
由于集群环境下,数据的存储位置是根据Key来计算而来的(这里牵涉到一致性哈希算法),使得数据可以均匀分配到各节点上,所以在redis-cli连接的时候需要指定集群模式,如下:

如上图所示,指定集群模式之后就可以正常存取了;
故障演示
既然集群环境,肯定少不了要好好测测;
模拟从节点挂掉
找个从节点停掉试试,这里停掉6371节点,根据创建集群信息知道,它的主节点是6390;
主节点显示从节点断开连接,看看它的主节点反应:

其他集群节点只是将从节点标记为failing状态,即下线状态,如下:

对于存取数据也不受影响,这里就不截图了,小伙伴自行尝试吧;
当故障的从节点6371重新连上时,主节点恢复主从关系,并进行主从复制操作;其他集群节点会清除原来标记的下线状态,将其改为上线;
模拟主节点挂掉
这里就手动将6390这个节点停掉,会有怎样的反应呢?
自身从节点会每隔一秒检测连接,如果超时(默认是15秒),会选举从节点做为集群的主节点来提供服务,如下图:
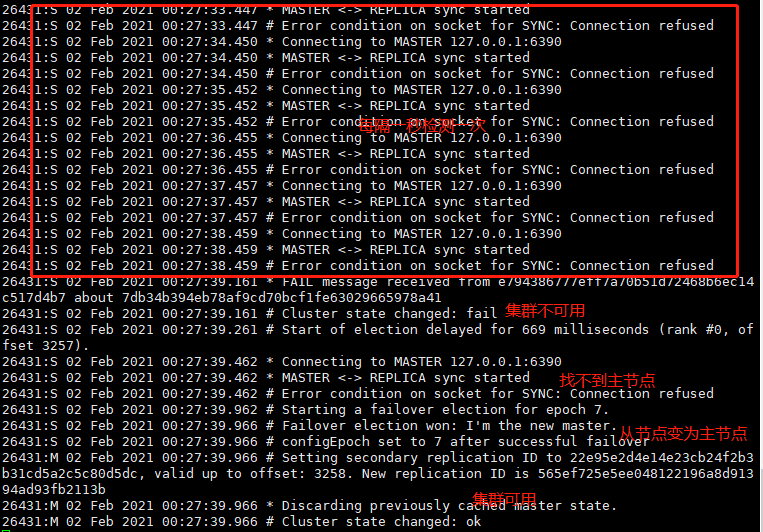
数据存取最终还是不受影响;
对于其他集群节点,将故障节点标记为failing,让新上任的主节点提供服务,如下图:

存取数据也是不受影响的;
挂掉的主节点6390如果恢复,那它只能变为6371的从节点啦,并进行相关主从复制操作;而集群的其他节点只是将其原有的Fail状态清除,表示可以正常连接;
Redis集群就是这样简单,只要思路对,就是手工活;小伙伴可以编写脚本自动执行哦;
接下来说说集群数据的存储;
数据存储简单分析在Redis集群环境中,数据的存储位置是根据对Key的Hash计算进行指定的; Redis集群为了在节点改变时保证数据分布均匀,引入了槽(slot)作为迁移的基本单位,槽解耦了数据和实际节点的关系,使得实际节点数的改变对系统影响较小;
在整个集群中,槽(slot)总共有16384,会将其均匀分配到集群的主节点上,其中每一份槽对应一个存储空间(这里的存储空间可以理解为一个容器,是可以存很多数据的),以上集群环境的槽分配如下:
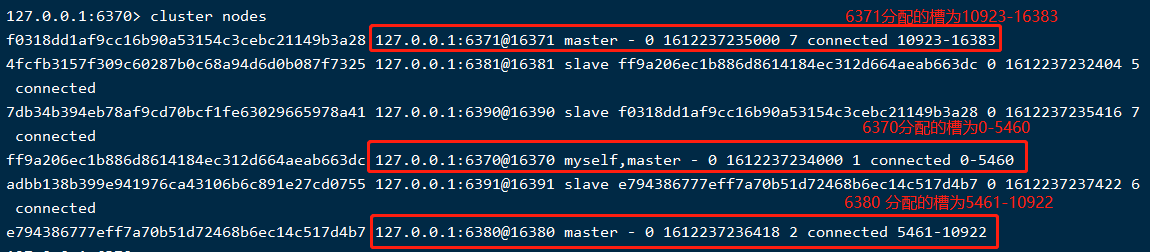
存储数据的过程,如下:
连接6380主节点,执行如下操作:

具体过程如下:
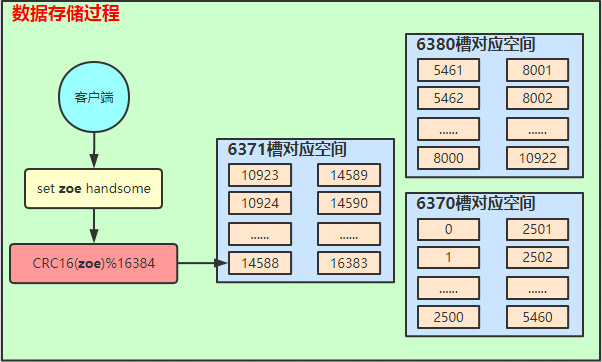
简要说明:
客户端发起命令;
服务器将Key进行CRC16计算,并与总槽位计算出Key需要存储的位置;
这里模拟的Key为zoe,计算出的槽位为14588,不在6380这个节点上,集群节点会将其重定向到对应槽位的节点上;
然后找到6371上的14588槽位进行数据存储;(注,这里的6371已经是主节点了,因为上面做过一次故障转移模拟);
那集群节点是如何知道其他节点的槽范围和其他信息呢?