
Hadoop在整个大数据技术体系中占有至关重要的地位,是大数据技术的基础和敲门砖,对Hadoop基础知识的掌握程度会在一定程度决定在大数据技术的道路上能走多远。
最近想要学习Spark,首先需要搭建Spark的环境,Spark的依赖环境比较多,需要Java JDK、Hadoop的支持。我们就分步骤依次介绍各个依赖的安装和配置。新安装了一个Linux Ubuntu 18.04系统,想在此系统上进行环境搭建,详细记录一下过程。
访问Spark的官网,阅读Spark的安装过程,发现Spark需要使用到hadoop,Java JDK等,当然官网也提供了Hadoop free的版本。本文还是从安装Java JDK开始,逐步完成Spark的单机安装。

前往Oracle官网下载JDK8,选择适合自己操作系统的版本,此处选择Linux 64
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
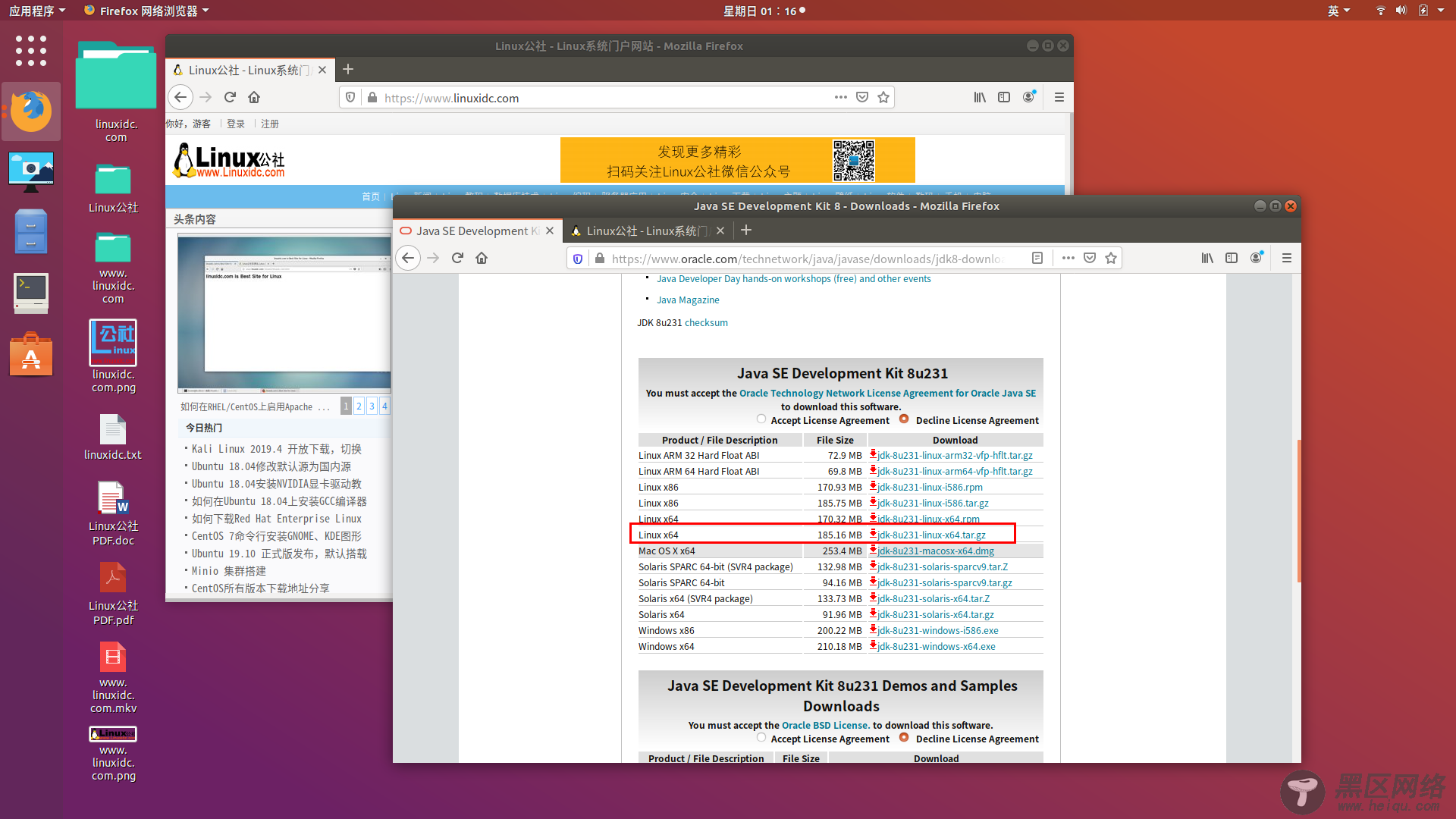
下载之后的包放到某个目录下,此处放在/opt/java目录
linuxidc@linuxidc:~/www.linuxidc.com$ sudo cp /home/linuxidc/www.linuxidc.com/jdk-8u231-linux-x64.tar.gz /opt/java/
[sudo] linuxidc 的密码:
linuxidc@linuxidc:~/www.linuxidc.com$ cd /opt/java/
linuxidc@linuxidc:/opt/java$ ls
jdk-8u231-linux-x64.tar.gz
使用命令:tar -zxvf jdk-8u231-linux-x64.tar.gz 解压缩
linuxidc@linuxidc:/opt/java$ sudo tar -zxf jdk-8u231-linux-x64.tar.gz
linuxidc@linuxidc:/opt/java$ ls
jdk1.8.0_231 jdk-8u231-linux-x64.tar.gz
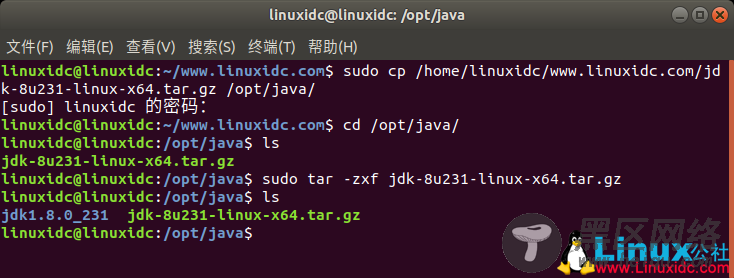

修改配置文件/etc/profile,使用命令:sudo nano /etc/profile
linuxidc@linuxidc:/opt/java$ sudo nano /etc/profile
在文件末尾增加以下内容(具体路径依据环境而定):
export JAVA_HOME=/opt/java/jdk1.8.0_231
export JRE_HOME=/opt/java/jdk1.8.0_231/jre
export PATH=${JAVA_HOME}/bin:$PATH

保存退出,在终端界面使用命令: source /etc/profile 使配置文件生效。
linuxidc@linuxidc:/opt/java$ source /etc/profile
使用java -version验证安装是否成功,以下回显表明安装成功了。
linuxidc@linuxidc:/opt/java$ java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
linuxidc@linuxidc:/opt/java$

前往官网https://hadoop.apache.org/releases.html下载hadoop,此处选择版本2.7.7
hadoop需要ssh免密登陆等功能,因此先安装ssh。
使用命令:
linuxidc@linuxidc:~/www.linuxidc.com$ sudo apt-get install ssh
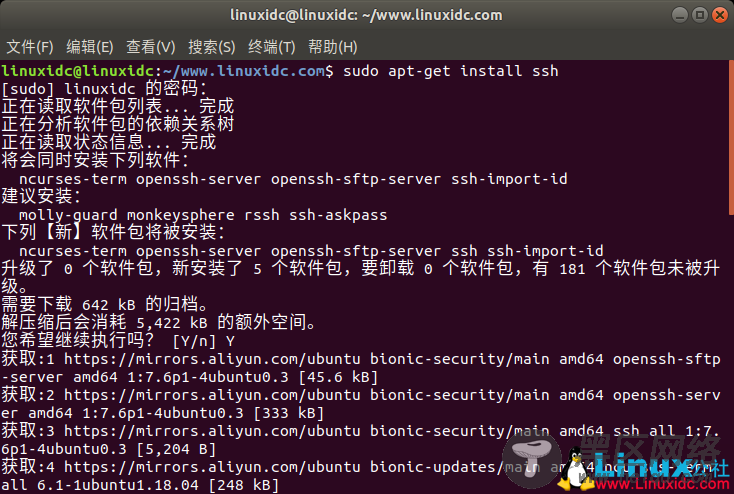
linuxidc@linuxidc:~/www.linuxidc.com$ sudo apt-get install rsync

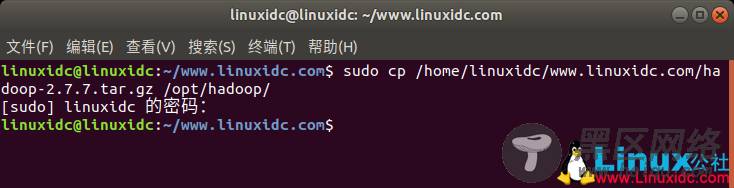
将下载的包放到某个目录下,此处放在/opt/hadoop
linuxidc@linuxidc:~/www.linuxidc.com$ sudo cp /home/linuxidc/www.linuxidc.com/hadoop-2.7.7.tar.gz /opt/hadoop/


使用命令:tar -zxvf hadoop-2.7.7.tar.gz 进行解压缩
此处选择伪分布式的安装方式(Pseudo-Distributed)
修改解压后的目录下的子目录文件 etc/hadoop/hadoop-env.sh,将JAVA_HOME路径修改为本机JAVA_HOME的路径,如下图:

配置Hadoop的环境变量
使用命令:
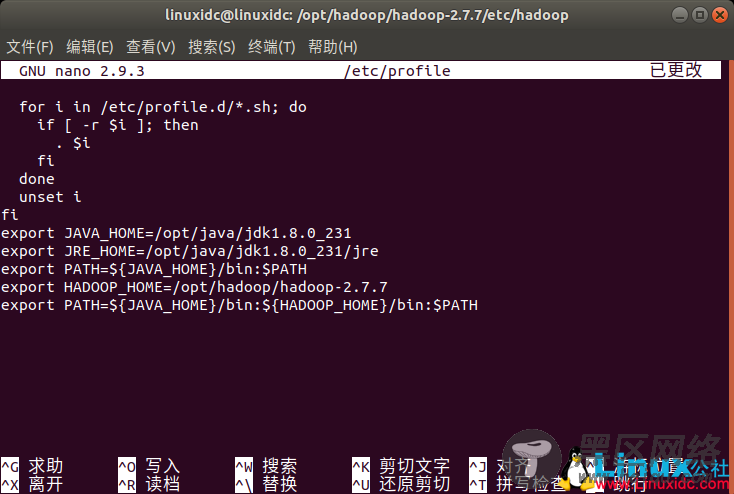
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7/etc/hadoop$ sudo nano /etc/profile
添加以下内容:
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
修改PATH变量,添加hadoop的bin目录进去
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
修改解压后的目录下的子目录文件 etc/hadoop/core-site.xml
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7/etc/hadoop$ sudo nano core-site.xml