
webpack作为前端最火的构建工具,是前端自动化工具链最重要的部分,使用门槛较高。本系列是笔者自己的学习记录,比较基础,希望通过问题 + 解决方式的模式,以前端构建中遇到的具体需求为出发点,学习webpack工具中相应的处理办法。(本篇中的参数配置及使用方式均基于webpack4.0版本)
本篇摘要:
本篇主要介绍基于webpack4.0的splitChunks分包技术。

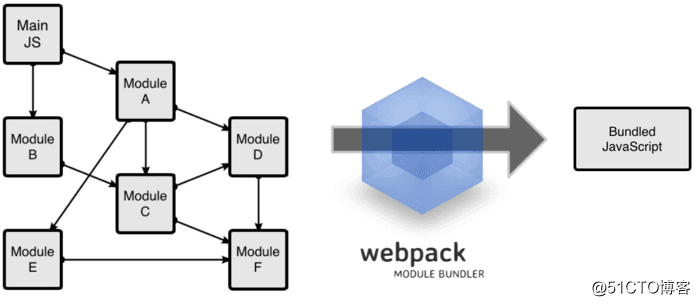
javascript之所以需要打包合并,是因为模块化开发的存在。开发阶段我们需要将js文件分开写在很多零碎的文件中,方便调试和修改,但如果就这样上线,那首页的http请求数量将直接爆炸。同一个项目,别人2-3个请求就拿到了需要的文件,而你的可能需要20-30个,结果就不用多说了。
但是合并脚本可不是“把所有的碎片文件都拷贝到一个js文件里”这样就能解决的,不仅要解决命名空间冲突的问题,还需要兼容不同的模块化方案,更别提根据模块之间复杂的依赖关系来手动确定模块的加载顺序了,所以利用自动化工具来将开发阶段的js脚本碎片进行合并和优化是非常有必要的。
二. Js文件的一般打包需求代码编译(TS或ES6代码的编译)
脚本合并
公共模块识别
代码分割
代码压缩混淆
三. 使用webpack处理js文件 3.1 使用babel转换ES6+语法babel是ES6语法的转换工具,对babel不了解的读者可以先阅读《大前端的自动化工厂(3)——Babel》一文进行了解,babel与webpack结合使用的方法也在其中做了介绍,此处仅提供基本配置:
webpack.config.js:
... module: { rules: [ { test: /\.js$/, exclude: /node_modules/, use: [ { loader: 'babel-loader' } ] } ] }, ....babelrc:
{ "presets":[ ["env",{ "targets":{ "browsers":"last 2 versions" } } ]], "plugins": [ "babel-plugin-transform-runtime" ] } 3.2 脚本合并使用webpack对脚本进行合并是非常方便的,毕竟模块管理和文件合并这两个功能是webpack最初设计的主要用途,直到涉及到分包和懒加载的话题时才会变得复杂。webpack使用起来很方便,是因为实现了对各种不同模块规范的兼容处理,对前端开发者来说,理解这种兼容性实现的方式比学习如何配置webpack更为重要。webpack默认支持的是CommonJs规范,但同时为了扩展其使用场景,webpack在后续的版本迭代中也加入了对ES harmony等其他规范定义模块的兼容处理,具体的处理方式将在下一章《webpack4.0各个击破(5)—— Module篇》详细分析。
3.3 公共模块识别webpack的输出的文件中可以看到如下的部分:
/******/ function __webpack_require__(moduleId) { /******/ /******/ // Check if module is in cache /******/ if(installedModules[moduleId]) { /******/ return installedModules[moduleId].exports; /******/ } /******/ // Create a new module (and put it into the cache) /******/ var module = installedModules[moduleId] = { /******/ i: moduleId, /******/ l: false, /******/ exports: {} /******/ }; /******/ /******/ // Execute the module function /******/ modules[moduleId].call(module.exports, module, module.exports, __webpack_require__); /******/ /******/ // Flag the module as loaded /******/ module.l = true; /******/ /******/ // Return the exports of the module /******/ return module.exports; /******/ }上面的__webpack_require__( )方法就是webpack的模块加载器,很容易看出其中对于已加载的模块是有统一的installedModules对象来管理的,这样就避免了模块重复加载的问题。而公共模块一般也需要从bundle.js文件中提取出来,这涉及到下一节的“代码分割”的内容。
3.4 代码分割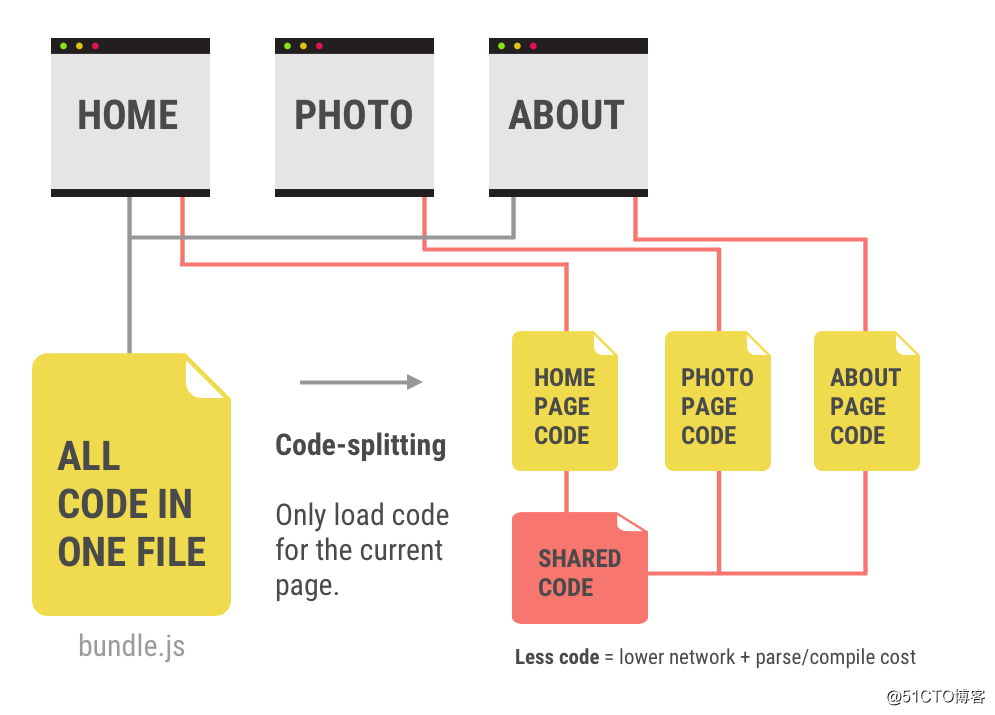
1. 为什么要进行代码分割?
代码分割最基本的任务是分离出第三方依赖库,因为第三方库的内容可能很久都不会变动,所以用来标记变化的摘要哈希contentHash也很久不变,这也就意味着我们可以利用本地缓存来避免没有必要的重复打包,并利用浏览器缓存避免冗余的客户端加载。另外当项目发布新版本时,如果第三方依赖的contentHash没有变化,就可以使用客户端原来的缓存文件(通用的做法一般是给静态资源请求设置一个很大的max-age),提升访问速度。另外一些场景中,代码分割也可以提供对脚本在整个加载周期内的加载时机的控制能力。
2. 代码分割的使用场景