JavaScript定义正则表达式有两种方法。
1.RegExp构造函数
var pattern = new RegExp("[bc]at","i");
它接收两个参数:一个是要匹配的字符串模式,另一个是可选的标志字符串。
2.字面量
var pattern = /[bc]at/i;
正则表达式的匹配模式支持三种标志字符串:
g:global,全局搜索模式,该模式将被应用于所有字符串,而并非搜索到第一个匹配项就停止搜索;
i:ingore case,忽略字母大小写,即在确定匹配项时忽略模式和字符串大小写;
m:multiple lines,多行模式,即在搜索到达一行文本末尾时会继续查找下一行是否有匹配项。
这两种创建正则表达式方法的不同之处在于,正则表达式字面量始终会共享同一个RegExp实例,而使用构造函数创建的每一个新RegExp实例都是新实例。
元字符
元字符是拥有特殊意义的字符,正则表达式的元字符主要有:
( [ { \ ^ $ | ) ? * + .
在不同的组合中元字符有其不同的意义。
预定义特殊字符
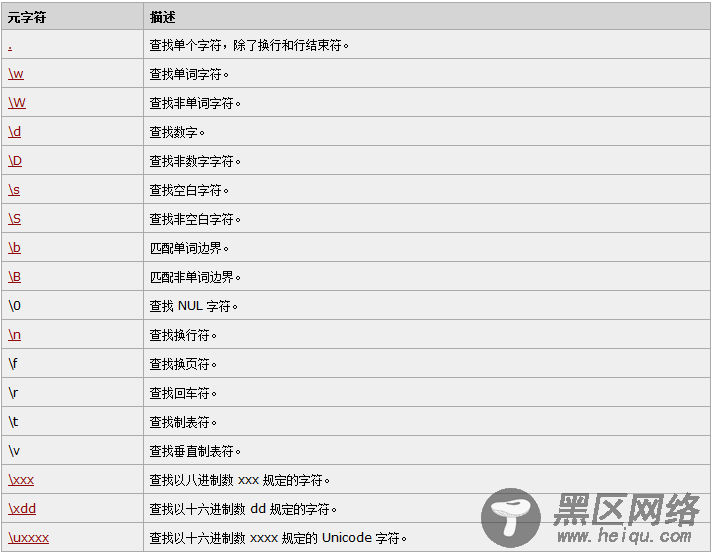
字符类 简单类
一般情况下正则表达式一个字符对应字符串一个字符,但我们可以使用[]来构建一个简单的类,来表示符合某一特征的一类字符。例如:
[abc]可以匹配方括号中的a、b、c或其任意组合的字符。
反向类
既然[]可以构建一个类,那么自然就会联想到与之对应的不包含括号中内容的类,这个类叫做反向类,例如[^abc]就可以匹配不是a或b或c的字符。
范围类
有时候一个一个字符匹配太麻烦而且匹配的类型也相同,此时我们可以使用"-"连接线来表示某个闭区间之间的内容,例如匹配所有小写字母可以使用[a-z],如下:
匹配所有的0到9简直的任意数字可以使用[0-9]表示:
预定义类
对于如上我们创建的几个类,正则表达式为我们提供了几个常用的预定义类来匹配常见的字符,如下:
字符
等价类
含义
.
[^\n\r]
匹配除了回车符和换行符之外的所有字符
\d
[0-9]
数字字符
\D
[^0-9]
非数字字符
\s
[\t\n\x0B\f\r]
空白字符
\S
[^\t\n\x0B\f\r]
非空白字符
\w
[a-zA-Z_0-9]
单词字符(字母、数字和下划线)
\W
[^a-zA-Z_0-9]
非单词字符
量词
上面的方法匹配字符都是一对一匹配的,如果某个字符连续出现多次按照上面的方法匹配会非常麻烦,因此我们想有没有其它方法可以直接匹配多次重复出现的字符。正则表达式为我们提供了一些量词,如下:
字符
含义
?
出现零次或一次(最多一次)
+
出现一次或多次(至少一次)
*
出现零次或多次(任意次)
{n}
出现n次
{n,m}
出现n到m次
{n,}
至少出现n次
贪婪模式与非贪婪模式
对于{n,m}这种匹配方式,到底是匹配n个还是匹配m个呢?这就涉及到匹配模式的问题。默认情况下,量词是尽可能多的匹配字符,也就是所谓的贪婪模式,例如:
var num = '123456789'; num.match(/\d{2,4}/g); //[1234]、[5678]、[9]
与贪婪模式对于的是非贪婪模式,只需要在量词之后加"?"即可,例如{n,m}?,就是按照最少的字符匹配,如下:
var num = '123456789'; num.match(/\d{2,4}?/g); //[12]、[34]、[56]、[78]、[9]
分组
量词只能是单个字符匹配多次,如果我们希望匹配某一组字符多次呢?正则表达式中小括号可以定义一个字符串整体为一个分组。
我们想要匹配apple这个单词出现4次可以这样匹配(apple){4},如下:
如果想要匹配apple或orange出现4次,可以插入管道符"|",例如:
(apple|orange){4}
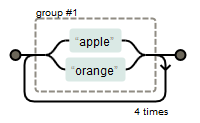
如果使用分组的正则表达式中出现多个小括号即多个分组,那么匹配结果就会把匹配项也分组并编号,例如:
(apple)\d+(orange)
如果我们不希望捕获某些分组,只需要在分组的小括号前面紧跟一个问号和冒号即可,例如:
(?:apple)\d+(orange)
边界
正则表达式也为我们提供了几个常用的边界匹配字符,例如: