
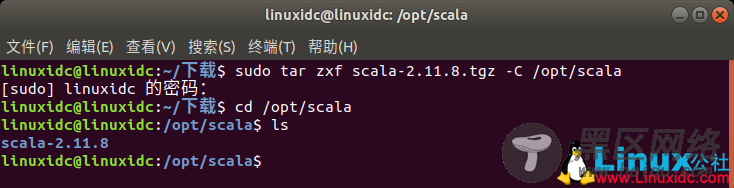
linuxidc@linuxidc:~/下载$ sudo tar zxf scala-2.11.8.tgz -C /opt/scala
[sudo] linuxidc 的密码:
linuxidc@linuxidc:~/下载$ cd /opt/scala
linuxidc@linuxidc:/opt/scala$ ls
scala-2.11.8
配置环境变量:
linuxidc@linuxidc:/opt/scala$ sudo nano /etc/profile
添加:
export SCALA_HOME=/opt/scala/scala-2.11.8

source /etc/profile
4、安装spark前往spark官网下载spark
https://spark.apache.org/downloads.html
此处选择版本如下:
spark-2.4.4-bin-hadoop2.7
将spark放到某个目录下,此处放在/opt/spark
使用命令:tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz 解压缩即可
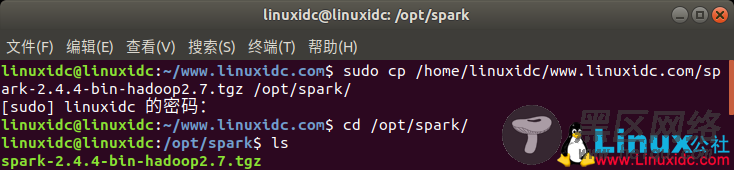
linuxidc@linuxidc:~/www.linuxidc.com$ sudo cp /home/linuxidc/www.linuxidc.com/spark-2.4.4-bin-hadoop2.7.tgz /opt/spark/
[sudo] linuxidc 的密码:
linuxidc@linuxidc:~/www.linuxidc.com$ cd /opt/spark/
linuxidc@linuxidc:/opt/spark$ ls
spark-2.4.4-bin-hadoop2.7.tgz
linuxidc@linuxidc:/opt/spark$ sudo tar -zxf spark-2.4.4-bin-hadoop2.7.tgz
[sudo] linuxidc 的密码:
linuxidc@linuxidc:/opt/spark$ ls
spark-2.4.4-bin-hadoop2.7 spark-2.4.4-bin-hadoop2.7.tgz

使用命令: ./bin/run-example SparkPi 10 测试spark的安装
配置环境变量SPARK_HOME
linuxidc@linuxidc:/opt/spark/spark-2.4.4-bin-hadoop2.7$ sudo nano /etc/profile
export SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SPARK_HOME}/bin:$PATH
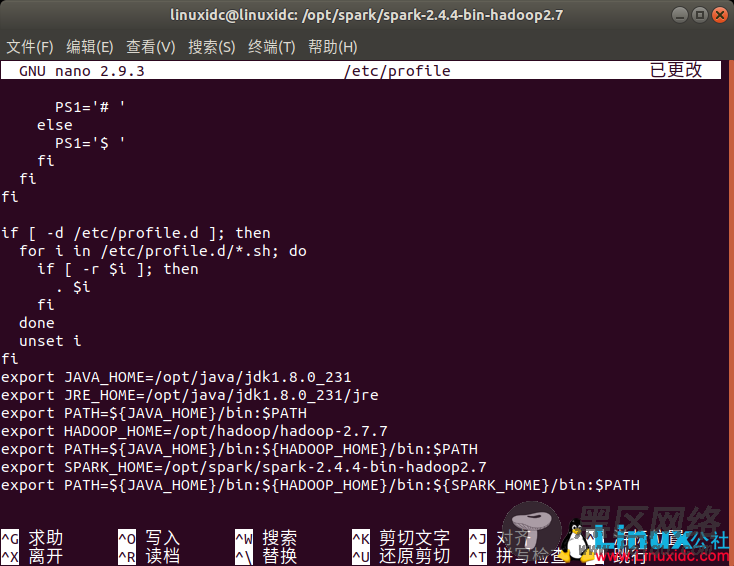
source /etc/profile
配置配置spark-env.sh
进入到spark/conf/
sudo cp /opt/spark/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh.template /opt/spark/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
linuxidc@linuxidc:/opt/spark/spark-2.4.4-bin-hadoop2.7/conf$ sudo nano spark-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_231
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.7/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7
export SCALA_HOME=/opt/scala/scala-2.11.8
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=5G
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native

Java,Hadoop等具体路径根据自己实际环境设置。
启动bin目录下的spark-shell
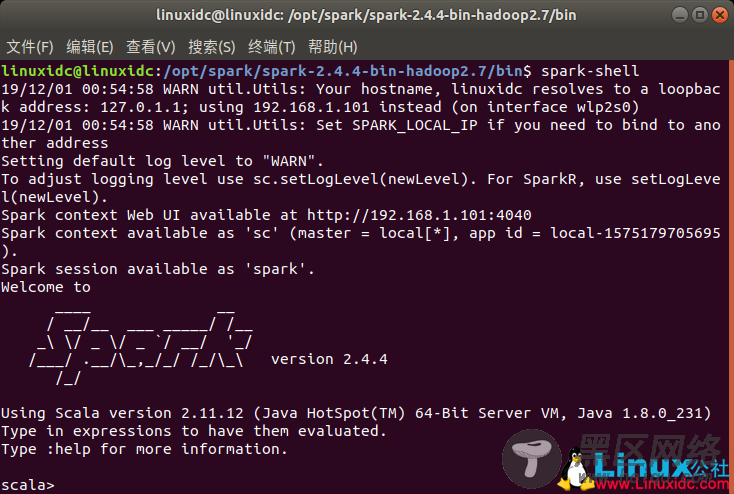
可以看到已经进入到scala环境,此时就可以编写代码啦。
spark-shell的web界面:4040

暂时先这样,如有什么疑问,请在Linux公社下面的评论栏里提出。