比较ReentrantLock和synchronized的可伸缩性
Tim Peierls 用一个简单的线性全等伪随机数生成器(PRNG)构建了一个简单的评测,用它来测量 synchronized 和 Lock 之间相对的可伸缩性。这个示例很好,因为每次调用 nextRandom() 时,PRNG 都确实在做一些工作,所以这个基准程序实际上是在测量一个合理的、真实的 synchronized 和 Lock 应用程序,而不是测试纯粹纸上谈兵或者什么也不做的代码(就像许多所谓的基准程序一样。)
在这个基准程序中,有一个 PseudoRandom 的接口,它只有一个方法 nextRandom(int bound) 。该接口与 java.util.Random 类的功能非常类似。因为在生成下一个随机数时,PRNG 用最新生成的数字作为输入,而且把最后生成的数字作为一个实例变量来维护,其重点在于让更新这个状态的代码段不被其他线程抢占,所以我要用某种形式的锁定来确保这一点。( java.util.Random 类也可以做到这点。)我们为 PseudoRandom 构建了两个实现;一个使用 syncronized,另一个使用 java.util.concurrent.ReentrantLock 。驱动程序生成了大量线程,每个线程都疯狂地争夺时间片,然后计算不同版本每秒能执行多少轮。图 1 和 图 2 总结了不同线程数量的结果。这个评测并不完美,而且只在两个系统上运行了(一个是双 Xeon 运行超线程 Linux,另一个是单处理器 Windows 系统),但是,应当足以表现 synchronized 与 ReentrantLock 相比所具有的伸缩性优势了。
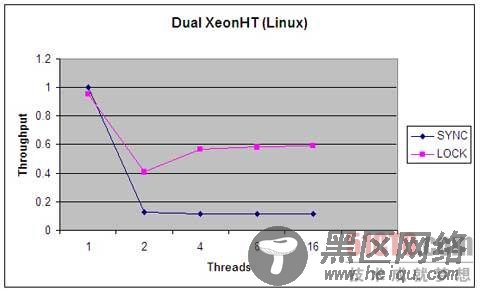
图 1. synchronized和Lock的吞吐率,单CPU

图 2. synchronized和Lock的吞吐率(标准化之后),4个 CPU
图1和图2中的图表以每秒调用数为单位显示了吞吐率,把不同的实现调整到 1 线程 synchronized 的情况。每个实现都相对迅速地集中在某个稳定状态的吞吐率上,该状态通常要求处理器得到充分利用,把大多数的处理器时间都花在处理实际工作(计算机随机数)上,只有小部分时间花在了线程调度开支上。您会注意到,synchronized 版本在处理任何类型的争用时,表现都相当差,而 Lock 版本在调度的开支上花的时间相当少,从而为更高的吞吐率留下空间,实现了更有效的 CPU 利用。