
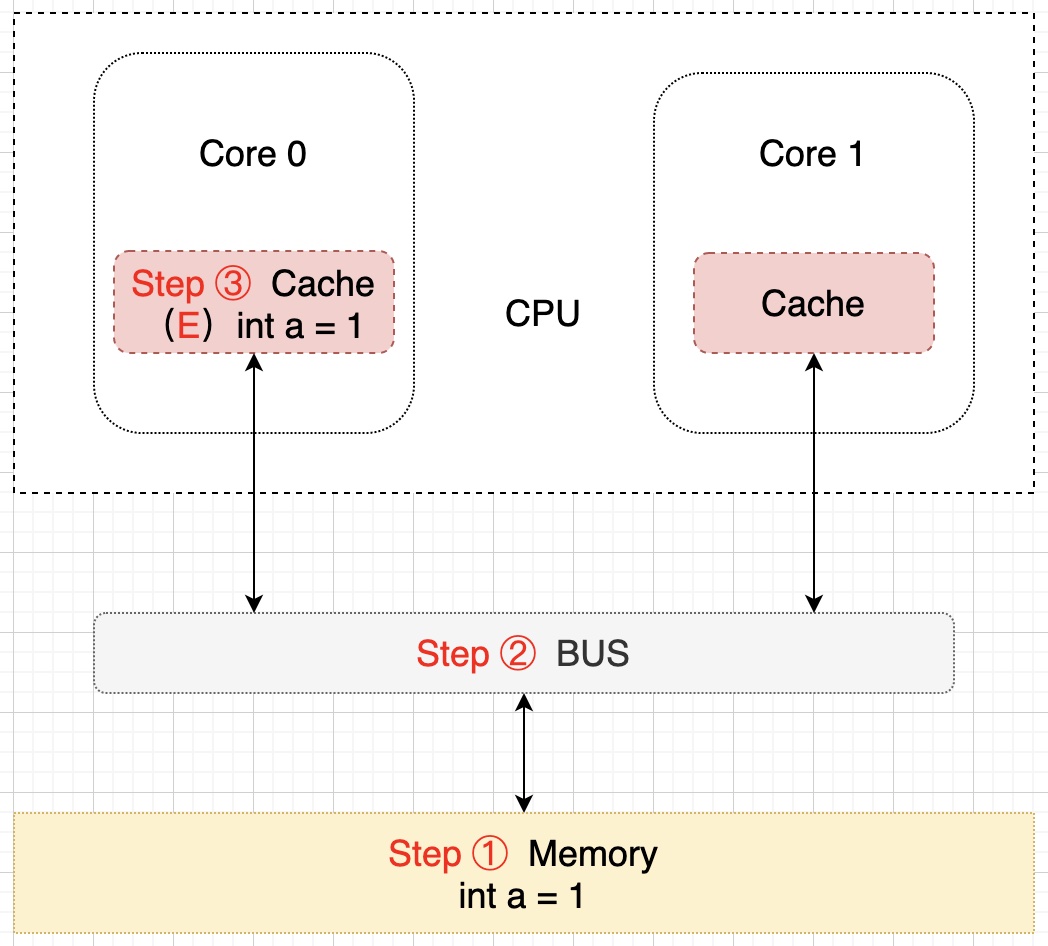
单核读取步骤:Core 0 发出一条从内存中读取 a 的指令,从内存通过 BUS 读取 a 到 Core 0 的缓存中,因为此时数据只在 Core 0 的缓存中,所以将 Cache line 修改为 E 状态(独享),该过程用示意图表示如下:
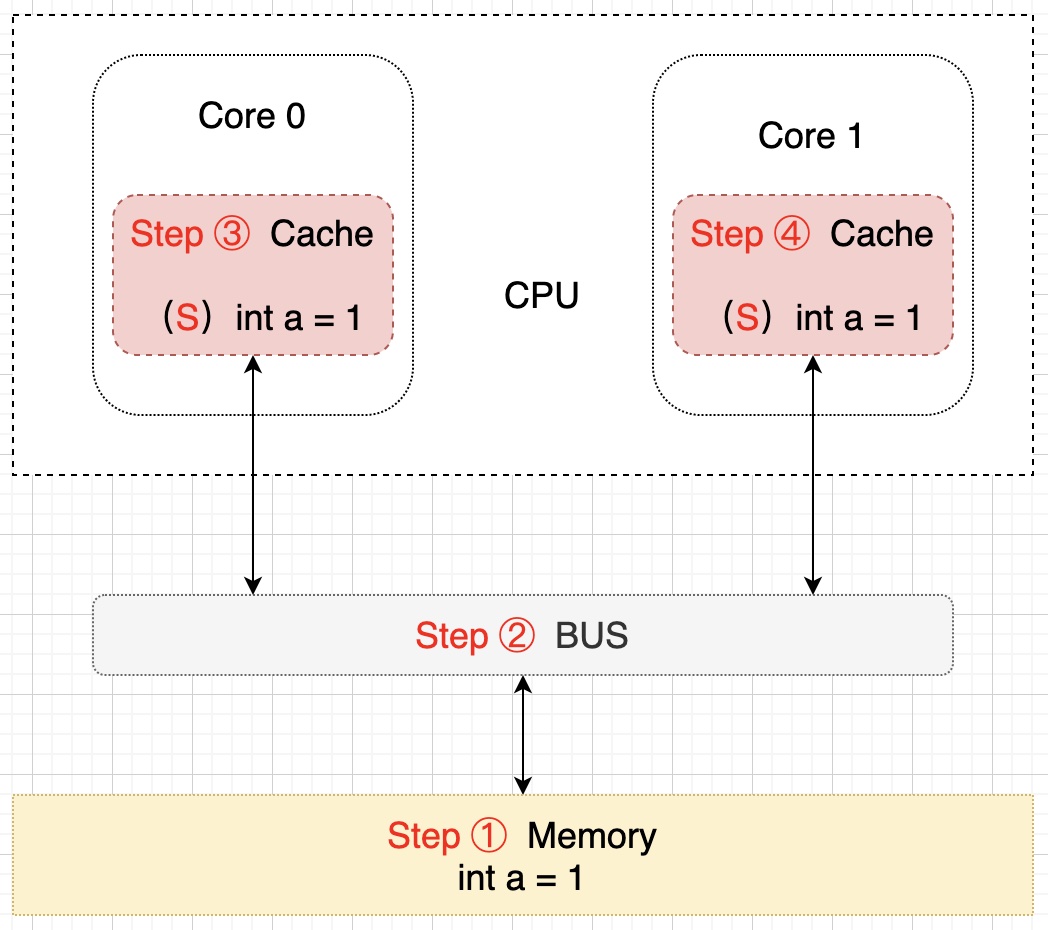
双核读取步骤:首先 Core 0 发出一条从内存中读取 a 的指令,从内存通过 BUS 读取 a 到 Core 0 的缓存中,然后将 Cache line 置为 E 状态,此时 Core 1 发出一条指令,也是要从内存中读取 a,当 Core 1 试图从内存读取 a 的时候, Core 0 检测到了发生地址冲突(其它缓存读主存中该缓存行的操作),然后 Core 0 对相关数据做出响应,a 存储于这两个核心 Core 0 和 Core 1 的缓存行中,然后设置其状态为 S 状态(共享),该过程示意图如下:
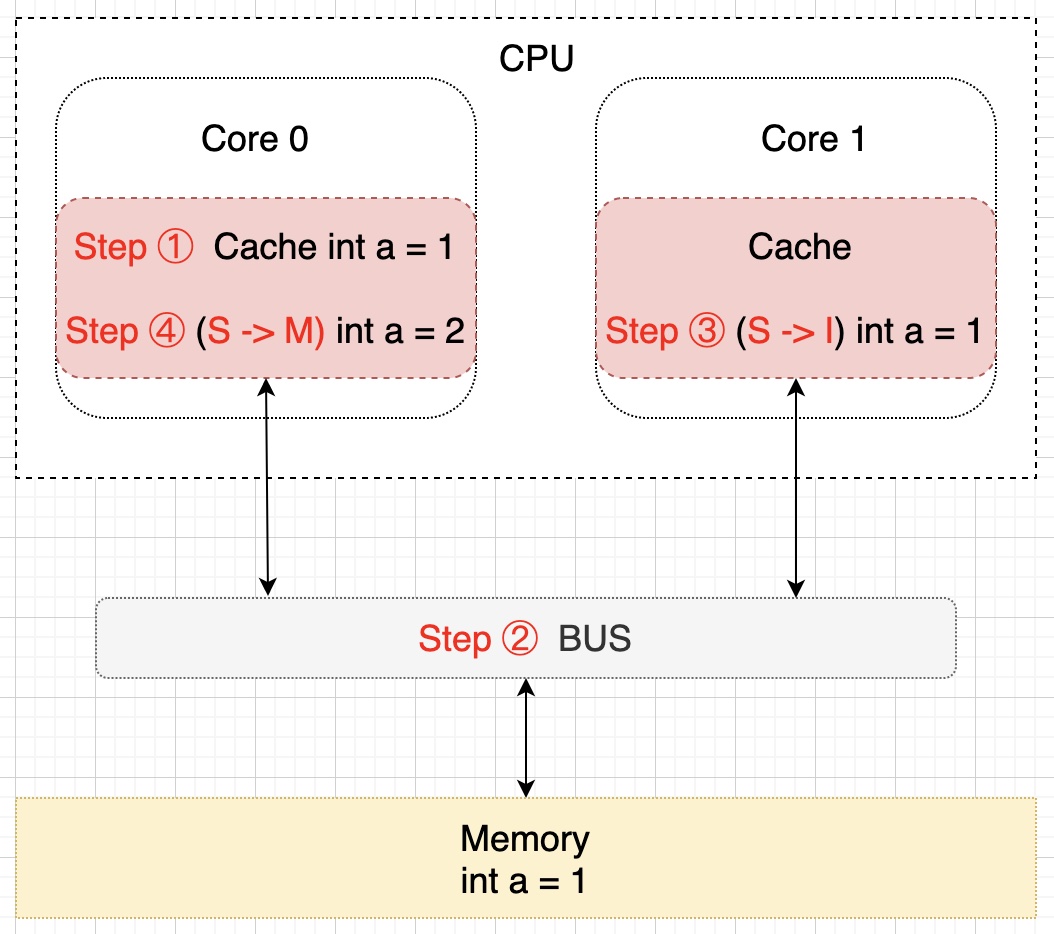
假设此时 Core 0 核心需要对 a 进行修改了,首先 Core 0 会将其缓存的 a 设置为 M(修改)状态,然后通知其它缓存了 a 的其它核 CPU(比如这里的 Core 1)将内部缓存的 a 的状态置为 I(无效)状态,最后才对 a 进行赋值操作。该过程如下所示:
细心的朋友们可能已经注意到了,上图中内存中 a 的值(值为 1)并不等于 Core 0 核心中缓存的最新值(值为 2),那么要什么时候才会把该值更新到内存中去呢?就是当 Core 1 需要读取 a 的值的时候,此时会通知 Core 0 将 a 的修改后的最新值同步到内存(Memory)中去,在这个同步的过程中 Core 0 中缓存的 a 的状态会置为 E(独享)状态,同步完成后将 Core 0 和 Core 1 中缓存的 a 置为 S(共享)状态,示意图描述该过程如下所示:
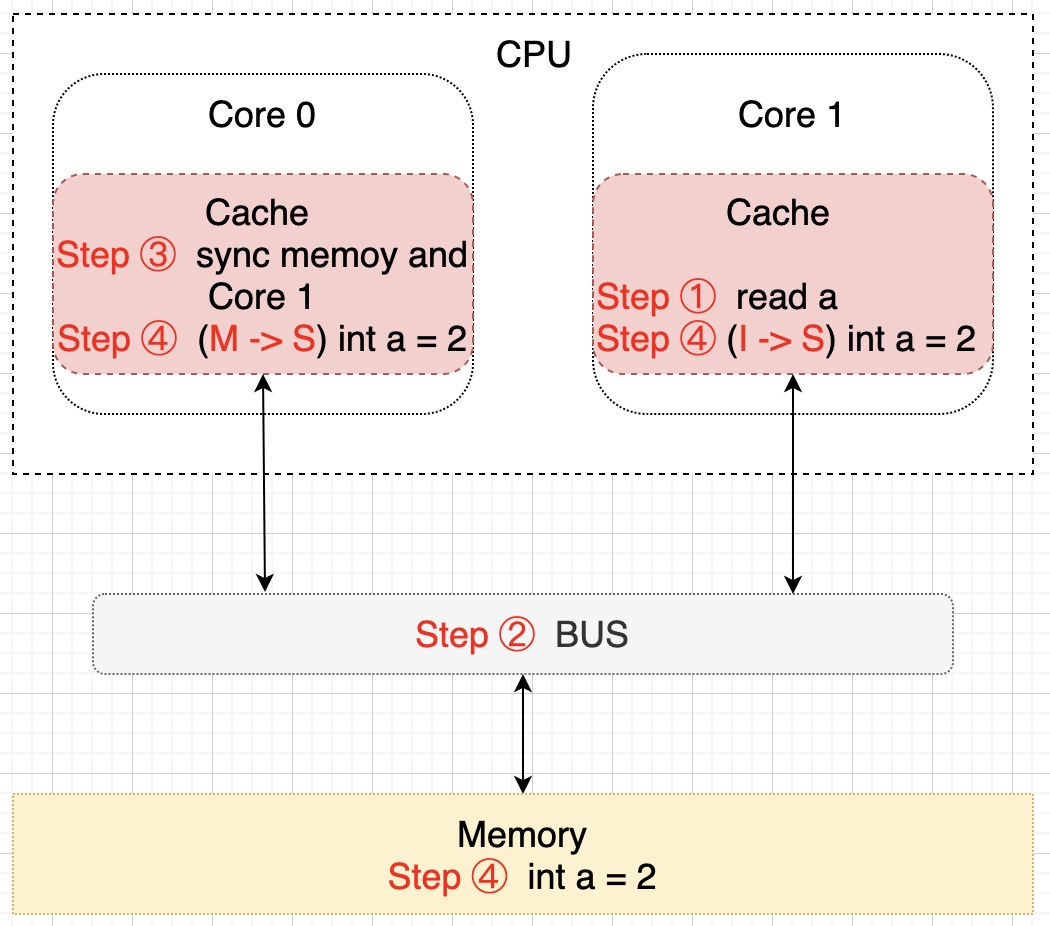
至此,变量 a 在 CPU 的两个核 Core 0 和 Core 1 中回到了 S(共享)状态了,以上只是简单的描述了一下大概的过程,实际上这些都是在 CPU 的硬件层面上去保证的,而且操作比较复杂。
五、总结现在很多一些实现缓存功能的应用程序都是基于这些思想设计的,缓存把数据库中的数据进行缓存到速度更快的内存中,可以加快我们应用程序的响应速度,比如我们使用常见的 Redis 数据库可能是采用下面这些策略:① 首先应用程序从缓存中查询数据,如果有就直接使用该数据进行相应操作后返回,如果没有则查询数据库,更新缓存并且返回。② 当我们需要更新数据时,先更新数据库,然后再让缓存失效,这样下次就会先查询数据库再回填到缓存中去,可以发现,实际上底层的一些思想都是相通的,不同的只是对于特定的场景可能需要增加一些额外的约束。基础知识才是技术这颗大树的根,我们先把根栽好了,剩下的那些枝和叶都是比较容易得到的东西了。