javascript的字符集:
javascript程序是使用Unicode字符集编写的。Unicode是ASCII和Latin-1的超集,并支持地球上几乎所有的语言。ECMAScript3要求JavaScript必须支持Unicode2.1及后续版本,ECMAScript5则要求支持Unicode3及后续版本。所以,我们编写出来的
javascript程序,都是使用Unicode编码的。
UTF-8
UTF-8(UTF8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。
它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码。
目前大部分的网站,都是使用的UTF-8编码。
将javascript生成的Unicode编码字符串转为UTF-8编码的字符串
如标题所说的应用场景十分常见,例如发送一段二进制到服务器时,服务器规定该二进制内容的编码必须为UTF-8。这种情况下,我们必须就要通过程序将javascript的Unicode字符串转为UTF-8编码的字符串。
转换方法
转换之前我们必须了解Unicode的编码结构是固定的。
不信可以试一试 String 的 charCodeAt 这个方法,看看返回的 charCode 占几个字节。
•英文占1个字符,汉字占2个字符
然而,UTF-8的编码结构长度是根据某单个字符的大小来决定长度有多少。
下面为单个字符的大小占用几个字节。单个unicode字符编码之后的最大长度为6个字节。
•1个字节:Unicode码为0 - 127
•2个字节:Unicode码为128 - 2047
•3个字节:Unicode码为2048 - 0xFFFF
•4个字节:Unicode码为65536 - 0x1FFFFF
•5个字节:Unicode码为0x200000 - 0x3FFFFFF
•6个字节:Unicode码为0x4000000 - 0x7FFFFFFF
具体请看图片:
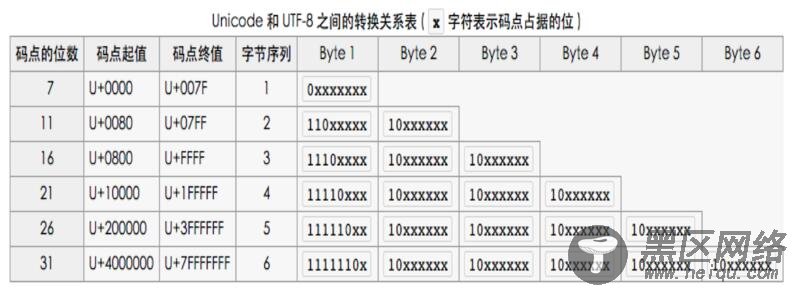
因为英文和英文字符的Unicode码为0 - 127,所以英文在Unicode和UTF-8中的长度和字节都是一致的,只占用1个字节。这也就是为什么UTF8是Unicode的超集!
现在我们再来讨论汉字,因为汉字的unicode码区间为0x2e80 - 0x9fff, 所以汉字在UTF8中的长度最长为3个字节。
那么汉字是如何从Unicode的2个字节转换为UTF8的三个字节的哪?
假设我需要把汉字"中"转为UTF-8的编码
1、获取汉字Unicode值大小
var str = '中'; var charCode = str.charCodeAt(0); console.log(charCode); // => 20013
2、根据大小判断UTF8的长度
由上一步我们得到汉字"中"的charCode为20013.然后我们发现20013位于2048 - 0xFFFF这个区间里,所以汉字"中"应该在UTF8中占3个字节。
3、补码
既然知道汉字"中"需要占3个字节,那么这3个字节如何得到哪?
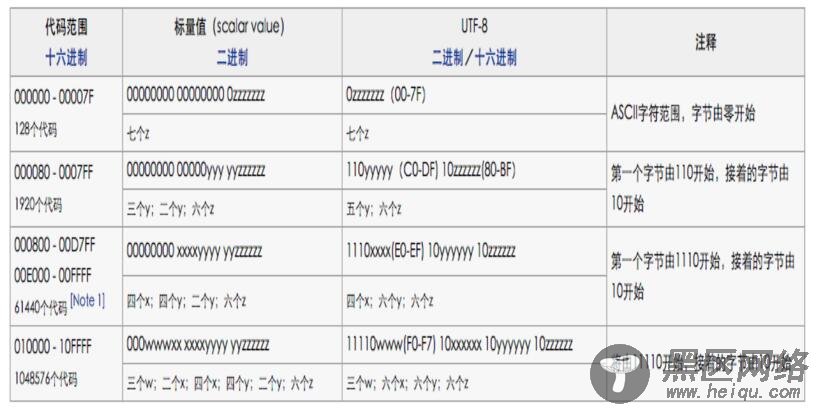
这就需要设计到补码,具体补码逻辑如下:
好吧,我知道这个图你们也看不明白,还是我来讲吧!
具体的补位码如下,"x"表示空位,用来补位的。
•0xxxxxxx
•110xxxxx 10xxxxxx
•1110xxxx 10xxxxxx 10xxxxxx
•11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
•111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
•1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
warning:有没有发现?补位码第一个字节前面有几个1就表示整个UTF-8编码占多少个字节!UTF-8解码为Unicode就是利用的这个特点哦~
我们先举个简单的例子。把英文字母"A"转为UTF8编码。
1、“A”的charCode为65
2、65位于0-127的区间,所以“A”占一个字节
3、UTF8中一个字节的补位为0xxxxxxx,x表示的是空位,是用来补位的。
4、将65转为二进制得到1000001
5、将1000001按照从前到后的顺序,依次补到1xxxxxxx的空位中,得到01000001
6、将11000001转为字符串,得到"A"
7、最终,"A"为UTF8编码之后“A”
通过这个小例子,我们是否再次验证了UTF-8是Unicode的超集!
好了,我们现在再回到汉字"中"上,之前我们已经得到了"中"的charCode为20013,二进制为01001110 00101101。具体如下:
var code = 20013; code.toString(2); // => 100111000101101 等同于 01001110 00101101
然后,我们按照上面“A”补位的方法,来给"中"补位。
将01001110 00101101按照从前到后的顺序依此补位到1110xxxx 10xxxxxx 10xxxxxx上.得到11100100 10111000 10101101.
4、得到UTF8编码的内容
通过上面的步骤,我们得到了"中"的三个UTF8字节,11100100 10111000 10101101。
我们将每个字节转为16进制,得到0xE4 0xB8 0xAD;
那么这个0xE4 0xB8 0xAD就是我们最终得到的UTF8编码了。
我们使用nodejs的buffer来验证一下是否正确。
var buffer = new Buffer('中'); console.log(buffer.length); // => 3 console.log(buffer); // => <Buffer e4 b8 ad> // 最终得到三个字节 0xe4 0xb8 0xad
因为16进制是不分大小写的,所以是不是跟我们算出来0xE4 0xB8 0xAD一模一样。
将上面的编码逻辑写到一个函数中。