
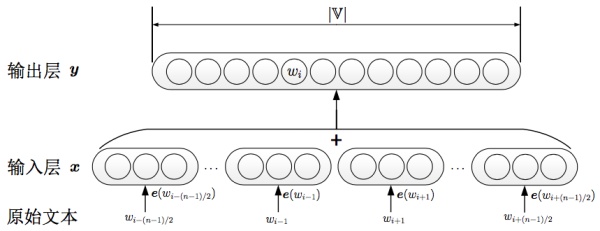
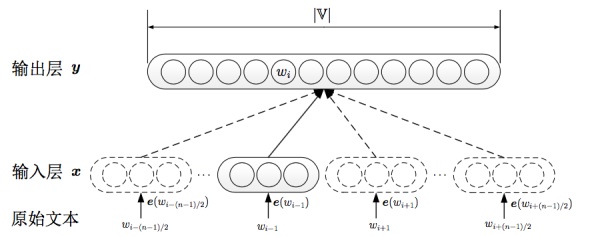
其中skip-gram主要由包括以下几块:
输入one-hot编码;
隐层大小为次维度大小;
对于常见词或者词组,我们将其作为单个word处理;
对高频词进行抽样减少训练样本数目;
对优化目标采用negative sampling,每个样本训练时,只更新部分网络权重。
Glove
Glove实际上是结合了矩阵分解方法和Window-based method的一种方法,具体看下中公式2-7的推导,Glove的优势主要在于:
skip-gram利用local context,但是没有考虑大量词共现的信息,而文中认为词共现信息可以在一定程度上解释词的语义,通过修改目标函数,z
作者认为相对于原始的额条件概率,条件概率的比值更好地反映出词之间的相关性,如下图:

为保证神经网络建模线性结构关系(神经网络容易建模非线性关系,容易欢笑线性关系),对词差值建模,并且增加一个权重函数;
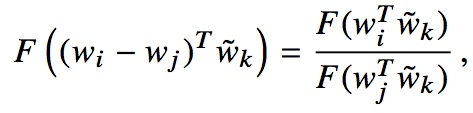
使用AdaGrad:根据参数的历史梯度信息更新每个参数的学习率;
为减少模型复杂度,增加假设词符合幂率分布,可为模型找下界限,减少参数空间;
NNLM
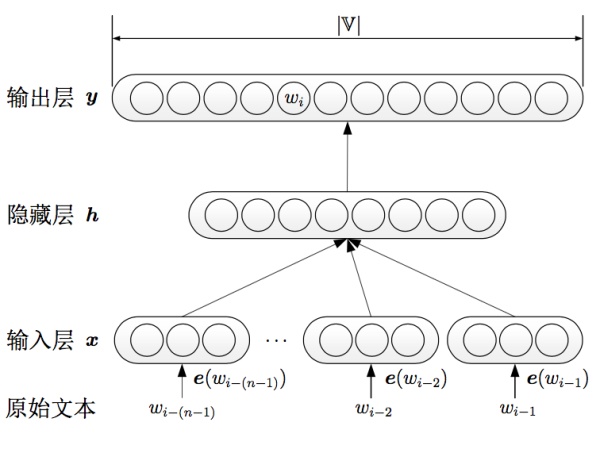
如上图,早在2001年,Bengio就使用神经网络学习语言模型,中间可输出词向量,NNLM和传统的方法不同,不通过计数的方法对n元条件概率估计,而是直接通过神经网络结构对模型求解,传统的语言模型通常已知序列,来预测接下来的出现词的可能性,Bengio提出的nnlm通过将各词的表示拼接,然后接入剩下两层神经网络,依次得到隐藏层h和输出层y,其中涉及到一些网络优化的工作,如直连边的引入,最终的输出节点有|V|个元素,依次对应此表中某个词的可能性,通过正向传播、反向反馈,输入层的e就会更新使得语言模型最后的性能最好,e就是我们可拿来的向量化的一种表示。
知识表示
知识表示是最近开始火起来的一种表示方式,结合知识图谱,实体之间的关系,来建模某个实体的表示,和NLP里的很类似,上下文通常能表征词的关系,这里也是一样,结合知识图谱的知识表示,不仅考虑实体间链接关系,还可以通过引入更多的如text、image信息来表征实体,这里可以关注下清华刘知远老师的相关工作。
词性标注词性标注的相关学习路线,基本可以重搬下分词相关的工作,也是一个词性标注的工作
基于最大熵的词性标注
基于统计最大概率输出词性
基于HMM词性标注
基于CRF的词性标注 可以稍微多聊一点的是Transformation-based learning,这里主要参考曼宁那本经典的NLP教材 Transformation-based learning of Tags, Transformation 主要包括两个部分:a triggering environment, rewrite rule,通过不停统计语料中的频繁项,若满足需要更改的阈值,则增加词性标注的规则。
总结从来都认为基础不牢、地动山摇,后面会继续努力,从源码、文章上更深了解自然语言处理相关的工作,虽然现在还是半调子水平,但是一定会努力,过去一段时间由于工作相对比较忙,主要还沉沦了一段时间打农药,后面会多花点时间在技术上的积淀,刷课、读paper、读源码。另外,为了加强自己的coding能力,已经开始用cpp啦(周六写了500+行代码),想想都刺激,哈哈哈!!!我这智商够不够呀,anyway,加油吧!!!
2017-10-22: 个人博客,出了点问题,貌似是因为七牛图床需要再搞个啥备案,看来以后博客要费啦!!!
哎, 真麻烦
相关阅读
爸爸去哪儿玩转黑科技:快来测测自己和老爸有多像?