
针对预训练模型,由于目标较大,我们将图像按照4*4进行拼接,减少了数据量,提升了单张图像的目标数,也能取得一定的效果。但是当与其他增强方法结合时基本没有效果,因此我们也放弃了这种方案。
三、模型方案:
1.Baseline
图4 baseline方案
我们baseline选用的是mmdetection所实现的Cascade RCNN,backbone选用的是ResNeXt101 X64+DCN。因为此次比赛采用的是coco的评测指标AP50:95,因此Cascade RCNN通过设置不同的阈值进行回归可以取得非常好的效果。此外较大的backbone在这个数据集上往往能取得更好的效果。
2. 参数调整在比赛的初期,我们将训练集的数据选取2500张训练,498张本地验证,在此基础上进行调参。由于目标重叠度较高,在使用softnms阈值为0.001、max_per_img =300、翻转测试时效果较好,相比不使用这些参数大约能提升0.02左右。受到显存的限制从图像中随机裁剪(0.8w,0.8h)的图像区域,然后将短边随机限制在[640,960]之间,长边限制到1800进行多尺度训练,测试时图像适度放大短边设置为1200,精度可以训练到88.3%, 结合OHEM精度训练到88.6%左右,将本地验证的498张图像也输入进去训练能提升0.5%到89.2%左右。
针对数量较少的类别,我们在多类训练集中对贝类去硬壳、螺蛳、二极管、话梅核这几个类别进行补充标注,把一些模棱两可的目标都进行标注提高召回率,大约标记了100多个目标,在A榜能提升到90%左右。
如图5所示,针对anchor的调整,我们调整anchor 的比例从【0.5,1.0,2.0】改为【2.0/3.0,1.0,1.5】。此外为了提升大物体的检测能力,我们调整FPN的层次划分从56改为了70,相当于将FPN各层所分配的目标都调大,然后我们将anchor的尺度由8改为12对这些大物体进行检测。

图5 anchor 修改
如图6所示参数调整后可以发现FPN中目标数量的分布更加接近正态分布,我们认为这样的一种分布对检测会有所帮助。从ResNet的几个stage的卷积数量我们可以看到,FPN中间层所对应的ResNet的stage参数较多应检测较多目标,FPN两侧对应到backbone的参数较少检测目标数不宜过多。
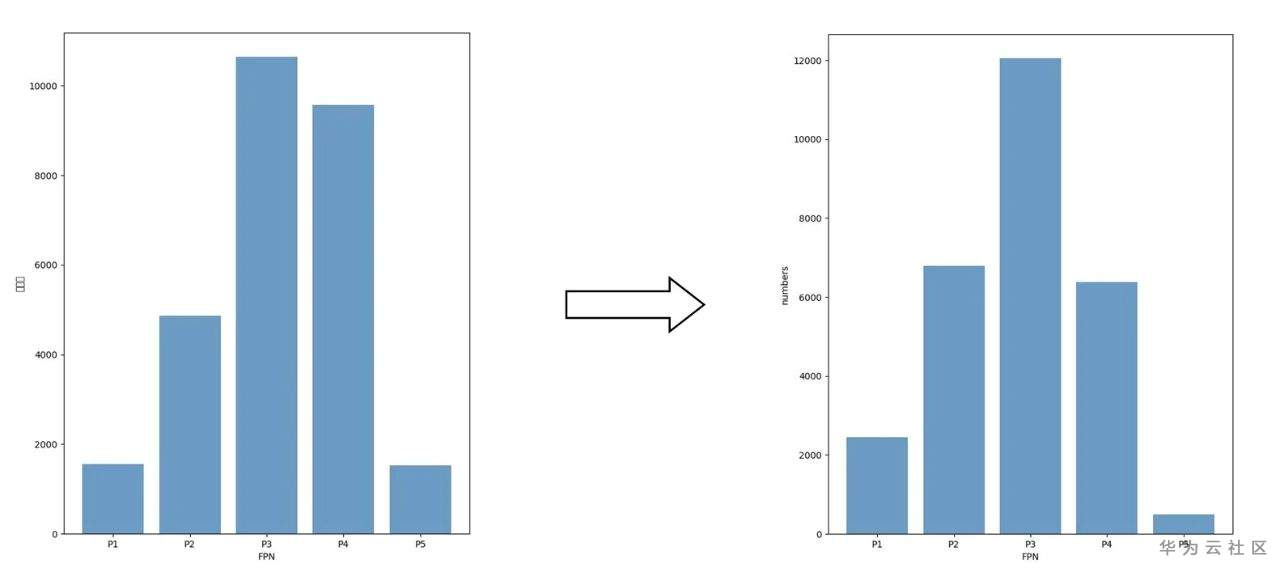
图6 目标在FPN上的数量分布变化
在图像增强时,我们加入在线的mixup进行24个epoch的训练可以提升到91.2%~91.3%,不过只有12个epoch的时候没有提升。Mixup我们设置的比较简单,两张图像分别以0.5的比例进行融合,因此没必要对loss进行加权。

图7 mixup 效果图
3.模型融合之前的测试过程中,我们认为1080Ti与2080速度应该相差不大,每次1080Ti上测试大约需要40分钟,因此我们只选用3个模型左右,这一点是比较吃亏的,在B榜的测试时我们发现2080居然比1080Ti快很多,我们单个模型加翻转测试只使用了25分钟,如果用更多模型可能会进一步提高分数。我们使用基于ResNext101 x32+gcb+DCN的Cascade RCNN,基于ResNext101 x64 +DCN的Cascade RCNN,基于ResNext101 x64 +DCN的Guided anchor Cascade RCNN。对于融合所使用的方法,不同的方法所能取得的效果都相差不大,我们采用的方法是论文《Weighted Boxes Fusion: ensembling boxes for object detection models》所提供的方法,融合阈值设置为0.8.