
CNN后接2层LSTM,每个LSTM层采用832个cells,512维映射层来降维。输出状态标签延迟5帧,此时DNN输出信息可以更好的预测当前帧。由于CNN的输入特征向左扩展了l帧向右扩展了r帧,为了确保LSTM不会看到未来多于5帧的内容,作者将r设为0。最后,在频域和时域建模之后,将LSTM的输出连接几层全连接DNN层。
借鉴了图像领域CNN的应用,作者也尝试了长短时特征,将CNN的输入特征作为短时特征直接输入给LSTM作为部分输入,CNN的输出特征直接作为DNN的部分输入特征。
2.2 实验结果针对CLDNN结构,我们用自己的中文数据做了一系列实验。实验数据为300h的中文有噪声语音,所有模型输入特征都为40维fbank特征,帧率10ms。模型训练采用交叉熵CE准则,网络输出为2w多个state。由于CNN的输入需要设置l和r两个参数,r设为0,l经过实验10为最优解,后面的实验结果中默认l=10,r=0。
其中LSTM为3层1024个cells,project为512 ,CNN+LSTM和CNN+LSTM+DNN具体的网络参数略有调整,具体如下图,另外还增加一组实验,两层CNN和三层LSTM组合,实验验证增加一层LSTM对结果有提高,但继续增加LSTM的层数对结果没有帮助。
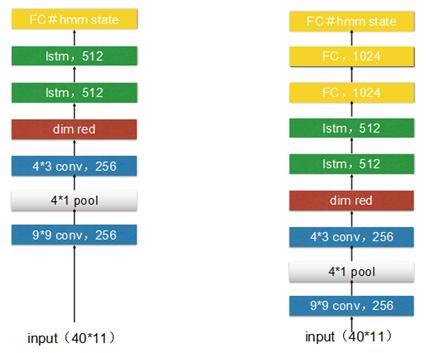
Fig 2. CLDNN实验结构
method WERLSTM 13.8
CNN+2层LSTM 14.1
CNN+3层LSTM 13.6
CNN+LSTM+DNN 13.0
LSTM+DNN 13.2
Table 1 测试集1结果
method WERLSTM 21.6
CNN+2层LSTM 21.8
CNN+3层LSTM 21.5
CNN+LSTM+DNN 20.6
LSTM+DNN 20.8
Table 2 测试集2结果
3 deep CNN在过去的一年中,语音识别取得了很大的突破。IBM、微软、百度等多家机构相继推出了自己的Deep CNN模型,提升了语音识别的准确率。Residual/Highway网络的提出使我们可以把神经网络训练的更深。尝试Deep CNN的过程中,大致也分为两种策略:一种是HMM 框架中基于 Deep CNN结构的声学模型,CNN可以是VGG、Residual 连接的 CNN 网络结构、或是CLDNN结构。另一种是近两年非常火的端到端结构,比如在 CTC 框架中使用CNN或CLDNN实现端对端建模,或是最近提出的Low Frame Rate、Chain 模型等粗粒度建模单元技术。
对于输入端,大体也分为两种:输入传统信号处理过的特征,采用不同的滤波器处理,然后进行左右或跳帧扩展。
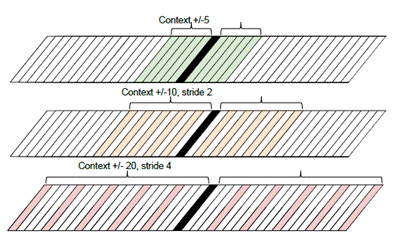
Fig 3.Multi-scale input feature. Stack 31140
第二种是直接输入原始频谱,将频谱图当做图像处理。
Fig 4. Frequency bands input
3.1 百度deep speech百度将 Deep CNN 应用于语音识别研究,使用了 VGGNet ,以及包含Residual 连接的深层 CNN等结构,并将 LSTM 和 CTC 的端对端语音识别技术相结合,使得识别错误率相对下降了 10% (原错误率的90%)以上。
此前,百度语音每年的模型算法都在不断更新,从 DNN ,到区分度模型,到 CTC 模型,再到如今的 Deep CNN 。基于 LSTM-CTC的声学模型也于 2015 年底已经在所有语音相关产品中得到了上线。比较重点的进展如下:1)2013 年,基于美尔子带的 CNN 模型;2)2014年,Sequence Discriminative Training(区分度模型);3)2015 年初,基于 LSTM-HMM的语音识别 ;4)2015 年底,基于 LSTM-CTC的端对端语音识别;5)2016 年,Deep CNN 模型,目前百度正在基于Deep CNN 开发deep speech3,据说训练采用大数据,调参时有上万小时,做产品时甚至有 10 万小时。
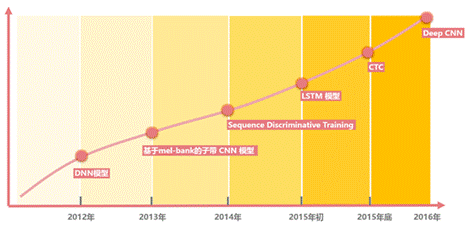
Fig5. 百度语音识别发展
百度发现,深层 CNN 结构,不仅能够显著提升 HMM 语音识别系统的性能,也能提升 CTC 语音识别系统的性能。仅用深层 CNN 实现端对端建模,其性能相对较差,因此将如 LSTM 或 GRU的 循环隐层与 CNN结合是一个相对较好的选择。可以通过采用 VGG 结构中的 3*3 这种小 kernel ,也可以采用 Residual 连接等方式来提升其性能,而卷积神经网络的层数、滤波器个数等都会显著影响整个模型的建模能力,在不同规模的语音训练数据库上,百度需要采用不同规模的 DeepCNN 模型配置才能使得最终达到最优的性能。