var express = require('express'); var app = express(); var request = require('request'); var cheerio = require('cheerio'); app.get('https://www.jb51.net/', function(req, res){ request('http://www.cnblogs.com', function (error, response, body) { if (!error && response.statusCode == 200) { //返回的body为抓到的网页的html内容 var $ = cheerio.load(body); //当前的$符相当于拿到了所有的body里面的选择器 var navText=$('.post_nav_block').html(); //拿到导航栏的内容 res.send(navText); } }) }); app.listen(3000);
我们抓到的内容都返回到了request的body里面。cherrio可以获取所有的dom选择器。假如我们要获取导航的内容:ul的class为:post_nav_block
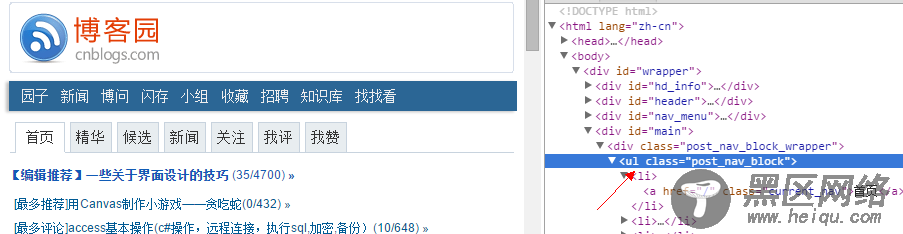
然后我们就可以将里面的内容显示出来了:
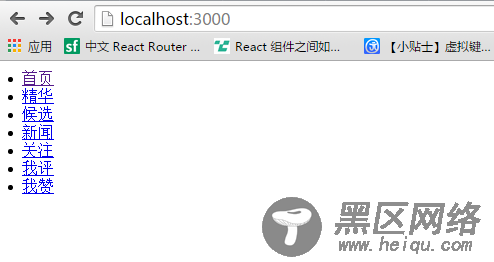
这个说明,我们的爬虫小程序就成功了。当然,这是一个简单的不能再简单的爬虫了。不过今天的文章就暂时介绍到这里,只是大概了解一下爬虫的过程而已。
接下来的第二篇文章会对这个爬虫进行升级,改版。比如异步啦,并发啦,定时去爬啦等等。
代码地址:https://github.com/xianyulaodi/mySpider
您可能感兴趣的文章: