
设在样本数据集D上,样本数据的特征属性集为X={x1,x2,…,xd},类变量可被分为 Y={y1,y2,…,ym},即数据集D可以被分为ym个类别。我们假设x1,x2,…,xd相互独立,那么由贝叶斯定理可得:
对于相同的测试样本,分母P(X)的大小是固定不变的,因此在比较后验概率时,我们可以只比较分子的大小即可。
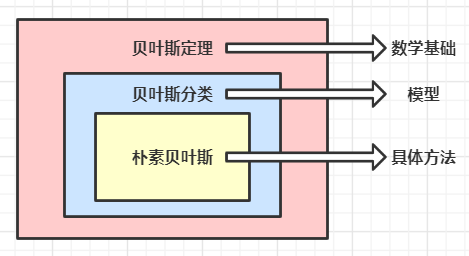
在这里解释一下贝叶斯定理、贝叶斯分类和朴素贝叶斯之间的区别,贝叶斯定理作为理论基础,解决了概率论中的逆概率问题,在这个基础上人们设计出了贝叶斯分类器,而朴素贝叶斯是贝叶斯分类器中的一种,也是最简单和常用的分类器,可以使用下面的图来表示它们之间的关系:
在实际应用中,朴素贝叶斯有广泛的应用,在文本分类、垃圾邮件过滤、情感预测及钓鱼网站的检测方面都能够起到良好的效果。为了训练朴素贝叶斯模型,我们需要先在训练集的基础上对分类好的数据进行训练,计算出先验概率和每个属性的条件概率,计算完成后,概率模型就可以使用贝叶斯原理对新数据进行预测。
贝叶斯推断与人脑的工作机制很像,这也是它为什么能够成为机器学习的基础,大脑的决策过程就是先对事物进行主观判断,然后搜集新的信息,优化主观判断,如果新的信息符合这个主观判断,那就提高主观判断的可信度,如果不符合,就降低主观判断的可信度。
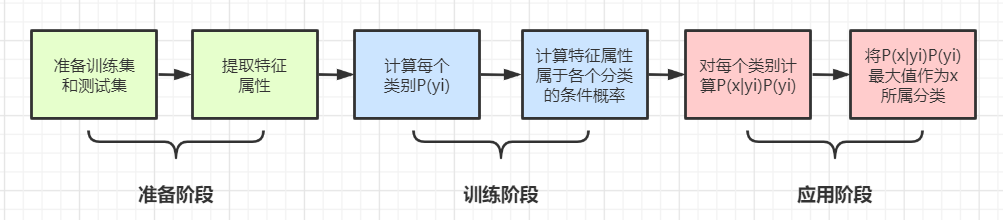
代码实现在对理论有了基本的了解后,我们开始分析怎样将朴素贝叶斯应用于我们文本处理的情感词分析中。主要步骤如下:
对训练集和测试集完成文本分词,并通过主观判断标注所属的分类
对训练集进行训练,统计每个词汇出现在分类下的次数,计算每个类别在训练样本中的出现频率、及每个特征属性对每个类别的条件概率(即似然概率)
将训练好的模型应用于测试集的样本上,根据贝叶斯分类计算样本在每个分类下的概率大小
比较在各个分类情况下的概率大小,推测文本最可能属于的情感分类
使用流程图表示:
首先准备数据集,这里使用了对某酒店的评论数据,根据主观态度将其分为“好评”或“差评”这两类待分类项,对每行分词后的语句打好了情感标签,并且已经提前对完整语句完成了对分词,数据格式如下:

在每行的数据的头部,是添加的“好评”或“差评”标签,标签与分词采用tab分割,词语之间使用空格分割。按照比例,将数据集的80%作为训练集,剩余20%作为测试集,分配过程尽量保证随机原则。
2、训练阶段在训练阶段,主要完成词频的统计工作。读取训练集,统计出每个词属于该分类下出现的次数,用于后续求解每个词出现在各个类别下的概率,即词汇与主观分类情感之间的关系:
private static void train(){ Map<String,Integer> parameters = new HashMap<>(); try(BufferedReader br = new BufferedReader(new FileReader(trainingData))){ //训练集数据 String sentence; while(null!=(sentence=br.readLine())){ String[] content = sentence.split("\t| "); //以tab或空格分词 parameters.put(content[0],parameters.getOrDefault(content[0],0)+1); for (int i = 1; i < content.length; i++) { parameters.put(content[0]+"-"+content[i], parameters.getOrDefault(content[0]+"-"+content[i], 0)+1); } } }catch (IOException e){ e.printStackTrace(); } saveModel(parameters); }将训练好的模型保存到文件中,可以方便在下次使用时不用重复进行模型的训练:
private static void saveModel(Map<String,Integer> parameters){ try(BufferedWriter bw =new BufferedWriter(new FileWriter(modelFilePath))){ parameters.keySet().stream().forEach(key->{ try { bw.append(key+"\t"+parameters.get(key)+"\r\n"); } catch (IOException e) { e.printStackTrace(); } }); bw.flush(); }catch (IOException e){ e.printStackTrace(); } }查看保存好的模型,数据的格式如下:
好评-免费送 3 差评-真烦 1 好评-礼品 3 差评-脏乱差 6 好评-解决 15 差评-挨宰 1 ……这里对训练的模型进行保存,所以如果后续有同样的分类任务时,可以直接在训练集的基础上进行计算,对于分类速度要求较高的任务,能够有效的提高计算的速度。
3、加载模型