
但是,这个地方的区别在于参与者有了超时机制,如果参与者超时未收到doCommit命令的话,将会默认去提交事务。
DoCommit
DoCommit阶段对应到2PC的执行阶段,如果上一个阶段都是收到YES的话,那么就发送doCommit命令去提交事务,反之则会发送abort命令去中断事务的执行。
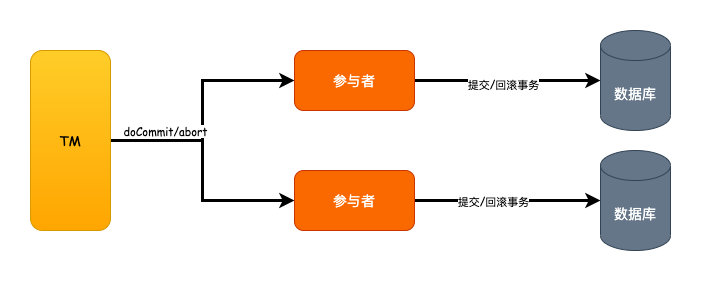
相比2PC的改进
对于2PC的同步阻塞的问题,我们可以看到因为3PC加入了参与者的超时机制,所以原来2PC的如果某个参与者故障导致的同步阻塞的问题时间缩短了,这是一个优化,但是并没有完全避免。
第二个单点故障的问题,同样因为超时机制的引入,一定程度上也算是优化了。
但是数据不一致的问题,这个始终没有得到解决。
举个栗子:
在PreCommit阶段,某个参与者发生脑裂,无法收到TM的请求,这时候其他参与者执行abort事务回滚,而脑裂的参与者超时之后继续提交事务,还是有可能发生数据不一致的问题。
那么,为什么要加入DoCommit这个阶段呢?就是为了引入超时机制,事先我们先确认数据库是否都可以执行事务,如果都OK,那么才会进入后面的步骤,所以既然都可以执行,那么超时之后说明发生了问题,就自动提交事务。
TCC
TCC的模式叫做Try、Confirm、Cancel,实际上也就是2PC的一个变种而已。
实现这个模式,一个事务的接口需要拆分成3个,也就是Try预占、Confirm确认提交、最后Cancel回滚。
对于TCC来说,实际生产我基本上就没看见过有人用,考虑到原因,首先是程序员的本身素质参差不齐,多个团队协作你很难去约束别人按照你的规则来实现,另外一点就是太过于复杂。
如果说有简单的应用的话,库存的应用或许可以算做是一个。
一般库存的操作,很多实现方案里面都会会在下单的时候先预占库存,下单成功之后再实际去扣减库存,最终如果发生了异常再回退。
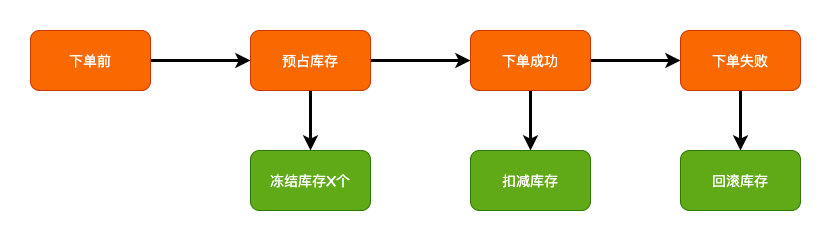
冻结、预占库存就是2PC的准备阶段,真正下单成功去扣减库存就是2PC的提交阶段,回滚就是某个发生异常的回滚操作,只不过在应用层面来实现了2PC的机制而已。
SAGA
Saga源于1987 年普林斯顿大学的 Hecto 和 Kenneth 发表的如何处理 long lived transaction(长活事务)论文。
主要思想就是将长事务拆分成多个本地短事务。
如果全部执行成功,就正常完成了,反之,则会按照相反的顺序依次调用补偿。
SAGA模式有两种恢复策略:
向前恢复,这个模式偏向于一定要成功的场景,失败则会进行重试
向后恢复,也就是发生异常的子事务依次回滚补偿
由于这个模式在国内基本没看见有谁用的,不在赘述。
消息队列
基于消息队列来实现最终一致性的方案,这个相比前面的我个人认为还稍微靠谱一点,那些都是理论啊,正常生产的实现很少看见应用。
基于消息队列的可能真正在应用的还稍微多一点。
一般来说有两种方式,基于本地消息表和依赖MQ本身的事务消息。
本地消息表的这个方案其实更复杂,实际上我也没看到过真正谁来用。这里我以RocketMQ的事务消息来举例,这个方式相比本地消息表则更完全依赖MQ本身的特性做了解耦,释放了业务开发的复杂工作量。
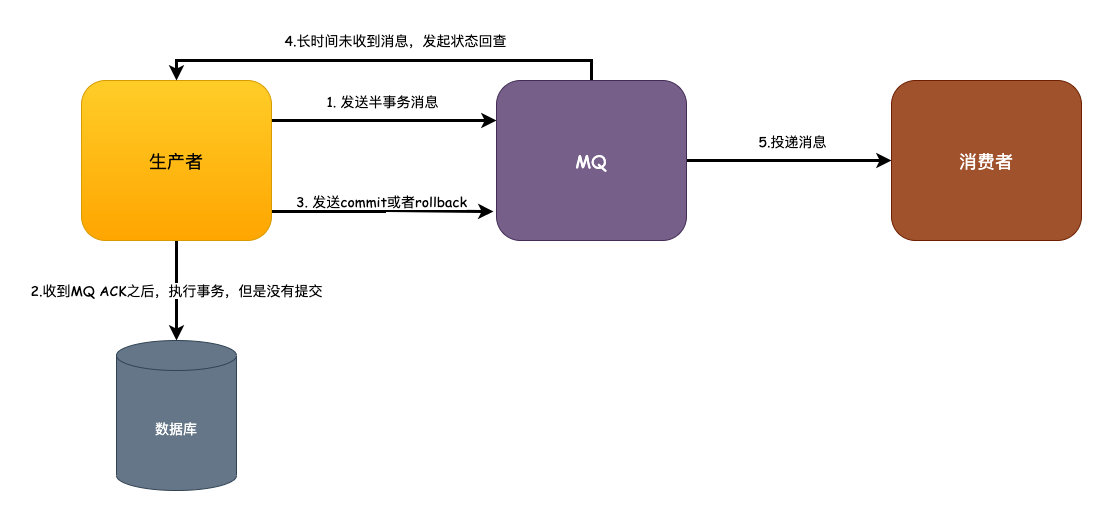
业务发起方,调用远程接口,向MQ发送一条半事务消息,MQ收到消息之后会返回给生产者一个ACK
生产者收到ACK之后,去执行事务,但是事务还没有提交。
生产者会根据事务的执行结果来决定发送commit提交或者rollback回滚到MQ
这一点是发生异常的情况,比如生产者宕机或者其他异常导致MQ长时间没有收到commit或者rollback的消息,这时候MQ会发起状态回查。
MQ如果收到的是commit的话就会去投递消息,消费者正常消费消息即可。如果是rollback的话,则会在设置的固定时间期限内去删除消息。