
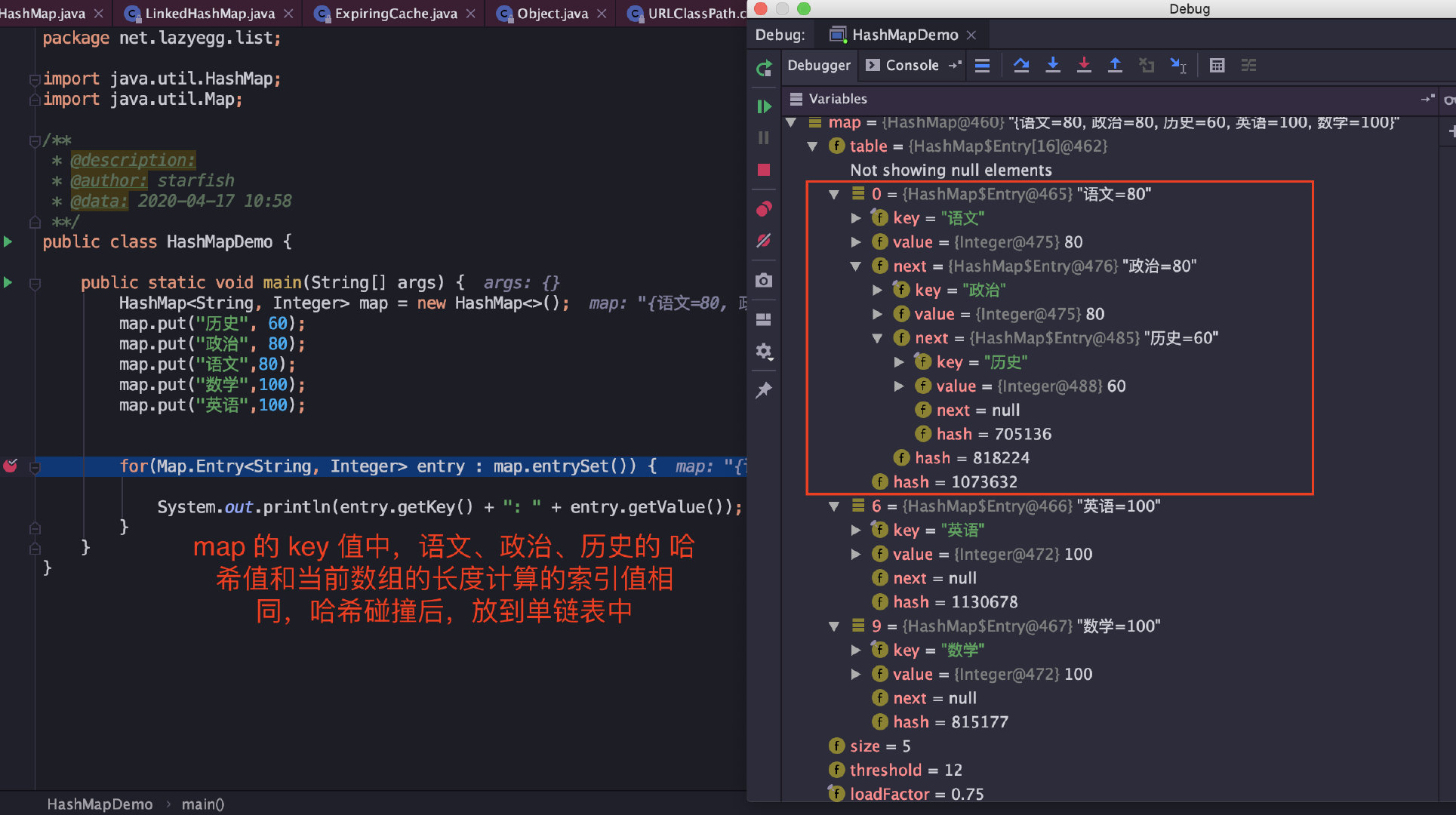
JDK 1.7 中,如果哈希碰撞过多,拉链过长,极端情况下,所有值都落入了同一个桶内,这就退化成了一个链表。通过 key 值查找要遍历链表,效率较低。 JDK1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
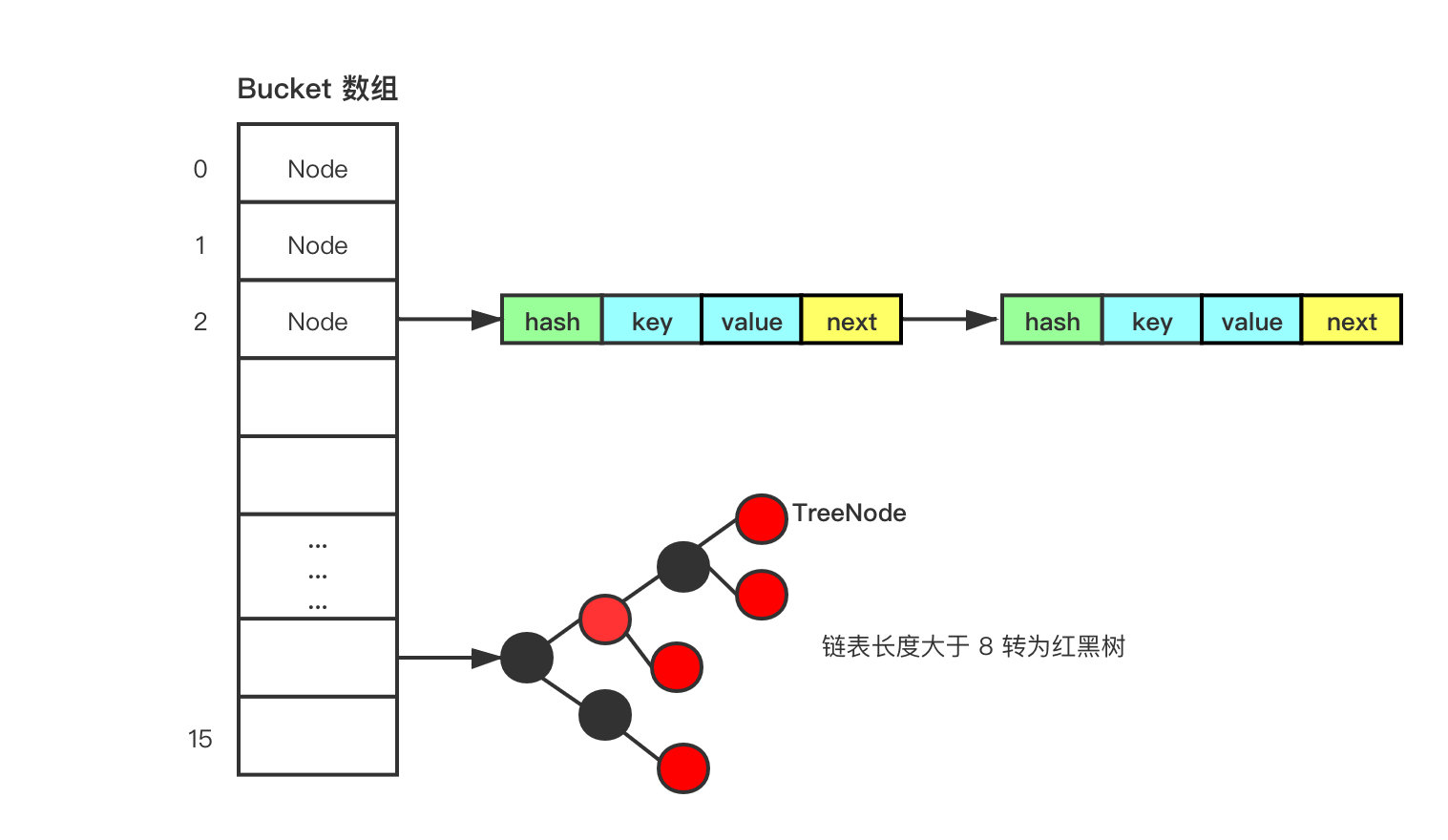
TreeMap、TreeSet以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
源码解析 构造方法JDK8 构造方法改动不是很大
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); } public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); } 确定哈希桶数组索引位置(hash 函数的实现) //方法一: static final int hash(Object key) { //jdk1.8 & jdk1.7 int h; // h = key.hashCode() 为第一步 取hashCode值 // h ^ (h >>> 16) 为第二步 高位参与运算 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } //方法二: static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有提取这个方法,而是放在了其他方法中,比如 put 的p = tab[i = (n - 1) & hash] return h & (length-1); //第三步 取模运算 }HashMap定位数组索引位置,直接决定了hash方法的离散性能。Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
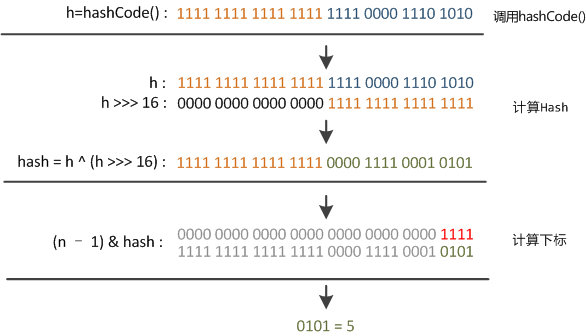
为什么要这样呢?
HashMap 的长度为什么是2的幂次方?
目的当然是为了减少哈希碰撞,使 table 里的数据分布的更均匀。