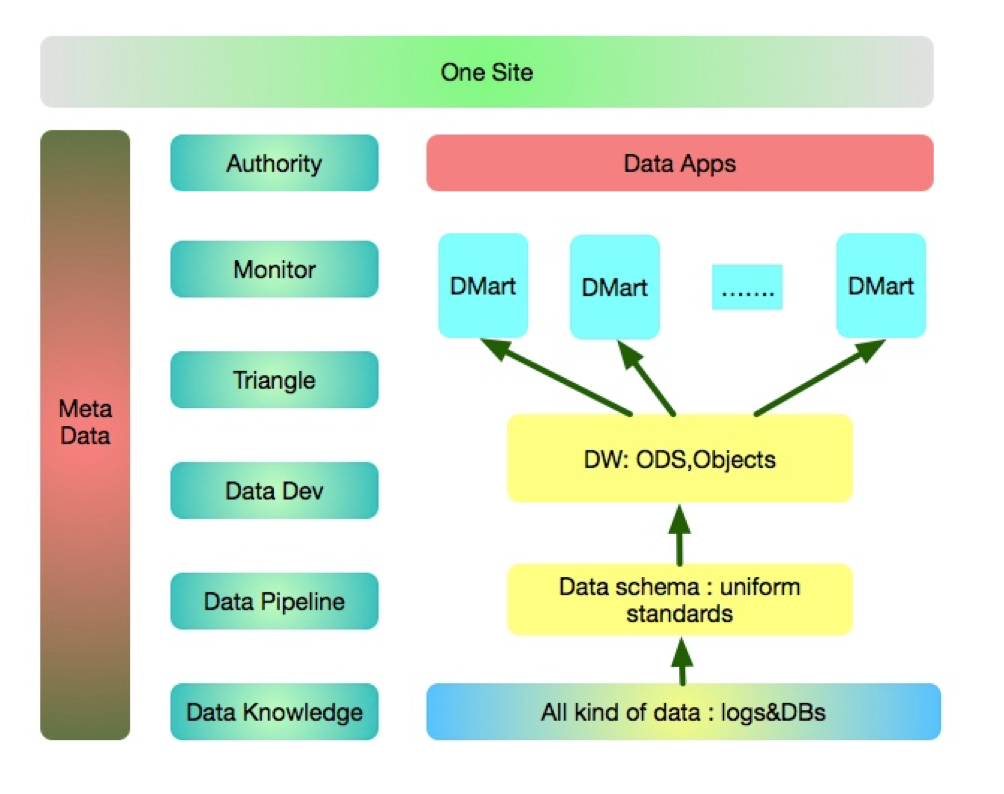
宜人贷属于互联网金融公司,由于带有金融属性,所以对平台的安全性、稳定性、数据质量等方面的要求要高于一般的互联网公司。目前在宜人贷的数据结构中,数据总量为PB级别,每天增量为TB级别。除了结构化的数据之外,还有日志、语音等数据。数据应用类型分为运营和营销两大类,如智能电销、智能营销等。数据服务平台需要保证每天几千个批量作业按时运行,并保证数据产品对数据实时计算的效率以及准确性,与此同时,又要保证每天大量Adhoc查询的实效性。
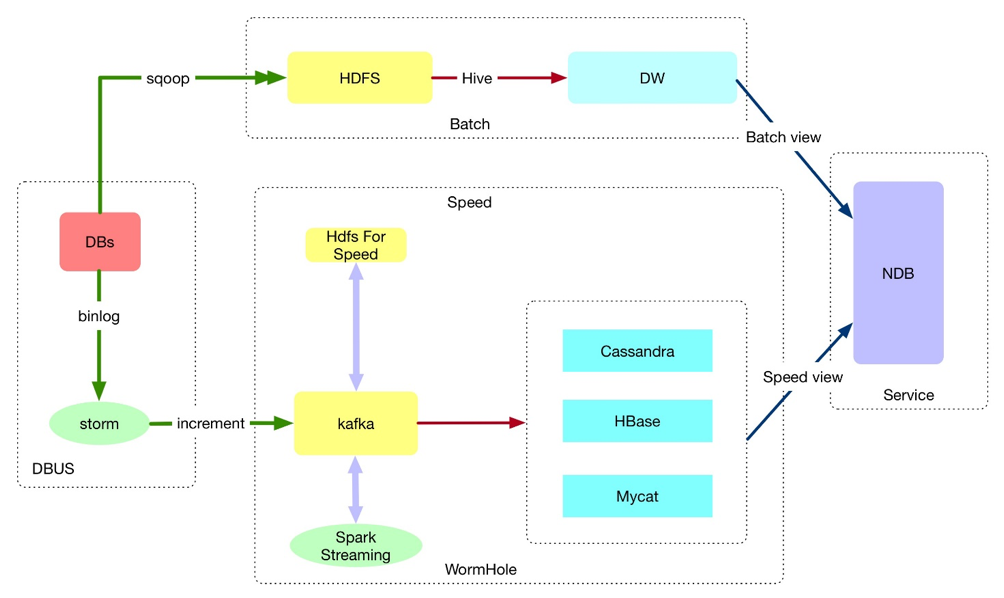
以上是平台底层技术架构图,整体是一个Lambda架构,Batch layer 负责计算t+1的数据,大部分定时报表和数据仓库/集市的主要任务在这一层处理。Speed layer 负责计算实时增量数据,实时数仓,增量实时数据同步,数据产品等主要使用这一层的数据。Batch layer 采用sqoop定时同步到HDFS集群里,然后用Hive和Spark SQL 进行计算。Batch layer的稳定性要比运算速度重要,所以我们主要针对稳定性做了优化。Batch layer的输出就是Batch view。Speed layer 相对Batch layer 来说数据链路会长一些,架构也相对复杂。
DBus和Wormhole是宜信的开源项目,主要用来做数据管道。DBus的基本原理是通过读取数据库的binlog来进行实时的增量数据同步,主要解决的问题是无侵入式的进行增量数据同步。当然也有其他方案,比如卡时间戳,增加trigger等,也能实现增量数据同步,但是对业务库的压力和侵入性太大。Wormhole的基本原理是消费DBus同步过来的增量数据并把这些数据同步给不同的存储,支持同构和异构的同步方式。
总体来说Speed layer 会把数据同步到我们的各种分布式数据库中,这些分布式数据库统一称为Speed view 。然后我们把Batch和Speed的元数据统一抽象出来一层叫Service layer。Service layer 通过NDB对外统一提供服务。因为数据有两个主要属性,即data=when+what。在when这个时间维度上来说数据是不可变的,增删改其实都是产生了新的数据。在平时的数据使用中我们常常只关注what的属性,其实when+what才能确定data的唯一不可变特性。所以按照时间这个维度我们可以对数据进行时间维度的抽象划分,即t+1的数据在Batch view,t+0的数据在Speed view 。这是标准Lambda架构的意图:把离线和实时计算分开。但是我们的Lambda架构有些许差异(此处不做过多表述)。
要知道集群资源是有限的,把离线和实时等计算架构放在一个集群内必然会出现资源抢占的问题。因为每个公司的计算存储方案可能不一样,我在这里仅仅以我们的方案为例,希望能起到抛砖引玉的作用。

要解决抢占问题,首先让我们清晰的认识一下抢占。从用户使用维度上来说,如果平台是多租户的,那么租户之间便存在抢占的可能性;从数据架构上来说,如果离线计算和实时计算没有分开部署,那么也存在抢占的可能性。需要强调的是抢占不仅仅是指cpu和内存资源的抢占,网络io 磁盘的io也是会抢占的。
目前开源市场上的资源调度系统,如yarn,mesos等资源隔离做的都不是很成熟,只能在cpu和内存上做一些轻度隔离(hadoop3.0的 yarn 已经加入了磁盘和网络io的隔离机制)。因为我们的工作基本上是“everything on yarn”,所以我们对yarn进行了修改。对yarn的修改和官方的解决方案类似利用cgroup来实现。对与服务进程间也要用cgroup做好隔离,如datanode nodemanager在一台机器上的时候。