
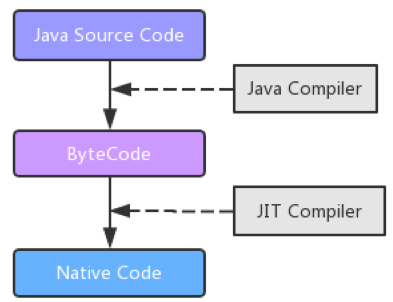
执行引擎执行包在装载类的方法中的指令,也就是方法。执行引擎以指令为单位读取Java字节码。它就像一个CPU一样,一条一条地执行机器指令。每个字节码指令都由一个1字节的操作码和附加的操作数组成。执行引擎取得一个操作码,然后根据操作数来执行任务,完成后就继续执行下一条操作码。
不过Java字节码是用一种人类可以读懂的语言编写的,而不是用机器可以直接执行的语言。因此,执行引擎必须把字节码转换成可以直接被JVM执行的语言。字节码可以通过以下两种方式转换成合适的语言:
解释器: 一条一条地读取,解释并执行字节码执行,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行语言的一个缺点。
即时编译器:用来弥补解释器的缺点,执行引擎首先按照解释执行的方式来执行,然后在合适的时候,即时编译器把整段字节码编译成本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行。执行本地代码比一条一条进行解释执行的速度快很多,编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
垃圾收集即垃圾回收,简单的说垃圾回收就是回收内存中不再使用的对象。所谓使用中的对象(已引用对象),指的是程序中有指针指向的对象;而未使用中的对象(未引用对象),则没有被任何指针给指向,因此占用的内存也可以被回收掉。
垃圾回收的基本步骤分两步:
查找内存中不再使用的对象(GC判断策略)
释放这些对象占用的内存(GC收集算法)
3.4.2 GC判断策略1) 引用计数算法
引用计数算法是给对象添加一个引用计数器,每当有一个引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器都为0的对象就是不可能再被使用的对象。缺点:很难解决对象之间相互循环引用的问题。
2) 根搜索算法
根搜索算法的基本思路就是通过一系列名为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(也就是说从GC Roots到这个对象不可达)时,则证明此对象是不可用的。
在Java语言里,可作为GC Roots的对象包括以下几种:
虚拟机栈(栈帧中的本地变量表)中引用的对象;
方法区中类静态属性引用的对象;
方法区中常量应用的对象;
本地方法栈中JNI(Native方法)引用的对象。
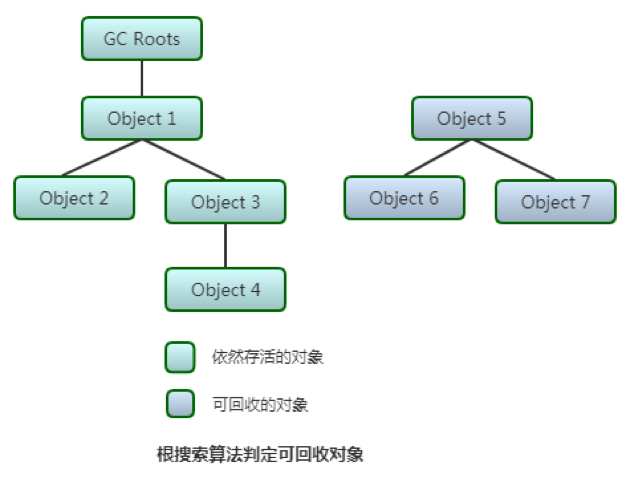
注:在根搜索算法中不可达的对象,也并非是“非死不可”的,因为要真正宣告一个对象死亡,至少要经历两次标记过程:第一次是标记没有与GC Roots相连接的引用链;第二次是GC对在F-Queue执行队列中的对象进行的小规模标记(对象需要覆盖finalize()方法且没被调用过)。
3.4.3 GC收集算法1) 标记-清除算法(Mark-Sweep)
标记-清楚算法采用从根集合(GC Roots)进行扫描,首先标记出所有需要回收的对象(根搜索算法),标记完成后统一回收掉所有被标记的对象。
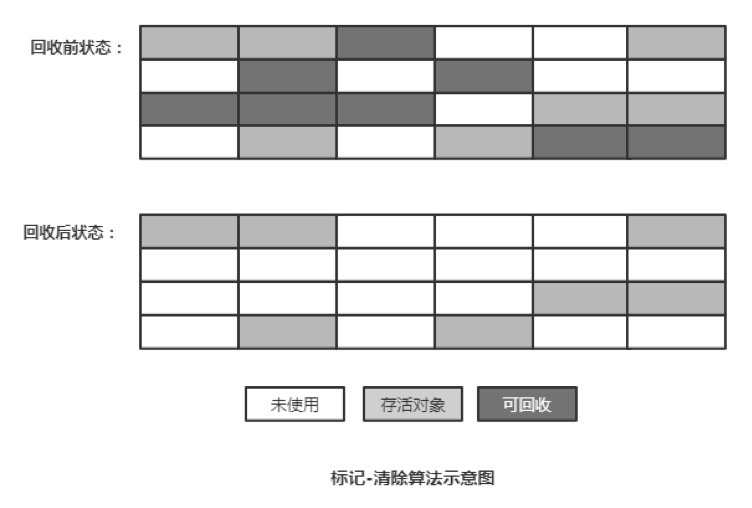
该算法有两个问题:
效率问题:标记和清除过程的效率都不高;
空间问题:标记清除后会产生大量不连续的内存碎片, 空间碎片太多可能会导致在运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集。
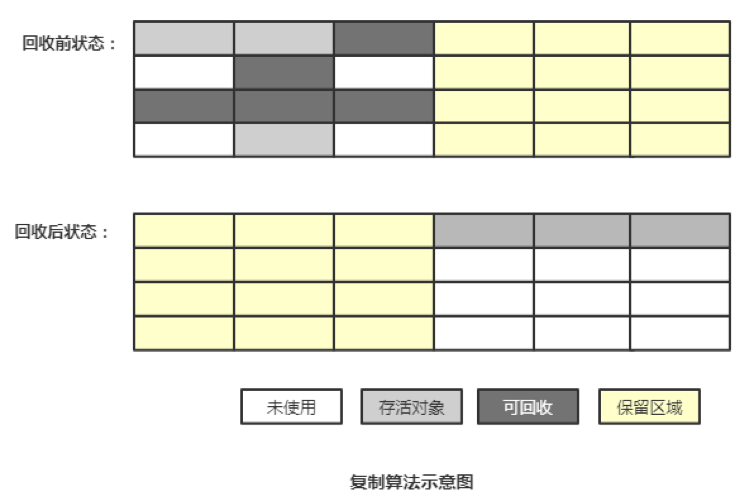
2) 复制算法(Copying)
复制算法是将可用内存按容量划分为大小相等的两块, 每次只用其中一块, 当这一块的内存用完, 就将还存活的对象复制到另外一块上面, 然后把已使用过的内存空间一次清理掉。
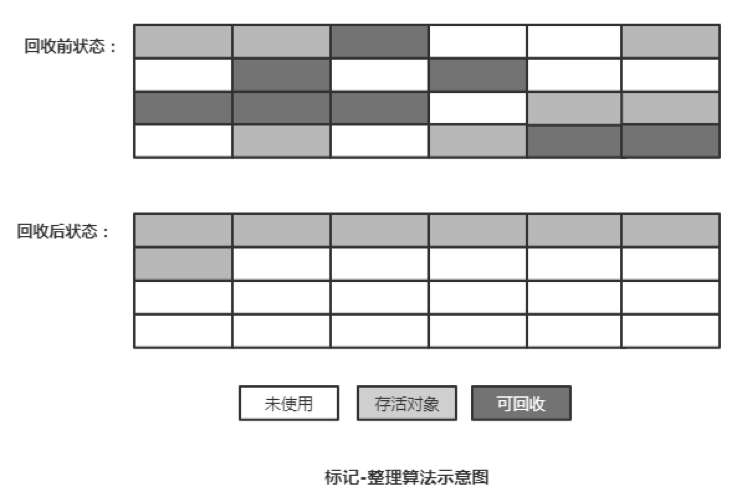
3) 标记-整理算法(Mark-Compact)
标记整理算法的标记过程与标记清除算法相同, 但后续步骤不再对可回收对象直接清理, 而是让所有存活的对象都向一端移动,然后清理掉端边界以外的内存。
4) 分代收集算法(Generational Collection)