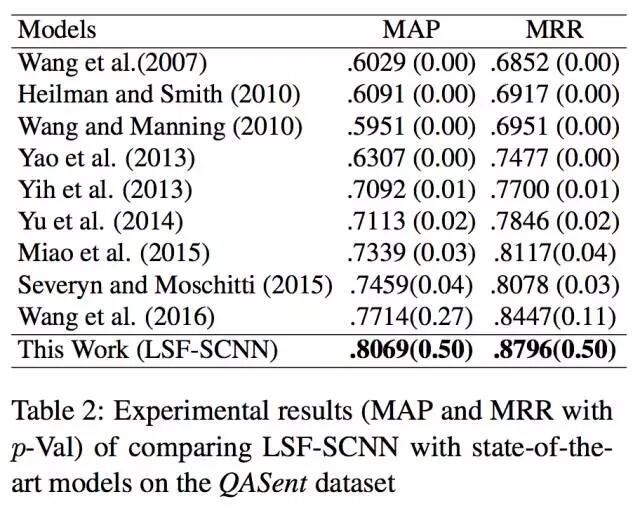
LSF特征怎样计算得到?
问题和答案中的每一个单词都会有一个LSF特征,具体来说是一个[0,t]上的整数值。LSF的计算过程可通过下面一个例子说明,当我们想要求解问题中general一词的LSF特征时,第一步我们需要计算general与答案中每一个词的余弦相似度并选取其中的最大值,因此chief被选取出来。第二步,余弦相似度值的最大值0.79将通过一个映射函数映射为一个[0,t]区间的整数,当我们假定t=10,最终计算得到general的LSF特征为3。这是合理的,general和chief一定程度上是近义词。
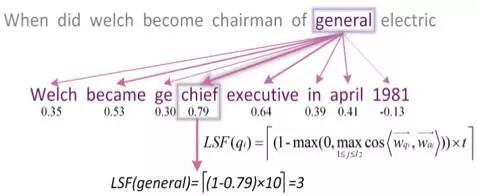
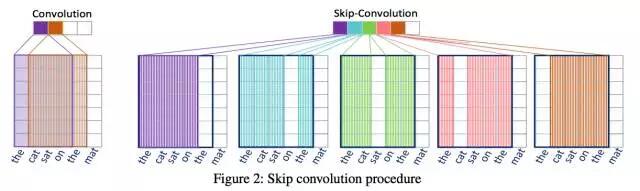
SC技术核心想法: 在短语粒度上,我们提出跳跃卷积SC技术。下图展示了以the cat sat on the mat为例,设定卷积窗口长度为4时,且步长为1跳跃一次,跳跃卷积方式在传统卷积方式上的改进:
传统卷积方式将取得如下短语特征:{the cat sat on, cat sat on the, sat on the mat}
跳跃卷积将取得如下短语特征{the cat sat on, the cat sat the, the cat on the, the sat on the, cat sat on the, cat sat on mat, cat sat the mat, cat on the mat, sat on the mat }。
SC的技术实现:
如上图所示,左侧传统卷积方式将卷积窗口作为一个整体,自左向右每次移动一个单词的步长进行卷积操作。相比而言,跳跃卷积则是同样自左向右每次移动一个单词的步长,但移动的并非卷积窗口的整体,而是整体中的一列。例如,上图右侧,初始卷积抽取了短语“the cat sat on”(紫色框)的特征;而后将覆盖在“on”上的卷积窗口的那一列向右移动一个单词的步长,从而得到短语“the cat sat the”(蓝色框)的特征;接着,将覆盖在“sat”上的一列向右移动一个单词的步长,从而得到短语“the cat on the”(绿色框)的特征,以此类推。
SC技术可行性分析:
传统卷积方式只允许在特定大小的卷积窗口中对相邻的词语进行卷积,而跳跃卷积可以通过跳跃停用词如the、形容词等,在特定大小的卷积窗口中将抽取到包含更完整更浓缩的主体语义信息的短语特征如‘cat sat on mat’,从而提升了短语粒度上特征的丰富性。虽然,跳跃卷积相比于传统卷积方式,也会额外抽取到许多无用的短语的特征。但实验结果证明,跳跃卷积技术对增加短语特征丰富性的帮助,要大于额外增加的无用短语特征带来的噪音的影响。
SC技术实现可以参考[8]。Lei的文章应用于情感分类 (sentiment classification) 和新闻分类 (news categorization) 任务,而本文应用于答案选择任务。
4.3 K-Max均值采样技术(K-Max Average Pooling,KMA)
K-Max均值采样提出的背景:
卷积神经网络中的池化层,也称采样层,主流有两种方法:最大值采样 (max pooling) 和均值采样 (average pooling)。但上述两种方法也存在一定的局限性,由此,Zeiler and Fergus[9]提出了对于最大值采样的一些改进技术,Kalchbrenner[10]提出了动态k-max采样技术。
K-Max均值采样的核心思想:
本文提出的K-max均值采样技术结合了最大值采样和均值采样。具体而言,对于卷积层传入的特征矩阵
(feature map),K-Max采样技术选取其中最大的前K个值,并取其平均值作为最终的采样结果。K-Max均值采样的好处,一方面可以减少异常噪音点的影响,另一方面可以保留表现比较强的特征的强度。虽然想法简单,但实验证明对模型的提升效果较好。
本文在两个公认标准数据集QASent和WikiQA设计全面的实验。下图展示了两个数据集的一些统计信息。
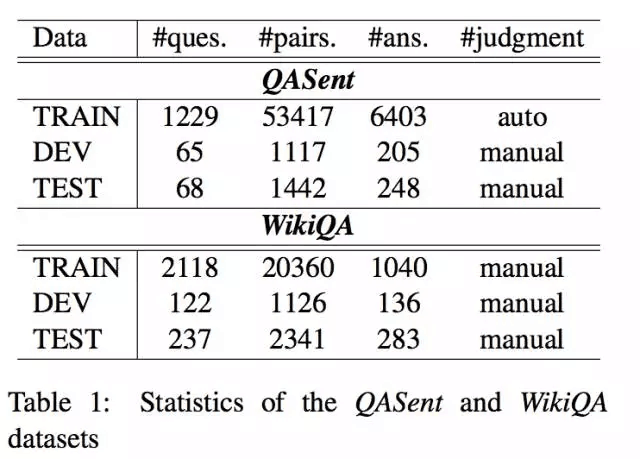
两个数据集有以下两方面区别:
QASent候选答案从文档库中抽取出来,而WikiQA候选答案来自Bing日志(被查询的问题所返回的链接列表,筛选出被五个不相同的用户点击过的链接,并从选中链接的摘要中抽取答案),因此WikiQA更加真实、更能反映用户的真实查询意图。
QASent候选答案要求至少与问题有一个非停用单词,而WikiQA中20.3%的答案与问题不存在相同单词,因此WikiQA对LSF技术提出了更高的挑战。
5.2 实验结果:下面两个表格分别展示了LSF-SCNN模型与前人方法在QASent和WikiQA两个数据集上的效果对比,由此可见,LSF-SCNN模型相比于当前最好的方法,在MAP和MRR两个指标上,对QASent数据集提升了3.5%,对WikiQA数据集提升了1.2%。答案选择问题的baseline比较高,所以LSF-SCNN的提升效果还是非常显著的。