
对于超出范围的任务可放在一个缓冲区中(可用队列、redis或数据库实现),等最高时间轮转到下一格子就从缓冲中取出符合范围的任务落到时间轮中。
比如:
添加一个600s后执行的任务A
算出该任务的延迟时间已经溢出时间轮
所以任务被保存到缓冲队列中
在时钟轮走了1格之后,会从缓冲队列中取满足范围的任务落到时间轮中
缓冲队列中的所有任务延迟时间均需减去64s,任务A减去64s后是536s,依然大于时间轮范围,所以不会被移出队列
在时钟轮又走了1格之后,任务A减去64s是536-64=472s,在时间轮范围内,会被落入时钟轮
之前的设计(DB/DelayQueue/ZooKeeper)
调度系统提供任务操作接口供业务系统提交任务、取消任务、反馈执行结果等。
针对dubbo调用,将任务抽象成JobCallbackService接口,由业务系统实现并注册成服务。
整体架构
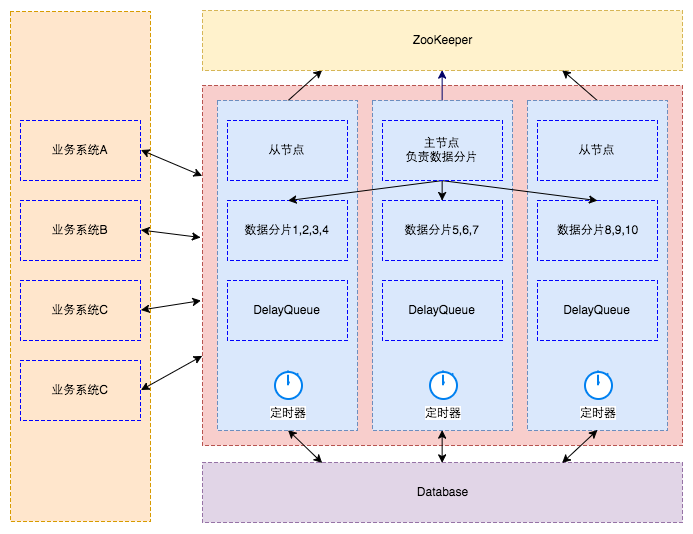
数据库:
负责保存所有的任务数据
内存队列:
实际为DelayQueue,延迟任务精确触发的机制由它保证
只存储未来N分钟内过期且最多1000个任务
ZooKeeper:
管理整个调度集群
存储调度节点信息
存储节点分片信息
主节点:
有新的节点上下线时对数据重新分片
调度节点:
提供dubbo、http接口供业务系统调用,用于提交任务、取消任务、反馈执行结果等
从ZK注册中心获取当前节点的分片信息,再从数据库拉取即将过期的数据放到DelayQueue
调用业务系统注册的回调服务接口,发起调度请求
接收业务系统的反馈结果,更新执行结果,移除任务或发起重试
业务系统:
作为被调度的服务需要实现回调接口JobCallbackService,并注册为dubbo服务提供者
在需要延迟任务的场景调用调度系统接口操作任务
数据库设计
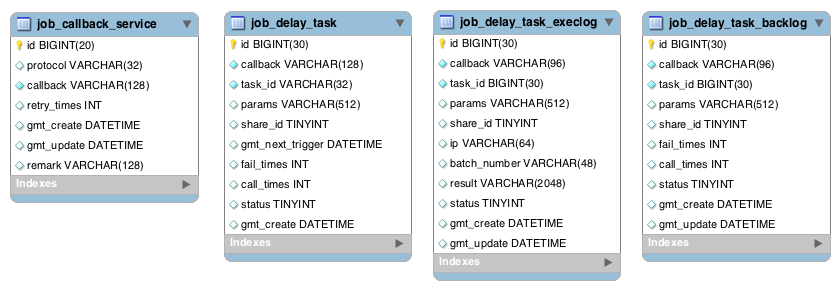
表说明
job_callback_service:服务配置表,配置业务回调服务,包括服务协议、回调服务、重试次数
job_delay_task:延迟任务表,用于存储延迟任务,包括任务分片号、回调服务、调用总次数、失败数、任务状态、回调参数等
job_delay_task_execlog:延迟任务执行表,记录调度系统发起的每一次回调
job_delay_task_backlog:延迟任务调度结果表,记录任务最终状态等信息
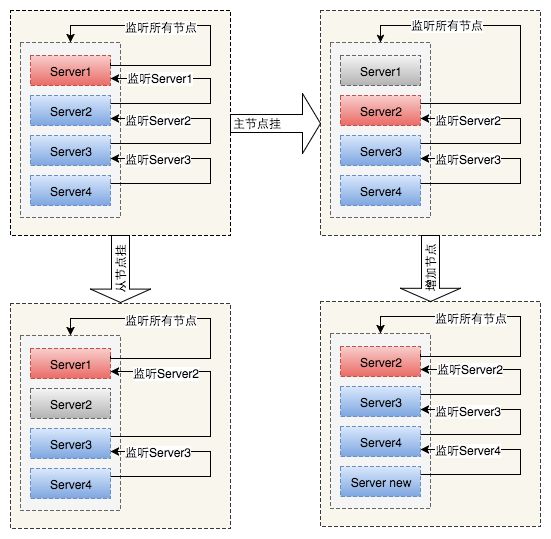
主从切换
利用ZooKeeper临时序列节点特性,序号最小的节点为主节点,其他节点为从节点。
主节点监听集群状态,集群状态发生变化时重新分片。
从节点监听序号比它小的兄弟节点,兄弟节点发生变化重新寻找和建立监听关系。
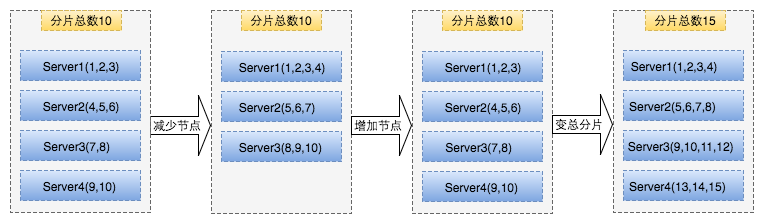
数据分片
任务状态
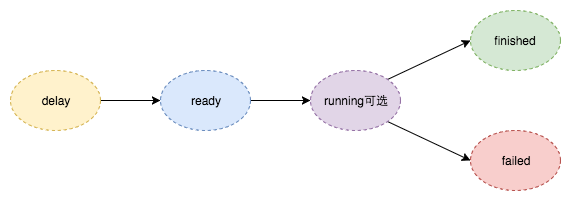
delay:延迟任务提交后的初始状态
ready:过期时间已到,消息推入就绪队列的状态
running:业务订阅消息,收到消息开始处理的状态
finished:业务处理成功
failed:业务处理失败
主要流程