c源码中去掉适配python的包装,仅定义system函数本身,这比第二种方式简洁很多,并且剔除了c代码与python的耦合代码,是c代码通用性更好。
然后编写swig接口声明文件spam.i:
这是一段语言无关的模块声明,要创建一个叫spam的模块,对system做一个声明,主要是声明参数作为入参使用。然后执行swig编译程序:
>swig -c++ -python spam.iswig会生成spam_wrap.cxx和spam.py两个文件。先看spam_wrap.cxx,这个生成的文件很长,但关键的就是对函数的包装:
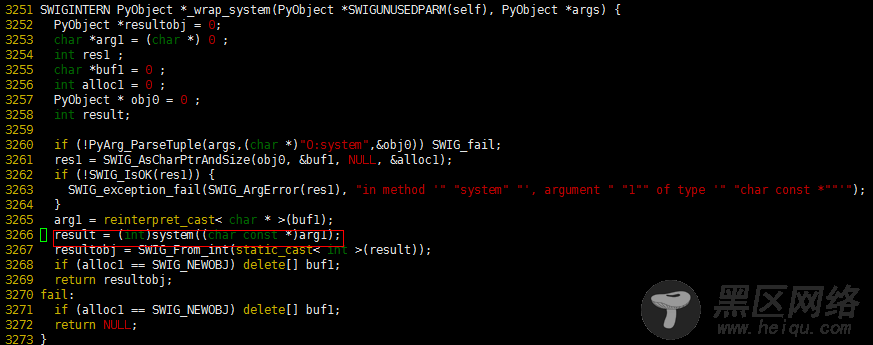
包装函数传入的还是PyObejct对象,内部进行了类型转换,最终调了源码中的system函数。
生成的了另一个spam.py实际上是对so库又用python包装了一层(实际比较多余):

这里使用_spam模块,这里实际上是把扩展命名为了_spam。关于swig在python上的应用可以参见:
下面就是编译和安装python 模块,Python提供了distutils module,可以很方便的编译安装python的module。像下面这样写一个安装脚本setup.py:

执行 python setup.py build,即可以完成编译,程序会创建一个build目录,下面有编译好的so库。so库放在当前目录下,其实Python就可以通过import来加载模块了。当然也可以用 python setup.py install 把模块安装到语言的扩展库——site-packages目录中。关于build python扩展,可以参考https://docs.python.org/2/extending/building.html#building
混合编程性能分析混合编程的使用场景中,很重要一个就是性能攸关。那么这小节将通过几个小实验验证下混合编程的性能如何,或者说怎样写程序能发挥好混合编程的性能优势。
我们使用冒泡排序算法来验证性能。
1)实验一 使用冒泡程序验证python和c/c++程序的性能差距
python版冒泡程序:
def bubble(arr,length): j = length - 1 while j >= 0: i = 0 while i < j: if arr[i] > arr[i+1]: tmp = arr[i+1] arr[i+1] = arr[i] arr[i] = tmp i += 1 j -= 1c语言版冒泡排序
void bubble(int* arr,int length){ int j = length - 1; int i; int tmp; while(j >= 0){ i = 0; while(i < j){ if(arr[i] > arr[i+1]){ tmp = arr[i+1]; arr[i+1] = arr[i]; arr[i] = tmp; } i += 1; } j -= 1; } } 使用一个长度为100内容固定的数组,反复排序10000次(每次排序后,再把数组恢复成原始序列),记录执行时间: 在相同的机器上多次执行,Python版执行时间是10.3s左右,而c语言版本(未使用任何优化编译参数)执行时间只有0.29s左右。相比之下python的性能的确差很多(主要是python中list的操作跟c的数组相比,效率差非常多),但python中很多扩展都是c语言写的,目的就是为了提升效率,python用于数据分析的numpy库就拥有不错的性能。下个实验就验证,如果python使用c语言版本的冒泡排序扩展库,性能会提升多少。2)实验二 python语言使用ctypes方式调用
这里直接使用c_int来定义了数组对象,这也节省了调用时数据类型转换的开销:
再次执行:
为了减少误差,把循环增加到10万次,结果c原生程序使用优化参数编译后用时0.65s左右。python使用c扩展后(相同编译参数)执行仅需2.3s左右。
3)实验三 在c语言中使用PyObject处理入参
这种方式是在python中依然使用list装入待排序数列,在c函数中把list赋值给数组,再进行排序,排好序后,再对原始list赋值。循环排序10万次,执行用时1.0s左右。
4) 实验四 使用swig来包装c方法
在接口文件中声明%array_class(int,intArray);然后在Python中使用initArray来作为数组,同样修改成10万次排序。python版本的程序(相同编译参数)执行仅需0.7s左右,比c原生程序慢大概7%。