSortingRepository,实现JPA规范相关的方法
这些接口的功能都是非常强大并且实用的我们在使用的时候就可以直接继承这些接口。
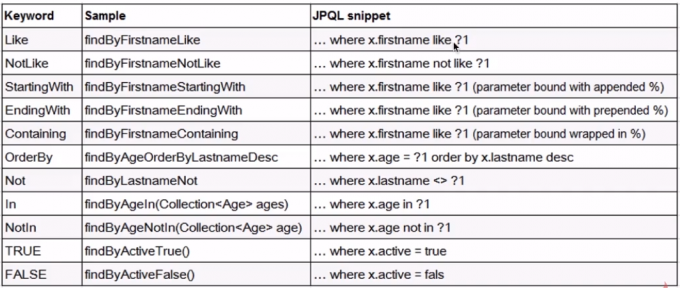
3.查询规则 1.约定方法签名查询
在SpringData中使用插删改操作的时候我们必须定义一个Service层,然后我们在Service层调用Dao的Repository来更新数据库,接着我们需要将那个Repository的方法设置为 @Modifying ,最后最重要的就是我们在Service层的那个方法中写 @Transactional 注解。才能更新成功,所以所有的事务只能出现在 Service 层。但是注意因为我们的Service没有继承任何的Spring相关的东西我们要把它放到容器的时候需要使用@Service注解,否则是不行的。
@Modifying @Query("update Employee o set o.name=:name where o.id=:id") void update(@Param("id") Integer id,@Param("name") String name); @Service public class EmployeeService { @Autowired EmployeeRepository repository; @Transactional //这个是javax里面的 public void update(){ repository.update(1, "lwenxu"); } }小提示,很多时候我们发现有些东西在Spring中有在javax中也有,我们优先导入Javax中的,如果出现了什么方法无法调用估计就是包导错了。
3. 常用的Repository这三个高级的Repository实际上是从上到下依次继承的。
1. CrudRepository我们的Repository必须要继承这个接口,然后我们就有crud的一些操作了。接着我们需要创建service层,然后再service中使用事务,并且注入我们的Repository,这里我们用了一张新的表我们在bean上指定我们的表名就是使用@Table(name = "employee_test") 注解。最后进行save操作。
@Transactional public void saveAll(List<Employee> employees){ employeeCrudRepository.save(employees); } EmployeeCrudRepository employeeCrudRepository = ctx.getBean(EmployeeCrudRepository.class); ArrayList<Employee> employees = new ArrayList<Employee>(); for (int i = 0; i < 100; i++) { employees.add(new Employee(i, "lwen" + i, i)); } employeeCrudRepository.save(employees); 2.PagingAndSortingRespository他是分页和排序功能。
EmployeePageAndSortRepository pageAndSort = ctx.getBean(EmployeePageAndSortRepository.class); //创建一个排序器,是按照id的降续排列的 Sort sort = new Sort(new Sort.Order(Sort.Direction.DESC, "id")); //第一个参数是当前的页码他是从0开始的 //第二个参数就是每一页的大小 //第三个参数是可选参数,传入一个sort,就是按照哪种方式分页 由于这里用的是降续所以出来的结果应该是 0 在最后一页 99在第一页 Pageable pageable = new PageRequest(0, 9, sort); Page<Employee> page = pageAndSort.findAll(pageable); //获取当前页的内容 System.out.println(page.getContent()); //获取所有的页数 System.out.println(page.getTotalPages()); 3.JpaRepositoryfindAll
save(entries)
deleteInBatch
findAll(sort)
flush
4. JpaSpecificationExecutor这里吧这个接口单独拿出来说主要是因为这个接口实际上不是继承自 Repository 这个接口,他的作用从表面上貌似也是看不出来,实际上我们前面看到我们可以进行简单的分页,但是那些分页并没有一个让我们传入查询条件的地方,我们这个接口就是实现了这个功能也就是有条件的分页查询。
jpa接口需要继承 JpaSpecificationExecutor 然后这里就包含了五个方法,分别是 findAll(三个重载) 和 findOne 以及 count 。
然后在使用的时候只调用对应的方法即可,Page
new Specification<User>() { public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { return criteriaBuilder.gt(root.<Number>get("id"),4); } }