需要注意的是,上面的函数并没有返回值,这是因为我们装载心拍数据和样本的列表X_data、Y_data包含了所有心电记录中符合要求的心拍,需要从函数外传入,并将得到的数据直接附加在列表末尾。这样将心电信号的编号、X_data、Y_data一同传入,就能将所需数据保存在X_data和Y_data中。
下面将所有心拍信号(因为102和104没有MLII导联故去除)读取到dataSet和lableSet两个列表中,经过上面函数后,dataSet和lableSet都是一个(92192)的一维列表。其中dataSet中的每一个元素都是一个numpy的数组,数组中是一个元素都是一个心拍的300个信号点,lableSet中的每一个元素是dataSet中一个数组对应的标签值(NAVLR对应01234)。reshape后将dataSet变为(92192,300)的列表,将lableSet变为(92192,1)的列表。然后对这两个列表进行乱序处理,但是要保证二者之间的对应关系不改变。思路是先将两个列表进行竖直方向的堆叠,变为一个列表train_ds,然后对其进行乱序处理,再拆分出乱序后的数据X和标签Y。
由于tf.keras可以将输入的数据集自动划分成训练集和测试集,所以只需要分出测试集即可。思路是先生成92192(总心拍个数)个数的随机排列列表,然后截取其中前30%个值作为索引,然后在数据集和标签集中取出下标为这些索引的值,即得到测试数据集X_test和测试标签集Y_test。
# 加载数据集并进行预处理 def loadData(): numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115', '116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208', '210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230', '231', '232', '233', '234'] dataSet = [] lableSet = [] for n in numberSet: getDataSet(n, dataSet, lableSet) # 转numpy数组,打乱顺序 dataSet = np.array(dataSet).reshape(-1, 300) lableSet = np.array(lableSet).reshape(-1, 1) train_ds = np.hstack((dataSet, lableSet)) np.random.shuffle(train_ds) # 数据集及其标签集 X = train_ds[:, :300].reshape(-1, 300, 1) Y = train_ds[:, 300] # 测试集及其标签集 shuffle_index = np.random.permutation(len(X)) test_length = int(RATIO * len(shuffle_index)) # RATIO = 0.3 test_index = shuffle_index[:test_length] X_test, Y_test = X[test_index], Y[test_index] return X, Y, X_test, Y_test经过上面的函数后,X,Y为总体数据集和标签集,X_test,Y_test为测试数据集和标签集,验证数据集和测试集使用tf.keras接口自动划分。这样用于深度学习的数据集就已经构建好了。
深度学习识别分类通常来说,深度学习神经网络的训练过程编程较为复杂,但是我们这里使用tf.keras高级接口,可以很方便地进行深度学习网络模型的构建。
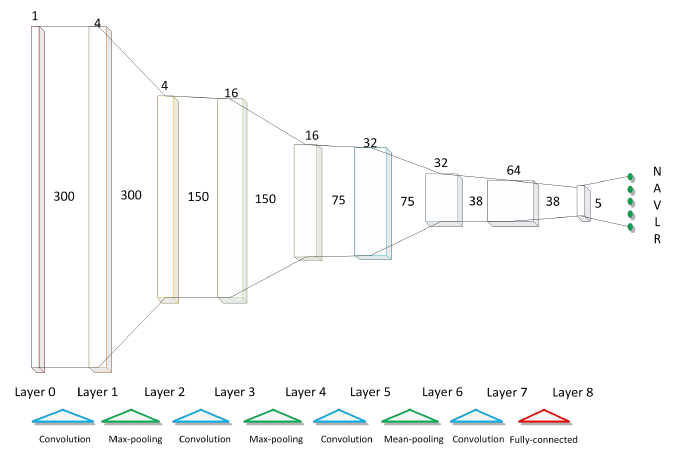
首先我们构建网络结构,具体结构如下图所示:
# 构建CNN模型 def buildModel(): newModel = tf.keras.models.Sequential([ tf.keras.layers.InputLayer(input_shape=(300, 1)), # 第一个卷积层, 4 个 21x1 卷积核 tf.keras.layers.Conv1D(filters=4, kernel_size=21, strides=1, padding='SAME', activation='relu'), # 第一个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2 tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'), # 第二个卷积层, 16 个 23x1 卷积核 tf.keras.layers.Conv1D(filters=16, kernel_size=23, strides=1, padding='SAME', activation='relu'), # 第二个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2 tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'), # 第三个卷积层, 32 个 25x1 卷积核 tf.keras.layers.Conv1D(filters=32, kernel_size=25, strides=1, padding='SAME', activation='relu'), # 第三个池化层, 平均池化,4 个 3x1 卷积核, 步长为 2 tf.keras.layers.AvgPool1D(pool_size=3, strides=2, padding='SAME'), # 第四个卷积层, 64 个 27x1 卷积核 tf.keras.layers.Conv1D(filters=64, kernel_size=27, strides=1, padding='SAME', activation='relu'), # 打平层,方便全连接层处理 tf.keras.layers.Flatten(), # 全连接层,128 个节点 tf.keras.layers.Dense(128, activation='relu'), # Dropout层,dropout = 0.2 tf.keras.layers.Dropout(rate=0.2), # 全连接层,5 个节点 tf.keras.layers.Dense(5, activation='softmax') ]) return newModel