
deletableSegments
private def deletableSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean): Iterable[LogSegment] = { //如果日志段是空的,那么直接返回 if (segments.isEmpty) { Seq.empty } else { val deletable = ArrayBuffer.empty[LogSegment] var segmentEntry = segments.firstEntry //如果日志段集合不为空,找到第一个日志段 while (segmentEntry != null) { val segment = segmentEntry.getValue //获取下一个日志段 val nextSegmentEntry = segments.higherEntry(segmentEntry.getKey) val (nextSegment, upperBoundOffset, isLastSegmentAndEmpty) = if (nextSegmentEntry != null) (nextSegmentEntry.getValue, nextSegmentEntry.getValue.baseOffset, false) else (null, logEndOffset, segment.size == 0) //如果下一个日志段的位移没有大于或等于HW,并且日志段是匹配predicate函数的,下一个日志段也不是空的 //那么将这个日志段放入可删除集合中,然后遍历下一个日志段 if (highWatermark >= upperBoundOffset && predicate(segment, Option(nextSegment)) && !isLastSegmentAndEmpty) { deletable += segment segmentEntry = nextSegmentEntry } else { segmentEntry = null } } deletable } }这个方法逻辑十分清晰,主要做了如下几件事:
判断日志段集合是否为空,为空那么直接返回空集合;
如果日志段集合不为空,那么从日志段集合的第一个日志段开始遍历;
判断当前被遍历日志段是否能够被删除
日志段的下一个日志段的位移有没有大于或等于HW;
日志段是否能够通过predicate函数校验;
日志段是否是最后一个日志段;
将符合条件的日志段都加入到deletable集合中,并返回。
接下来调用deleteSegments函数:
private def deleteSegments(deletable: Iterable[LogSegment]): Int = { maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") { val numToDelete = deletable.size if (numToDelete > 0) { // we must always have at least one segment, so if we are going to delete all the segments, create a new one first // 我们至少保证要存在一个日志段,如果要删除所有的日志; //所以调用roll方法创建一个全新的日志段对象,并且关闭当前写入的日志段对象; if (segments.size == numToDelete) roll() lock synchronized { // 确保Log对象没有被关闭 checkIfMemoryMappedBufferClosed() // remove the segments for lookups // 删除给定的日志段对象以及底层的物理文件 removeAndDeleteSegments(deletable, asyncDelete = true) // 尝试更新日志的Log Start Offset值 maybeIncrementLogStartOffset(segments.firstEntry.getValue.baseOffset) } } numToDelete } } 写日志写日志的方法主要有两个:
appendAsLeader
def appendAsLeader(records: MemoryRecords, leaderEpoch: Int, isFromClient: Boolean = true, interBrokerProtocolVersion: ApiVersion = ApiVersion.latestVersion): LogAppendInfo = { append(records, isFromClient, interBrokerProtocolVersion, assignOffsets = true, leaderEpoch) }appendAsFollower
def appendAsFollower(records: MemoryRecords): LogAppendInfo = { append(records, isFromClient = false, interBrokerProtocolVersion = ApiVersion.latestVersion, assignOffsets = false, leaderEpoch = -1) }appendAsLeader 是用于写 Leader 副本的,appendAsFollower 是用于 Follower 副本同步的。它们的底层都调用了 append 方法
append
private def append(records: MemoryRecords, isFromClient: Boolean, interBrokerProtocolVersion: ApiVersion, assignOffsets: Boolean, leaderEpoch: Int): LogAppendInfo = { maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") { // 第1步:分析和验证待写入消息集合,并返回校验结果 val appendInfo = analyzeAndValidateRecords(records, isFromClient = isFromClient) // return if we have no valid messages or if this is a duplicate of the last appended entry // 如果压根就不需要写入任何消息,直接返回即可 if (appendInfo.shallowCount == 0) return appendInfo // trim any invalid bytes or partial messages before appending it to the on-disk log // 第2步:消息格式规整,即删除无效格式消息或无效字节 var validRecords = trimInvalidBytes(records, appendInfo) // they are valid, insert them in the log lock synchronized { // 确保Log对象未关闭 checkIfMemoryMappedBufferClosed() //需要分配位移值 if (assignOffsets) { // assign offsets to the message set // 第3步:使用当前LEO值作为待写入消息集合中第一条消息的位移值,nextOffsetMetadata为LEO值 val offset = new LongRef(nextOffsetMetadata.messageOffset) appendInfo.firstOffset = Some(offset.value) val now = time.milliseconds val validateAndOffsetAssignResult = try { LogValidator.validateMessagesAndAssignOffsets(validRecords, topicPartition, offset, time, now, appendInfo.sourceCodec, appendInfo.targetCodec, config.compact, config.messageFormatVersion.recordVersion.value, config.messageTimestampType, config.messageTimestampDifferenceMaxMs, leaderEpoch, isFromClient, interBrokerProtocolVersion, brokerTopicStats) } catch { case e: IOException => throw new KafkaException(s"Error validating messages while appending to log $name", e) } // 更新校验结果对象类LogAppendInfo validRecords = validateAndOffsetAssignResult.validatedRecords appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp appendInfo.lastOffset = offset.value - 1 appendInfo.recordConversionStats = validateAndOffsetAssignResult.recordConversionStats if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME) appendInfo.logAppendTime = now // re-validate message sizes if there's a possibility that they have changed (due to re-compression or message // format conversion) // 第4步:验证消息,确保消息大小不超限 if (validateAndOffsetAssignResult.messageSizeMaybeChanged) { for (batch <- validRecords.batches.asScala) { if (batch.sizeInBytes > config.maxMessageSize) { // we record the original message set size instead of the trimmed size // to be consistent with pre-compression bytesRejectedRate recording brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes) brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes) throw new RecordTooLargeException(s"Message batch size is ${batch.sizeInBytes} bytes in append to" + s"partition $topicPartition which exceeds the maximum configured size of ${config.maxMessageSize}.") } } } // 直接使用给定的位移值,无需自己分配位移值 } else { // we are taking the offsets we are given if (!appendInfo.offsetsMonotonic)// 确保消息位移值的单调递增性 throw new OffsetsOutOfOrderException(s"Out of order offsets found in append to $topicPartition: " + records.records.asScala.map(_.offset)) if (appendInfo.firstOrLastOffsetOfFirstBatch < nextOffsetMetadata.messageOffset) { // we may still be able to recover if the log is empty // one example: fetching from log start offset on the leader which is not batch aligned, // which may happen as a result of AdminClient#deleteRecords() val firstOffset = appendInfo.firstOffset match { case Some(offset) => offset case None => records.batches.asScala.head.baseOffset() } val firstOrLast = if (appendInfo.firstOffset.isDefined) "First offset" else "Last offset of the first batch" throw new UnexpectedAppendOffsetException( s"Unexpected offset in append to $topicPartition. $firstOrLast " + s"${appendInfo.firstOrLastOffsetOfFirstBatch} is less than the next offset ${nextOffsetMetadata.messageOffset}. " + s"First 10 offsets in append: ${records.records.asScala.take(10).map(_.offset)}, last offset in" + s" append: ${appendInfo.lastOffset}. Log start offset = $logStartOffset", firstOffset, appendInfo.lastOffset) } } // update the epoch cache with the epoch stamped onto the message by the leader // 第5步:更新Leader Epoch缓存 validRecords.batches.asScala.foreach { batch => if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) { maybeAssignEpochStartOffset(batch.partitionLeaderEpoch, batch.baseOffset) } else { // In partial upgrade scenarios, we may get a temporary regression to the message format. In // order to ensure the safety of leader election, we clear the epoch cache so that we revert // to truncation by high watermark after the next leader election. leaderEpochCache.filter(_.nonEmpty).foreach { cache => warn(s"Clearing leader epoch cache after unexpected append with message format v${batch.magic}") cache.clearAndFlush() } } } // check messages set size may be exceed config.segmentSize // 第6步:确保消息大小不超限 if (validRecords.sizeInBytes > config.segmentSize) { throw new RecordBatchTooLargeException(s"Message batch size is ${validRecords.sizeInBytes} bytes in append " + s"to partition $topicPartition, which exceeds the maximum configured segment size of ${config.segmentSize}.") } // maybe roll the log if this segment is full // 第7步:执行日志切分。当前日志段剩余容量可能无法容纳新消息集合,因此有必要创建一个新的日志段来保存待写入的所有消息 //下面情况将会执行日志切分: //logSegment 已经满了 //日志段中的第一个消息的maxTime已经过期 //index索引满了 val segment = maybeRoll(validRecords.sizeInBytes, appendInfo) val logOffsetMetadata = LogOffsetMetadata( messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch, segmentBaseOffset = segment.baseOffset, relativePositionInSegment = segment.size) // now that we have valid records, offsets assigned, and timestamps updated, we need to // validate the idempotent/transactional state of the producers and collect some metadata // 第8步:验证事务状态 val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState( logOffsetMetadata, validRecords, isFromClient) maybeDuplicate.foreach { duplicate => appendInfo.firstOffset = Some(duplicate.firstOffset) appendInfo.lastOffset = duplicate.lastOffset appendInfo.logAppendTime = duplicate.timestamp appendInfo.logStartOffset = logStartOffset return appendInfo } // 第9步:执行真正的消息写入操作,主要调用日志段对象的append方法实现 segment.append(largestOffset = appendInfo.lastOffset, largestTimestamp = appendInfo.maxTimestamp, shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp, records = validRecords) // Increment the log end offset. We do this immediately after the append because a // write to the transaction index below may fail and we want to ensure that the offsets // of future appends still grow monotonically. The resulting transaction index inconsistency // will be cleaned up after the log directory is recovered. Note that the end offset of the // ProducerStateManager will not be updated and the last stable offset will not advance // if the append to the transaction index fails. // 第10步:更新LEO对象,其中,LEO值是消息集合中最后一条消息位移值+1 // 前面说过,LEO值永远指向下一条不存在的消息 updateLogEndOffset(appendInfo.lastOffset + 1) // update the producer state // 第11步:更新事务状态 for (producerAppendInfo <- updatedProducers.values) { producerStateManager.update(producerAppendInfo) } // update the transaction index with the true last stable offset. The last offset visible // to consumers using READ_COMMITTED will be limited by this value and the high watermark. for (completedTxn <- completedTxns) { val lastStableOffset = producerStateManager.lastStableOffset(completedTxn) segment.updateTxnIndex(completedTxn, lastStableOffset) producerStateManager.completeTxn(completedTxn) } // always update the last producer id map offset so that the snapshot reflects the current offset // even if there isn't any idempotent data being written producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1) // update the first unstable offset (which is used to compute LSO) maybeIncrementFirstUnstableOffset() trace(s"Appended message set with last offset: ${appendInfo.lastOffset}, " + s"first offset: ${appendInfo.firstOffset}, " + s"next offset: ${nextOffsetMetadata.messageOffset}, " + s"and messages: $validRecords") // 是否需要手动落盘。一般情况下我们不需要设置Broker端参数log.flush.interval.messages // 落盘操作交由操作系统来完成。但某些情况下,可以设置该参数来确保高可靠性 if (unflushedMessages >= config.flushInterval) flush() // 第12步:返回写入结果 appendInfo } } }上面代码的主要步骤如下:
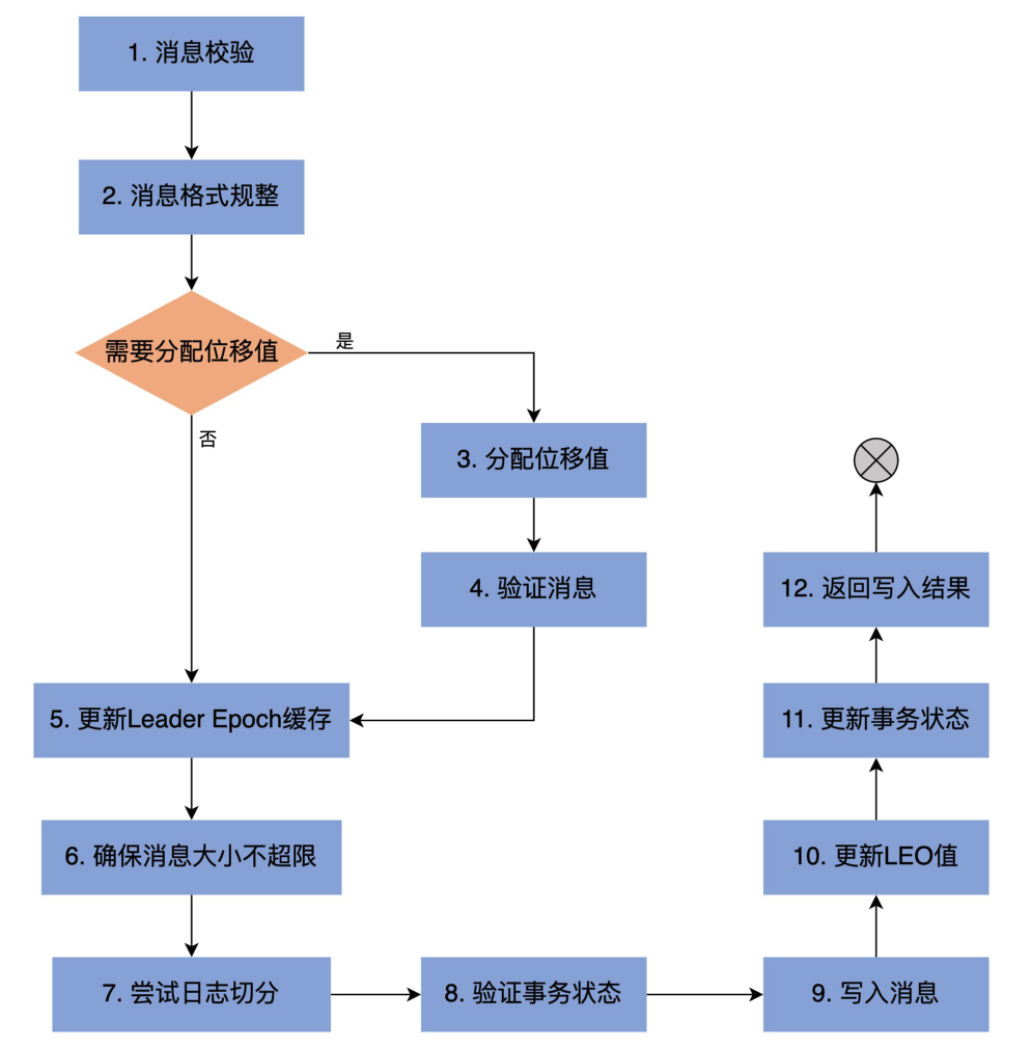
我们下面看看analyzeAndValidateRecords是如何进行消息校验的: