正则表达式是一个特殊的字符序列,用于简洁表达一组字符串特征,检查一个字符串是否与某种模式匹配,使用起来十分方便。
在Python中,我们通过调用re库来使用re模块:
import re
正则表达式语法模式和操作符详见:
下面介绍Python常用的正则表达式处理函数。
re.match函数
re.match 函数从字符串的起始位置匹配正则表达式,返回match对象,如果不是起始位置匹配成功的话,match()就返回None。
re.match(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。具体参数为:
re.I:忽略大小写。
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境。
re.M:多行模式。
re.S:即 . ,并且包括换行符在内的任意字符(. 不包括换行符)。
re.U:表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库。
re.X:为了增加可读性,忽略空格和 # 后面的注释。
import re #从起始位置匹配 r1=re.match('abc','abcdefghi') print(r1) #不从起始位置匹配 r2=re.match('def','abcdefghi') print(r2)
运行结果:
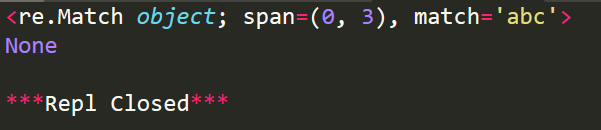
其中,span表示匹配成功的整个子串的索引。
使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num):匹配的整个表达式的字符串,group() 可以一次输入多个组号,这时它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re s='This is a demo' r1=re.match(r'(.*) is (.*)',s) r2=re.match(r'(.*) is (.*?)',s) print(r1.group()) print(r1.group(1)) print(r1.group(2)) print(r1.groups()) print() print(r2.group()) print(r2.group(1)) print(r2.group(2)) print(r2.groups())
运行结果:

上述代码中的(.*)和(.*?)表示正则表达式的贪婪匹配与非贪婪匹配,详情见此:https://www.jb51.net/article/31491.htm
re.search函数
re.search函数扫描整个字符串并返回第一个成功的匹配,如果匹配成功则返回match对象,否则返回None。
re.search(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re #从起始位置匹配 r1=re.search('abc','abcdefghi') print(r1) #不从起始位置匹配 r2=re.search('def','abcdefghi') print(r2)
运行结果:

使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,这时它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re s='This is a demo' r1=re.search(r'(.*) is (.*)',s) r2=re.search(r'(.*) is (.*?)',s) print(r1.group()) print(r1.group(1)) print(r1.group(2)) print(r1.groups()) print() print(r2.group()) print(r2.group(1)) print(r2.group(2)) print(r2.groups())
运行结果:
从上面不难发现re.match与re.search的区别:re.match只匹配字符串的起始位置,只要起始位置不符合正则表达式就匹配失败,而re.search是匹配整个字符串,直到找到一个匹配为止。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式对象,供 match() 和 search() 这两个函数使用。
re.compile(pattern[, flags])
pattern:一个字符串形式的正则表达式。
flags:可选,表示匹配模式,比如忽略大小写,多行模式等。
import re #匹配数字 r=re.compile(r'\d+') r1=r.match('This is a demo') r2=r.match('This is 111 and That is 222',0,27) r3=r.match('This is 111 and That is 222',8,27) print(r1) print(r2) print(r3)
运行结果:

findall函数
搜索字符串,以列表形式返回正则表达式匹配的所有子串,如果没有找到匹配的,则返回空列表。
需要注意的是,match 和 search 是匹配一次,而findall 匹配所有。
findall(string[, pos[, endpos]])
string:待匹配的字符串。
pos:可选参数,指定字符串的起始位置,默认为0。
endpos:可选参数,指定字符串的结束位置,默认为字符串的长度。