
其实利用日志来构建一个健壮的数据系统是一个很常见的方案。Hbase利用wal来保证可靠性,MySQL主备同步使用binlog,分布式一致性算法Raft利用日志保证一致性,还有Apache Kafka也是利用了日志来实现的。
DBus很好的利用了数据库的binlog日志并且进行统一的schema转化,形成了自己日志标准,以便支持多种数据源。DBus的定义是一个商业级别的数据总线系统。它可以实时的将数据从数据源抽取发送给Kafka。
Wormhole负责将数据同步写入其他的存储之中。Kafka就成了一个真正意义上的数据总线,Wormhole支持sink端按照任意时间开始消费Kafka中的数据,这样也就能很好的进行数据回溯。
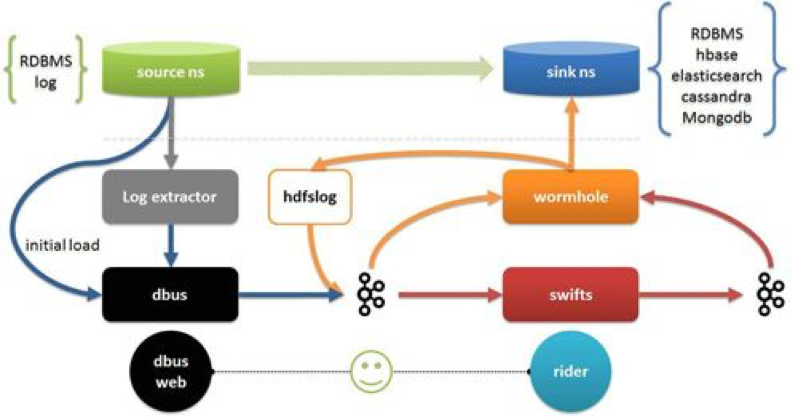
Genie的实时架构如下:
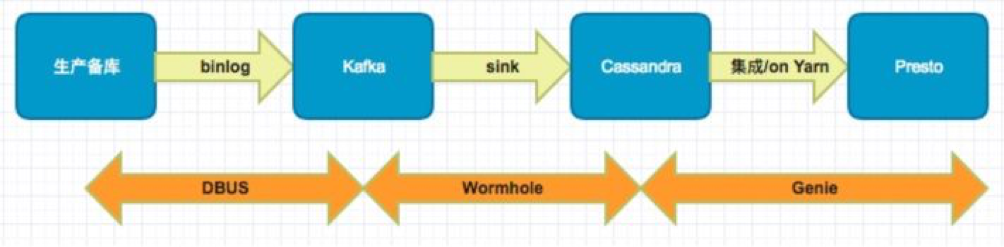
有了DBus和Wormhole我们可以很轻松的把数据从生产备库实时的同步到我们的Cassandra集群,然后再同步Presto,为用户提供SQL语言计算。
通过这个简单的架构我们高效的完成了实时数据仓库的搭建,并且实现了公司的实时报表平台和一些实时营销类的数据产品。
对于为什么会使用Presto我可以给出以下的答案:
Presto拥有交互级别的数据计算查询体验
Presto支持水平扩展,presto on yarn (slider)
支持标准SQL,并且方便扩展
facebook, uber, netflix生产使用
开源语言java符合我们团队技术栈, 自定义函数
支持多数据源关联join 逻辑下推,Presto 可以接Cassandra, Hdfs等等
pipelined executions - 减少了不必要的I/O开销
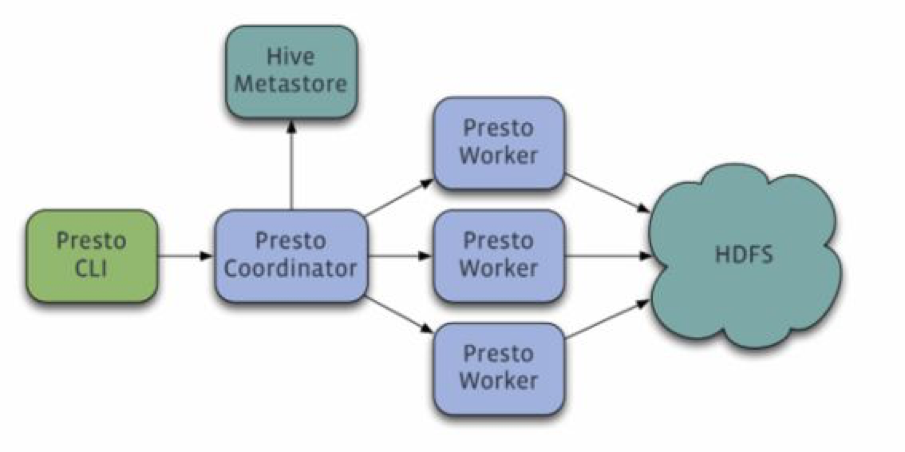
Presto 是m/s架构,整体细节不多说了。Presto有个数据存储抽象层,可以支持不同的数据存储上执行SQL计算。Presto提供了meta data api,data location api, data stream api,支持自开发可插拔的connector。

在我们的方案中是Presto on Cassandra的,因为Cassandra相对于Hbase来说可用性更好一些,比较适合adhoc查询场景。Hbase CAP中偏向c,Cassandra CAP中偏向a。Cassandra是一个非常优秀的数据库,方便易用,底层使用Log-Structured Merge-Tree 做存储索引的核心数据结构。
五、整体数据处理架构综上我大概的介绍了宜人贷的实时数据处理架构,下面我们看一下整体的数据处理架构。
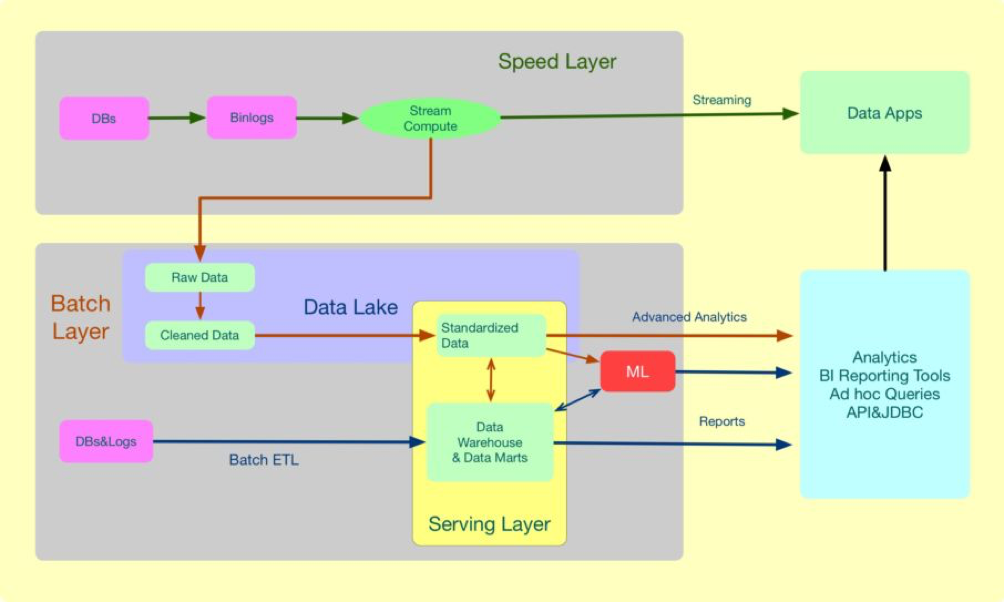
整体Lambda架构speed层利用DBus和Wormhole组装成了一套实时数据总线,speedlayer可以直接支撑实时数据产品。DataLake是一个抽象的概念实现方式,我们主要是利用Hdfs + Cassandra存储数据,计算引擎主要以Hive 和Presto为主,再通过平台统一的metadata对元数据整合提供,这样就实现了一个完整的DataLake。DataLake主要的应用场景是高级灵活的分析,查询场景如 ml 。
DataLake和数据仓库的区别是,DataLake更加敏捷灵活,侧重数据的获取,数据仓库则侧重于标准、管理、安全和快速索引。
六、数据平台Genie的功能模块整个Genie数据服务平台由7个大的子平台模块组成:
数据查询
数据知识
实时报表
数据开发
作业调度
权限管理
集群监控管理
下面我们来介绍一下其中的几个模块。
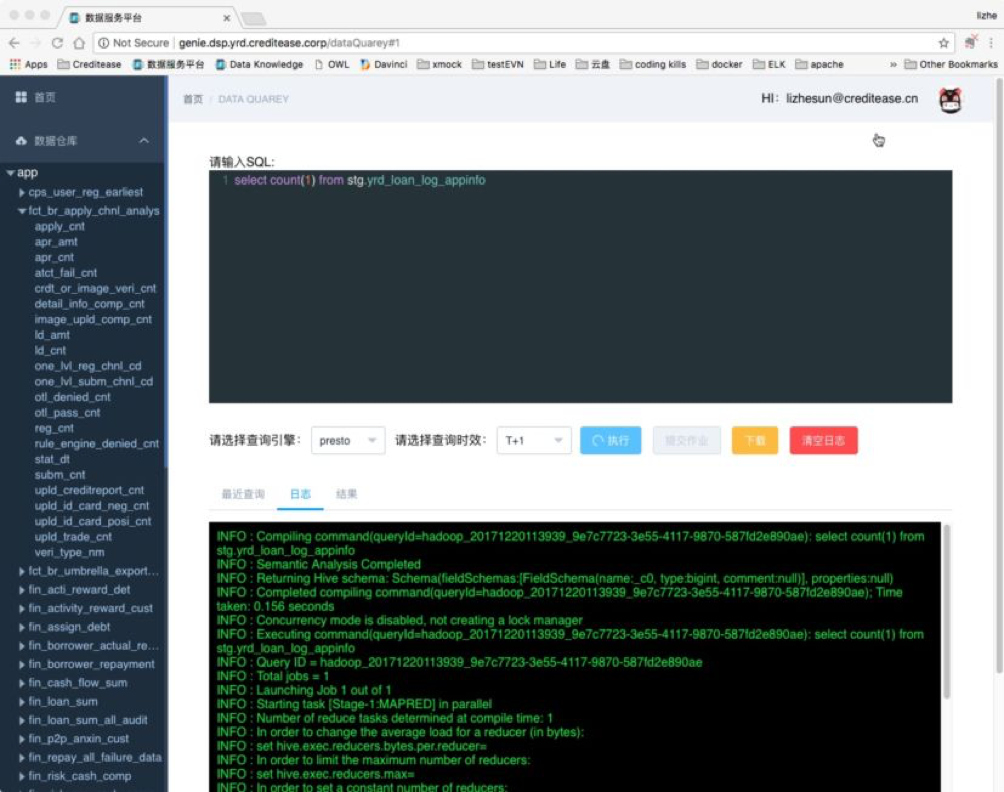
6.1 数据查询模块
用户可以查询数据仓库、数据集市、实时数据仓库的数据
通过对SQL的解析来实现细粒度的权限管理
提供多种查询引擎
数据导出
元数据监控管理
对全公司的元数据提供管理查询功能
可以监控元数据变更并预警邮件
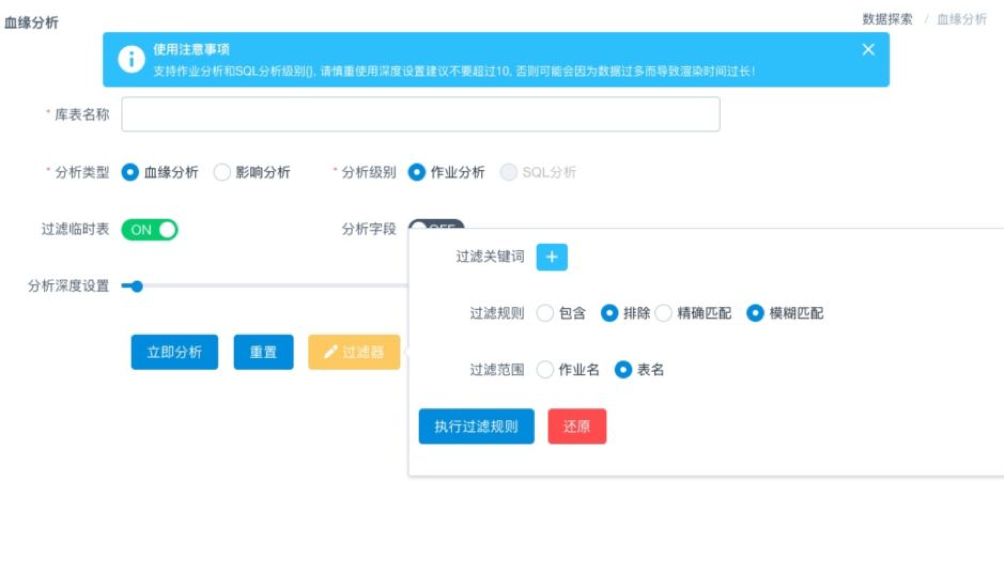
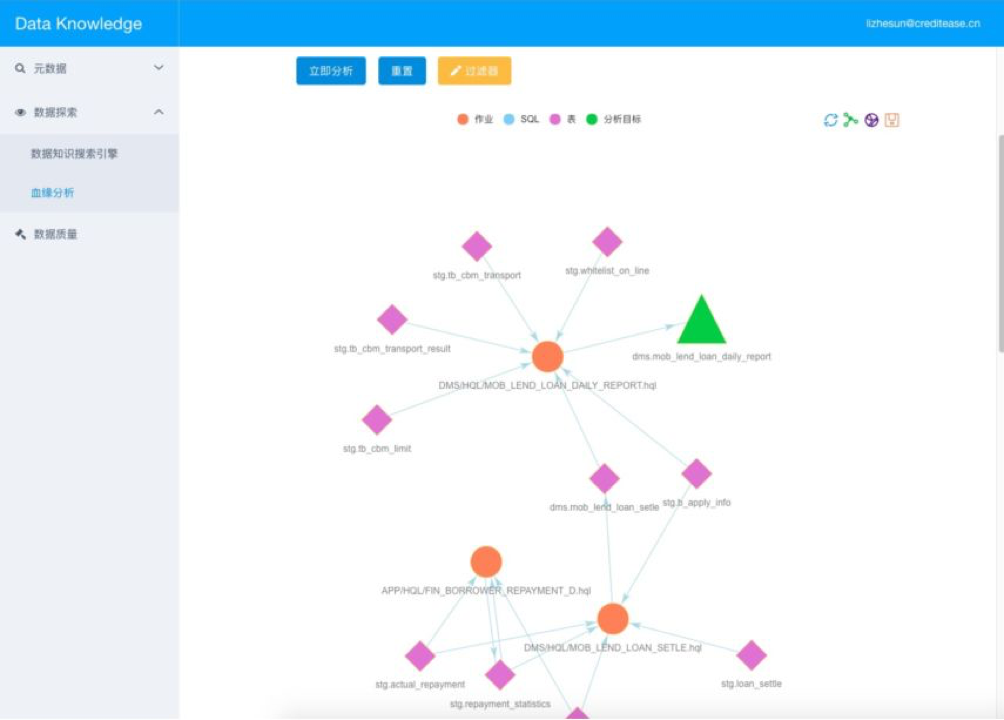
血缘分析查询引擎
SQL分析引擎
对仓库所有的作业/表/字段进行分析
提供血缘分析/影响分析

实时数据仓库
Presto on Cassandra直连Presto
数百张表,实时同步(DBus+WHurl)
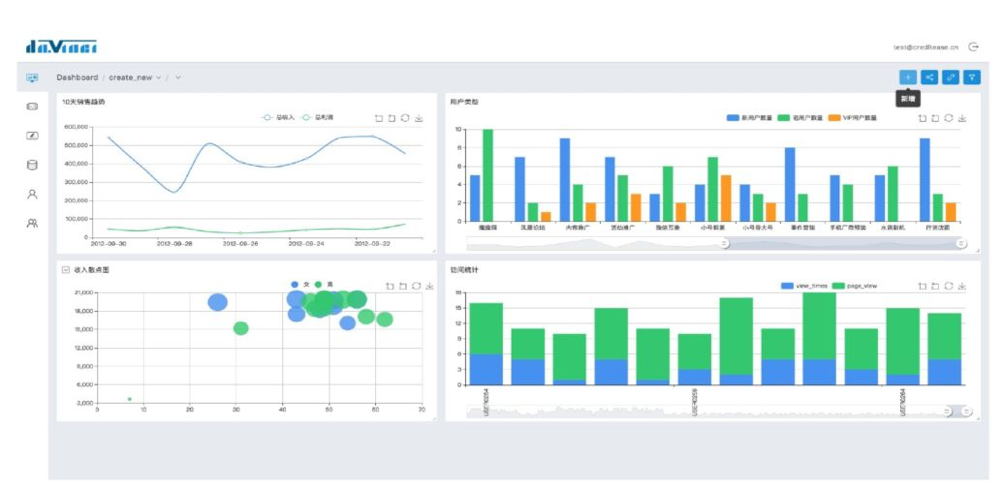
达芬奇报表平台 (达芬奇url)
近千张报表全公司已使用
数据程序设计 Genie-ide
提供Genie-ide进行数据程序的开发
提供网盘进行脚本保存管理
可以实时测试/上线
数据管道
一键离线入仓
一键实时入仓

微服务架构设计每个模块均为一个服务
提供restful接口可以方便二次开发与其它平台融合
提供健康监控作业管理后台
提供公共作业和私有作业
作业流之间逻辑隔离
并发控制,失败策略管理
以上是对数据平台Genie模块功能的简介,那Genie平台具体可以做哪些事情呢?
首先,它可以实现离线入仓,实时入仓 1分钟内配置完成(数据仓库,数据集市);
其次,实时入仓后可直接配置实时报表展示推送(BI分析);
第三,实时数据支持多种含有权限安全的同构对接方式:api ,kafka, jdbc(业务数据产品);
第四,一站式数据开发支持hive,spark-sql,presto on cassandra,python(数据开发);
第五,服务化的调度系统支持外部系统接入(基础技术组件)。
参考文献:https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
https://engineering.linkedin.com/data-replication/open-sourcing-databus-linkedins-low-latency-change-data-capture-system
https://yq.aliyun.com/articles/195388
https://www.cnblogs.com/tgzhu/p/6033373.html