
回写模式开启后,还会默认跳过对上传对象的大小检查,激进地尽量将所有数据都保留在 Cache 目录。这在一些会产生大量中间文件的场景(如软件编译等)特别有用。
此外,JuiceFS v0.17 版本还新增了 --upload-delay 参数,用来延缓数据上传到对象存储的时间,以更激进地方式将其缓存在本地。如果在等待的时间内数据被应用删除,则无需再上传到对象存储,既提升了性能也节省了成本。同时相较于本地硬盘而言,JuiceFS 提供了后端保障,在 Cache 目录容量不足时依然会自动将数据上传,确保在应用侧不会因此而感知到错误。这个功能在应对 Spark shuffle 等有临时存储需求的场景时非常有效。
读取流程JuiceFS 在处理读请求时,一般会按照 4 MiB Block 对齐的方式去对象存储读取,实现一定的预读功能。同时,读取到的数据会写入本地 Cache 目录,以备后用(如指标图中的第 2 阶段,blockcache 有很高的写入带宽)。显然,在顺序读时,这些提前获取的数据都会被后续的请求访问到,Cache 命中率非常高,因此也能充分发挥出对象存储的读取性能。此时数据在各个组件中的流动如下图所示:
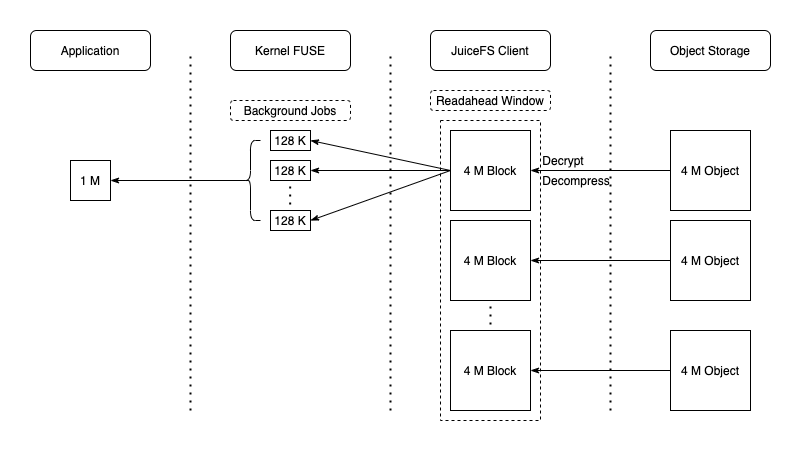
注意:读取的对象到达 JuiceFS Client 后会先解密再解压缩,与写入时相反。当然,如果未启用相关功能则对应流程会直接跳过。
做大文件内随机小 IO 读取时,JuiceFS 的这种策略则效率不高,反而会因为读放大和本地 Cache 的频繁写入与驱逐使得系统资源的实际利用率降低。不幸的是,此类场景下一般的缓存策略很难有足够高的收益。此时可考虑的一个方向是尽可能提升缓存的整体容量,以期达到能几乎完全缓存所需数据的效果;另一个方向则可以直接将缓存关闭(设置 --cache-size 0),并尽可能提高对象存储的读取性能。
小文件的读取则比较简单,通常就是在一次请求里读取完整个文件。由于小文件写入时会直接被缓存起来,因此类似 JuiceFS bench 这种写入后不久就读取的访问模式基本都会在本地 Cache 目录命中,性能非常可观。
总结以上就是本文所要简单阐述的 JuiceFS 读写请求处理流程相关的内容,由于大文件和小文件的特性差异,JuiceFS 通过对不同大小的文件执行不同的读写策略,从而大大的提升了整体性能和可用性,可以更好的满足用户对不同场景的需求。