Lustre的全局命名空间为文件系统的所有客户端提供了一个有效的全局唯一的目录树,并将数据条块化,再把数据分配到各个存储服务器上,提供了比传统SAN的"块共享"更为灵活的共享访问方式。全局目录树消除了在客户端的配置信息,并且在配置信息更新时仍然保持有效。
1、Lustre iozone测试
针对对象存储文件系统,我们对Lustre文件系统作了初步测试,具体配置如下:
3台双至强系统:CPU:1.7GHz,内存:1GB,千兆位以太网
Lustre文件系统:lustre-1.0.2
Linux版本:RedHat 8
测试程序:iozone
测试结果如下:
块写(MB/s/thread)
单线程
两个线程
Lustre
1个OST
2个OST
1个OST
2个OST
21.7
50
12.8
24.8
NFS
12
5.8
从以上的测试表明,单一OST的写带宽比NFS好,2个OST的扩展性很好,显示strip的效果,两个线程的聚合带宽基本等于饱和带宽,但lustre客户方的CPU利用率非常高(90%以上),测试系统的规模(三个节点)受限,所以没有向上扩展OST和client数量。另外,lustre的cache 对文件写的性能提升比NFS好。通过bonnie++初步测试了lustre的元数据处理能力,和NFS比,文件创建速度相对快一些,readdir速度慢。
2、lustre小规模测试数据
(文件写测试,单位KB/s):
硬件:Dual Xeon1.7,GigE, SCSI Ultra160 软件:RedHat8,iozone

图2 2个OST / 1个MDS
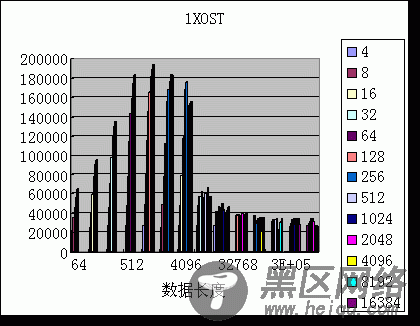
图3 1个OST/1个MDS
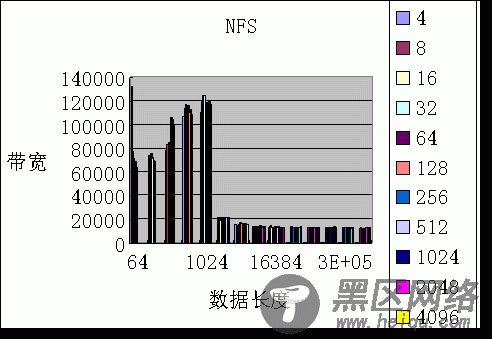
图4 NFS测试