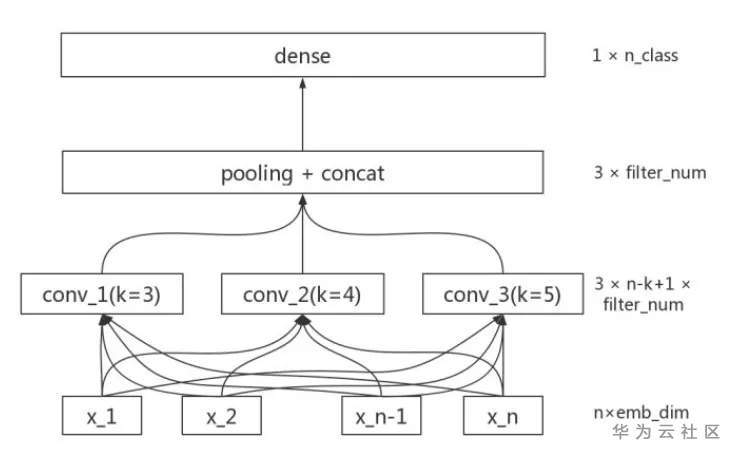
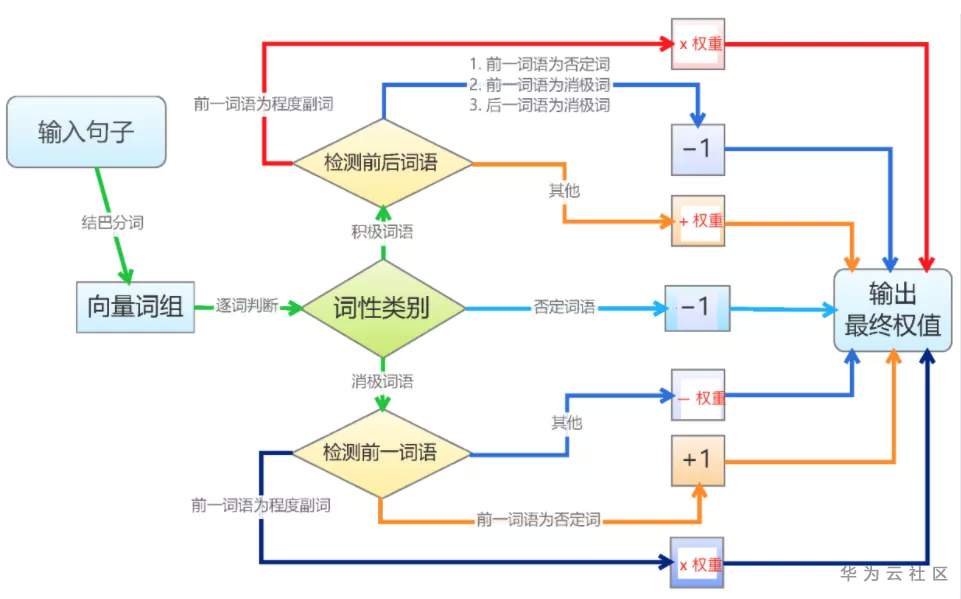
当然也可以通过语料来自己训练情感词典。导入情感词典后,我们需要利用情感词典文本匹配算法进行情感分析。基于词典的文本匹配算法相对简单。逐个遍历分词后的语句中的词语,如果词语命中词典,则进行相应权重的处理。正面词权重为加法,负面词权重为减法,否定词权重取相反数,程度副词权重则和它修饰的词语权重相乘。利用最终输出的权重值,就可以区分是正面、负面还是中性情感了。一个典型的利用情感词典文本匹配算法进行情感分析的算法流程如下[5]:
基于统计方法的情感分析模型简单易行,具有通用和泛化性,但是仍然存在如下三点主要的不足:
1 精度不高语言是一个高度复杂的东西,采用简单的线性叠加显然会造成很大的精度损失。词语权重同样不是一成不变的,而且也难以做到准确。
2 词典需要持续更新对于新的情感词,比如给力,牛逼等等,词典不一定能够覆盖。因此需要不断刷新词典来补充新词。在当下网络词汇不断出现的时代,如果词典的刷新速度跟不上新词出现的速度,那么情感分析在实际使用中会与预期相差较大的距离。比如淘宝商品评价,饿了么外卖评价等,如果无法捕捉新词,那么分析的情感将会偏离实际。
3 构建词典困难基于词典的情感分类,核心在于情感词典。而情感词典的构建需要有较强的背景知识,需要对语言有较深刻的理解,在分析外语方面会有很大限制。
基于深度学习的情感分析模型在了解了基于统计方法的情感分析模型优缺点之后,我们看一下深度学习文本分类模型是如何进行文本情感分析分类的。深度学习的一个优势就是可以进行端到端的学习,而省略的中间每一步的人工干预步骤。基于预训练模型生成的词向量,深度学习首先可以解决的一个重要问题就是情感词典的构建。下面我们会以集中典型的文本分类模型为例,展示深度文本分类模型的演进方向和适用场景。
2.1 FastText[6]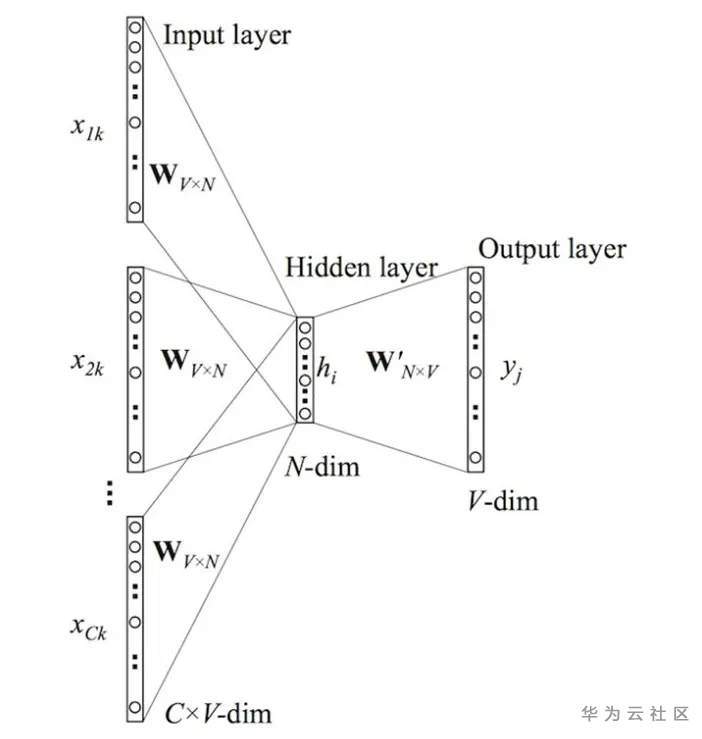
模型运行步骤: