
我们以compact行格式为例:
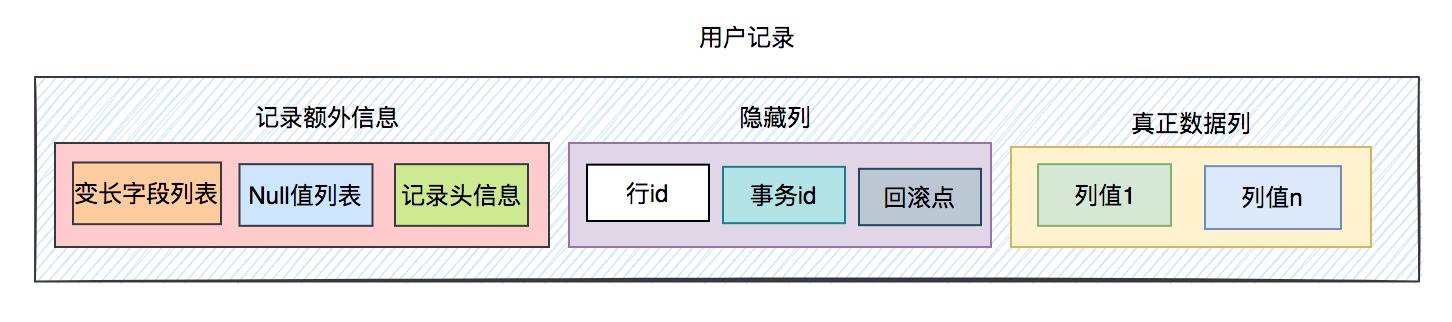
一条用户记录主要包含三部分内容:
记录额外信息,它包含了变长字段、null值列表和记录头信息。
隐藏列,它包含了行id、事务id和回滚点。
真正的数据列,包含真正的用户数据,可以有很多列。
下面让我们一起了解一下这些内容。
3.1 额外信息额外信息并非真正的用户数据,它是为了辅助存数据用的。
3.1.1 变长字段列表有些数据如果直接存会有问题,比如:如果某个字段是varchar或text类型,它的长度不固定,可以根据存入数据的长度不同,而随之变化。
如果不在一个地方记录数据真正的长度,innodb很可能不知道要分配多少空间。假如都按某个固定长度分配空间,但实际数据又没占多少空间,岂不是会浪费?
所以,需要在变长字段中记录某个变长字段占用的字节数,方便按需分配空间。
3.1.2 null值列表数据库中有些字段的值允许为null,如果把每个字段的null值,都保存到用户记录中,显然有些浪费存储空间。
有没有办法只简单的标记一下,不存储实际的null值呢?
答案:将为null的字段保存到null值列表。
在列表中用二进制的值1,表示该字段允许为null,用0表示不允许为null。它只占用了1位,就能表示某个字符是否为null,确实可以节省很多存储空间。
3.1.3 记录头信息记录头信息用于描述一些特殊的属性。

它主要包含:
deleted_flag: 即删除标记,用于标记该记录是否被删除了。
min_rec_flag: 即最小目录标记,它是非叶子节点中的最小目录标记。
n_owned:即拥有的记录数,记录该组索引记录的条数。
heap_no:即堆上的位置,它表示当前记录在堆上的位置。
record_type:即记录类型,其中:0表示普通记录,1表示非叶子节点,2表示Infrimum记录, 3表示Supremum记录。
next_record:即下一条记录的位置。
3.2 隐藏列数据库在保存一条用户记录时,会自动创建一些隐藏列。如下图所示:

目前innodb自动创建的隐藏列有三种:
db_row_id,即行id,它是一条记录的唯一标识。
db_trx_id,即事务id,它是事务的唯一标识。
db_roll_ptr,即回滚点,它用于事务回滚。
如果表中有主键,则用主键做行id,无需额外创建。如果表中没有主键,假如有不为null的unique唯一键,则用它做为行id,同样无需额外创建。
如果表中既没有主键,又没有唯一键,则数据库会自动创建行id。
也就是说在innodb中,隐藏列中事务id和回滚点是一定会被创建的,但行id要根据实际情况决定。
3.3 真正数据列真正的数据列中存储了用户的真实数据,它可以包含很多列的数据。这个比较简单,没有什么好多说的。
3.4 用户记录是如何相连的?通过上面介绍的内容,大家对一条用户记录是如何存储的,应该有了一定的认识。
但问题来了,一条用户记录和另一条用户记录是如何相连的,innodb是怎么知道,某条记录的下一条记录是谁?
答案是:用前面提到过的, 记录额外信息 》 记录头信息 》下一条记录的位置。
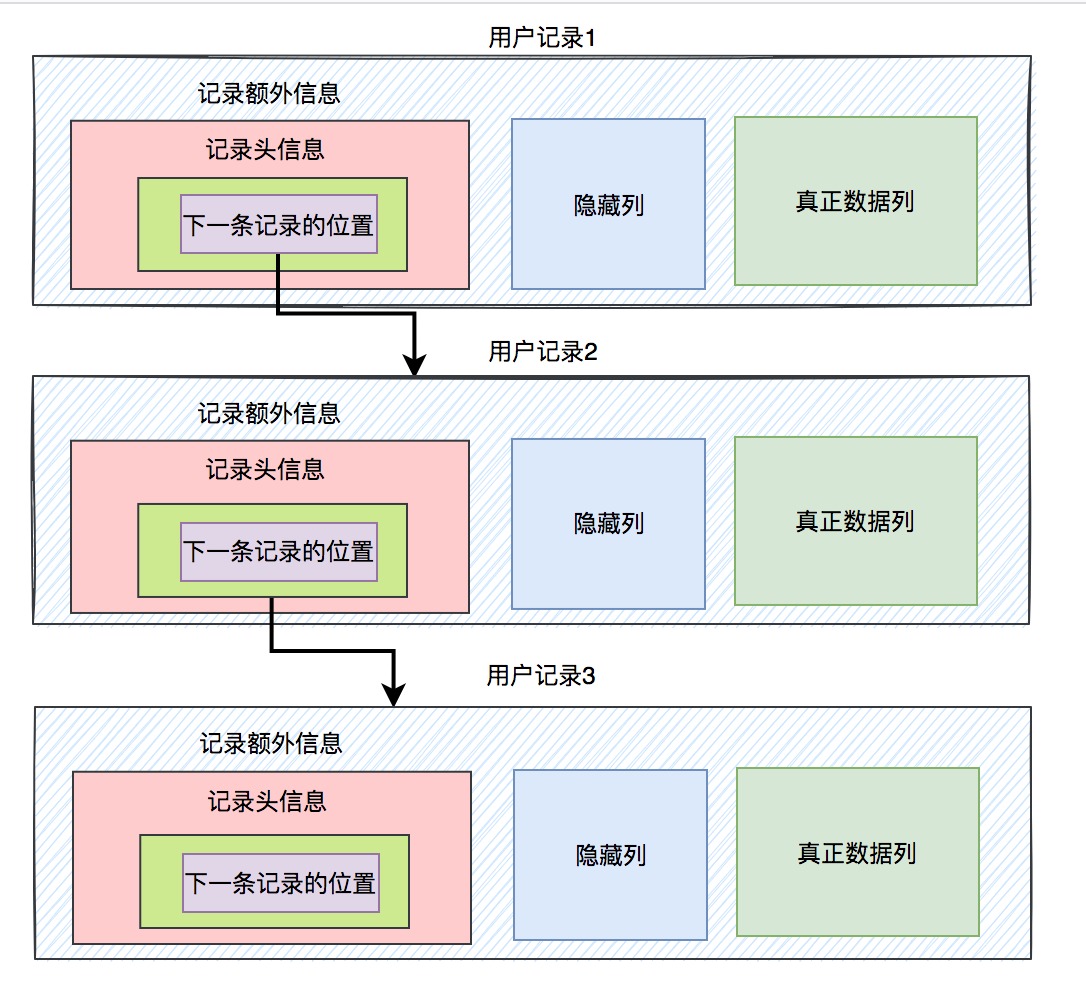
多条用户记录之间通过下一条记录的位置,组成了一个单向链表。这样就能从前往后,找到所有的记录了。 4.最大和最小记录
从上面可以得知,在一个数据页当中,如果存在多条用户记录,它们是通过下一条记录的位置相连的。
不过有个问题:如果才能快速找到最大的记录和最小的记录呢?
这就需要在保存用户记录的同时,也保存最大和最小记录了。
最大记录保存到Supremum记录中。
最小记录保存在Infimum记录中。
在保存用户记录时,数据库会自动创建两条额外的记录:Supremum 和 Infimum。它们之间的关系,如下图所示:
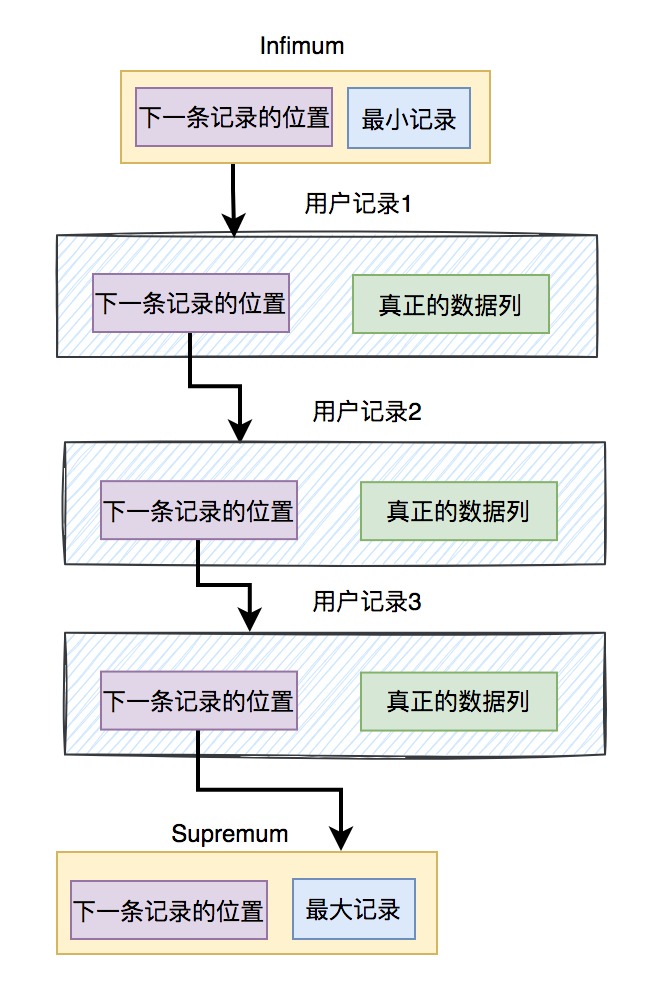
从图中可以看出用户数据是从最小记录开始,通过下一条记录的位置,从小到大,一步步查找,最后找到最大记录为止。 5.页目录