自定义 BeanDefinitionParser 实现:绑定命名空间下不同的 XML 元素与其对应的解析器,因为一个命名空间下可以有很多个标签,对于不同的标签需要不同的 BeanDefinitionParser 解析器,在上面的 init() 方法中进行绑定
注册 XML 扩展(META-INF/spring.handlers 文件):命名空间与命名空间处理器的映射
XML Schema 文件通常定义为网络的形式,在无网的情况下无法访问,所以一般在本地的也有一个 XSD 文件,可通过编写 META-INF/spring.schemas 文件,将网络形式的 XSD 文件与本地的 XSD 文件进行映射,这样会优先从本地获取对应的 XSD 文件
关于上面的实现步骤的原理本文进行了比较详细的分析,稍微总结一下:
Spring 会扫描到所有的 META-INF/spring.schemas 文件内容,每个命名空间对应的 XSD 文件优先从本地获取,用于 XML 文件的校验
Spring 会扫描到所有的 META-INF/spring.handlers 文件内容,可以找到命名空间对应的 NamespaceHandler 处理器
根据找到的 NamespaceHandler 处理器找到标签对应的 BeanDefinitionParser 解析器
根据 BeanDefinitionParser 解析器解析该元素,生成对应的 BeanDefinition 并注册
本文还分析了 <context:component-scan /> 的实现原理,底层会 ClassPathBeanDefinitionScanner 扫描器,用于扫描指定路径下符合条件的 BeanDefinition 们(带有 @Component 注解或其派生注解的 Class 类)。@ComponentScan 注解底层原理也是基于 ClassPathBeanDefinitionScanner 扫描器实现的,这个扫描器和解析 @Component 注解定义的 Bean 相关。有关于面向注解定义的 Bean 在 Spring 中是如何解析成 BeanDefinition 在后续文章进行分析。
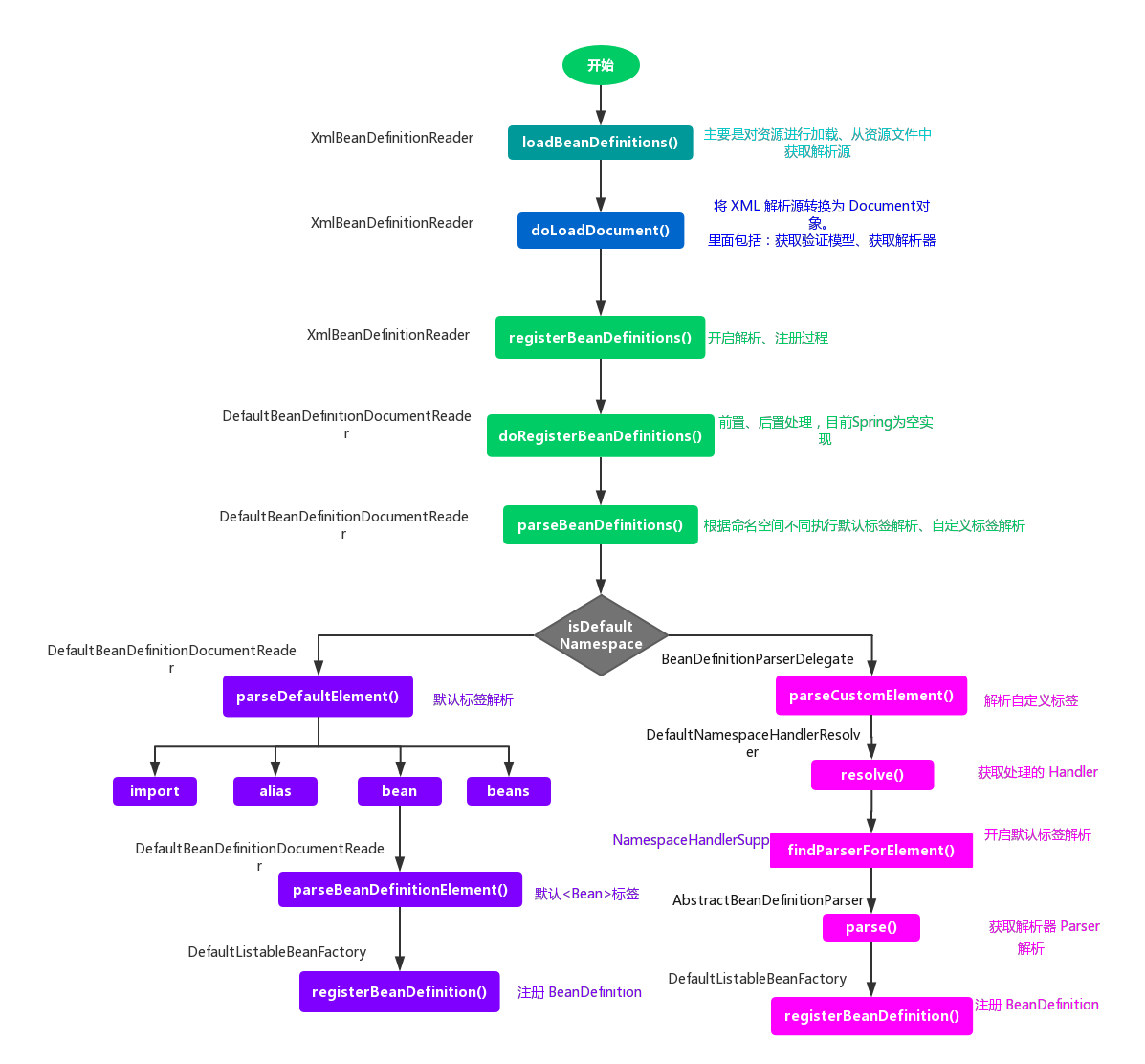
最后用一张图来结束面向资源(XML)定义 Bean 的 BeanDefinition 的解析过程: