
一个典型的ELF文件格式如下图所示,文件有两种视角:编译视角,以section头部表为核心组织程序;运行视角,程序头部表以segment为核心组织程序。这么做主要是为了节约存储,很多细碎的section在运行时由于对齐要求会导致很大的内存浪费,运行时通常会将权限类似的section组织成segment一起加载。

通过命令objdump和readelf可以查看ELF文件的内容。
对可重定位目标文件常见的section有:
链接器会为对外部符号的引用修改为正确的被引用符号的地址,当无法为引用的外部符号找到对应的定义时,链接器会报undefined reference to XXXX的错误。另外一种情况是,找到了多个符号的定义,这种情况链接器有一套规则。在描述规则前需要了解强符号和弱符号的概念,简单讲函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
针对符号的多重定义链接器处理规则如下(作者在gcc 7.3.0上貌似规则2,3都按1处理):
1. 不允许多个强符号定义,链接器会报告重复定义貌似的错误
2. 如果一个强符号和多个弱符号同名,则选择强符号
3. 如果符号在所有目标文件中都为弱符号,那么选择占用空间最大的一个
有了这些基础,我们先来看一下静态链接过程:
1. 链接器从左到右按照命令行出现顺序扫描目标文件和静态库
2. 链接器维护一个目标文件的集合E,一个未解析符号集合U,以及E中已定义的符号集合D,初始状态E、U、D都为空
3. 对命令行上每个文件f,链接器会判断f是否是一个目标文件还是静态库,如果是目标文件,则f加入到E,f中未定义的符号加入到U中,已定义符号加入到D中,继续下一文件
4. 如果是静态库,链接器尝试到静态库目标文件中匹配U中未定义的符号,如果m中匹配U中的一个符号,那么m就和上步中文件f一样处理,对每个成员文件都依次处理,直到U、D无变化,不包含在E中的成员文件简单丢弃
5. 所有输入文件处理完后,如果U中还有符号,则出错,否则链接正常,输出可执行文件
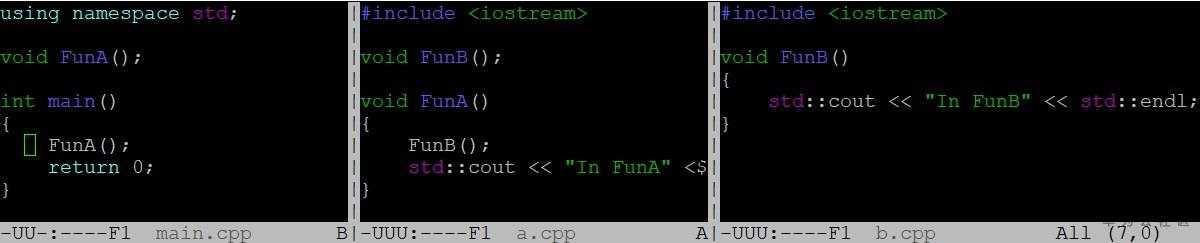
问题二:静态库顺序如下图所示,main.cpp依赖liba.a,liba.a又依赖libb.a,根据静态链接算法,如果用g++ main.cpp liba.a libb.a的顺序能正常链接,因为解析liba.a时未定义符号FunB会加入到上述算法的U中,然后在libb.a中找到定义,如果用g++ main.cpp libb.a liba.a的顺序编译,则无法找到FunB的定义,因为根据静态链接算法,在解析libb.a的时候U为空,所以不需要做任何解析,简单抛弃libb.a,但在解析liba.a的时候又发现FunB没有定义,导致U最终不为空,链接错误,因此在做静态链接时,需要特别注意库的顺序安排,引用别的库的静态库需要放在前面,碰到链接很多库的时候,可能需要做一些库的调整,从而使依赖关系更清晰。
之前大部分内容都是静态链接相关,但静态链接有很多不足:不利于更新,只要有一个库有变动,都需要重新编译;不利于共享,每个可执行程序都单独保留一份,对内存和磁盘是极大的浪费。
要生成动态链接库需要用到参数“-shared -fPIC”表示要生成位置无关PIC(Position Independent Code)的共享目标文件。对静态链接,在生成可执行目标文件时整个链接过程就完成了,但要想实现动态链接的效果,就需要把程序按照模块拆分成相对独立的部分,在程序运行时将他们链接成一个完整的程序,同时为了实现代码在不同程序间共享要保证代码是和位置无关的(因为共享目标文件在每个程序中被加载的虚拟地址都不一样,要保证它不管被加载在哪都能工作),而为了实现位置无关又依赖一个前提:数据段和代码段的距离总是保持不变。