在开发中直接接触Transform流的情况不是很多,往往是使用相对成熟的模块或者封装的API来完成流的处理,最为特殊的莫过于through2模块和gulp流操作。那么,Transform流到底有什么特点呢?
从名称上说,Transform意为处理,类似于生产流水线上的每一道工序,每道工序针对到来的产品作相应的处理;从结构上看,Transform是一个双工流,通俗的解释它既可以作为可读流,也可作为可写流。但是,node却对Transform流针对其特性做了更为特殊的定制,使Transform不是单纯的Duplex流。
Transform流由于包含了Readable和Writeable特性,因此Transform在实际使用中有着多种方式:它既可以只作为消费者消费数据,也可同时作为生产者和消费者完成数据中间处理。下面将逐渐深入内部阐述Transform的运行机理及使用技巧。
Transform内部架构
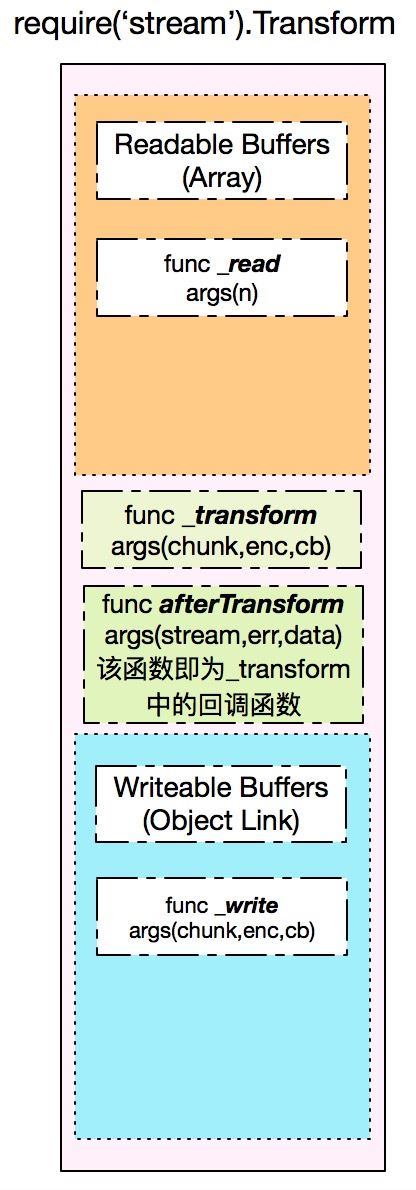
上图表示一个Transform实例的组成部分:Readable部分缓冲(数组)、内部_read函数、Writeable部分缓冲(链表)、内部_write函数、Transform实例必须实现的内部_transform函数以及系统提供的回调函数afterTransform。由于Transform实例同时拥有两部分缓冲,因此2个缓冲的存储、消耗的顺序也就需要了解,这对于后面使用原生Transform编写代码有很大的指导意义。
传统意义的流(即Readable和Writeable)的实现者都需要实现对应的内部函数_read()和_write(),对于Readable实例而言,_read函数用于准备从源文件中获取数据并添加到读缓冲中;对于Writeable实例_write函数则从写缓冲链表中一次刷入到磁盘中。它们分别对应了读写流程的首尾步骤,具体可以关注node中的Stream一文。
而Transform中的_read和_write函数的实现大有不同,由于需要兼顾流的处理,因此着重分析Transform的内部函数执行流程。

示例demo:
readable.pipe(transform);
以上段示例代码为例,transform作为消费者消费readable。
Transform的实例transform拥有transormState和readableState属性,保存了相关属性,如tranform状态信息、回调函数存储和编码等。transform作为消费者,会在其write函数中消费数据,在node中的Stream文中介绍了write函数的实现细节,通过内部调用_write函数实现数据的写入。而在Transform中_write函数已经重写:
1.保存transform收到的chunk数据、编码和函数(执行刷新写缓冲)
2.在一定条件下执行_read函数(当状态为非转换下,只要读缓冲大小未超过设定的大小,则执行_read)
如果一切顺利,readable的数据会顺利执行transform的**write->_write->_read**,那么原本负责填充读缓冲的_read在Transform中发生了哪些改变呢?
Transform.prototype._read = function(n) { var ts = this._transformState; if (ts.writechunk !== null && ts.writecb && !ts.transforming) { ts.transforming = true; this._transform(ts.writechunk, ts.writeencoding, ts.afterTransform); } else { // mark that we need a transform, so that any data that comes in // will get processed, now that we've asked for it. ts.needTransform = true; } };
可见,_read的实现非常简单,根据条件选择执行_transform函数。需要注意的是_read的参数n并未有使用,因为是否插入数据至读缓冲是由开发者在_transform中来决定。相信大家对_transform函数并不陌生,node规定Transform实例必须提供_transform函数,而该函数正是在_read中调用。
_transform有三个参数,第一个为待处理的chunk数据,第二个为编码,第三个为回调函数。前两个参数很好理解,我们可以在_transform中尽情的处理数据,最后调用回调函数完成处理。那么,这个回调函数究竟是什么? 它就是Transform架构图中的afterTransform函数,它有几个功能:
1.清空各种状态信息,如transformState对象的一些属性,用于下次处理数据使用
2.可选的保存处理结果至读缓冲区
3.刷新写缓冲区,执行下一阶段的数据流处理
可见,在afterTransform函数执行后,才基本宣告transform第一阶段的结束。为何是第一阶段呢?因为transform才完成了作为消费者(即Writeable)的作用,如果用户在_transform中传入了数据到写缓冲区,那么此时transform也同时是一个生产者,提供数据让后面的消费者消费数据,这就涉及到了Transform使用上的问题。
Transform的生产消费实例
const stream = require('stream') var c = 0; const readable = stream.Readable({ highWaterMark: 2, read: function () { var data = c < 26 ? String.fromCharCode(c++ + 97) : null; console.log('push', data); this.push(data); } }) const transform = stream.Transform({ highWaterMark: 2, transform: function (buf, enc, next) { console.log('transform', buf.toString()); next(null, buf); } }) readable.pipe(transform);