
Redis的跳表实现由zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳表信息(比如表头节点、表尾节点、长度),而zskiplistNode则用于表示跳表节点。
每个跳表节点的层高都是1至32之间的随机数。
在同一个跳表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的。
跳表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。
整数集合(intset)整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
整数集合的数据结构:
typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; } intset;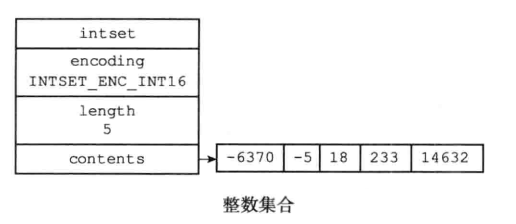
整数集合是集合键的底层实现之一。
整数集合的底层实现为数组,这个数组以有序、无重复的方式保存集合元素,在有需要时,程序会根据新添加元素的类型,改变这个数组的类型。
升级操作为整数集合带来了操作上的灵活性,并且尽可能地节约了内存。
整数集合只支持升级操作,不支持降级操作。
压缩列表(ziplist)压缩列表(ziplist)是列表键和哈希键的底层实现之一。当一个列表链只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。

压缩列表是一种为节约内存而开发的顺序型数据结构。
压缩列表被用作列表键和哈希键的底层实现之一。
压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值。
添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作,但这种操作出现的几率并不高。
Redis数据类型Redis中,键的数据类型是字符串,但提供了丰富的数据存储方式,方便开发者使用,值的数据类型有很多,常用的数据类型有五种,分别是字符串(string)、列表(list)、字典(hash)、集合(set)、有序集合(sortedset)。
字符串(string)“字符串(string)”这种数据结构类型非常简单,对应到数据结构里,就是Redis里的简单动态字符串(SDS)。
列表(list)列表这种数据类型支持存储一组数据。这种数据类型对应两种实现方法,一种是压缩列表(ziplist),另一种是双向循环链表。
当列表中存储的数据量比较小的时候,列表就可以采用压缩列表的方式实现。具体需要同时满足下面两个条件:
列表中保存的单个数据(有可能是字符串类型的)小于64字节;
列表中数据个数少于512。
字典(hash)
字典类型用来存储一组数据对。每个数据对又包含键值两部分。字典类型也有两种实现方式。一种是压缩列表,另一种是散列表。
同样,只有当存储的数据量比较小的情况下,Redis才使用压缩列表来实现字典类型。具体需要满足两个条件:
字典中保存的键和值的大小都要小于64字节;
字典中键值对的个数要小于512个。
集合(set)集合这种数据类型用来存储一组不重复的数据。有两种实现方式:一种是基于有序数组,另一种是基于散列表。
当要存储的数据,同时满足下面这样两个条件的时候,Redis就采用有序数组,来实现集合这种数据类型。
存储的数据都是整数;
存储的数据元素个数不超过512个。
有序集合(sortedset)有序集合用来存储一组数据,并且每个数据会附带一个得分。通过得分的大小,我们将数据组织成跳表这种数据结构,以支持快速地按照得分值、得分区间获得数据。
有序集合也有两种实现方式:跳表和压缩列表。使用压缩列表来实现有序集合的前提:
所有数据的大小都要小于64字节;
元素个数要小于128个。
参考资料Redis设计与实现
算法实战(一):剖析Redis常用数据类型对应的数据结构