
极富远见的马云爸爸此时喊出了「数据中台」的概念,「One Data,One Service」的口号开始响彻大数据界。数据中台的核心思想是:避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能业务。
02 大数据的核心概念了解了大数据的发展历史后,再解释下大数据的几个核心概念。
2.1 究竟什么是大数据?大数据是一种海量的、高增长率的、多样化的信息资产,它需要新的存储和计算模式才能具有更强的决策力、流程优化能力。
下面是大数据的4个典型特征:

Volume:海量的数据规模,数据体量达到PB甚至EB级别。
Variety:异构的数据类型,不仅仅包含结构化的数据、还包括半结构化和非结构化数据,比如日志文件、图像、音视频等。
Velocity:快速的数据流转,数据的产生和处理速度非常快。
Value:价值密度低,有价值的数据占比很小,需要用到人工智能等方法去挖掘新知识。
2.2 什么又是数据仓库?数据仓库是面向主题的、集成的、随着时间变化的、相对稳定的数据集合。
简单理解,数据仓库是大数据的一种组织形式,有利于对海量数据的维护和进一步分析 。
面向主题的:表示按照主题或者业务场景组织数据。
集成的:从多个异构数据源采集数据,进行抽取、加工、集成。
随时间变化的:关键数据需要标记时间属性。
相对稳定的:极少进行数据删除和修改,而只是进行数据新增。
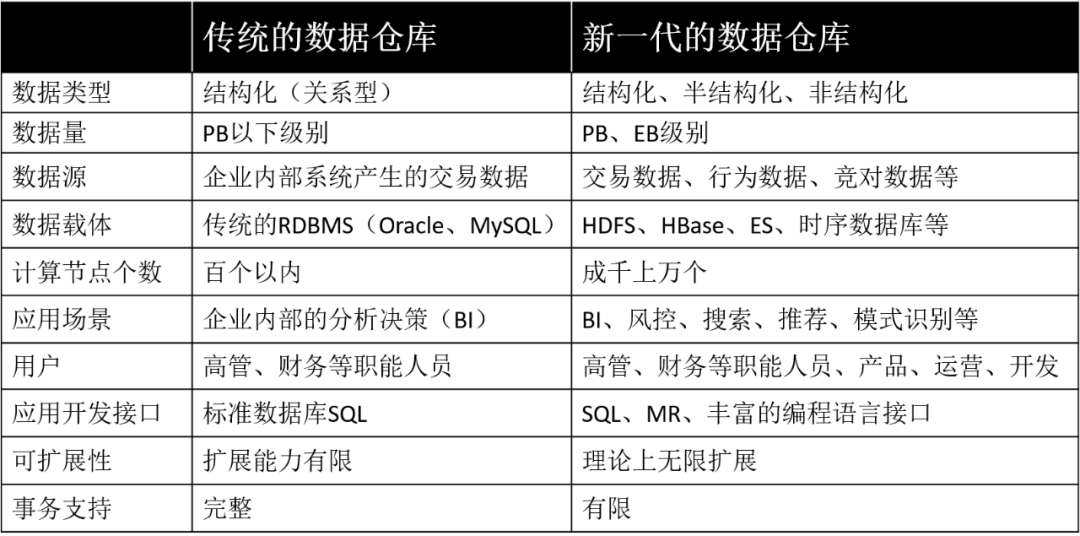
2.3 传统数据仓库 vs 新一代数据仓库随着大数据时代的到来,传统数据仓库和新一代数据仓库必然有很多不同,下面从多维度对比下两代数据仓库的异同。
前面谈到大数据相关的技术有几十种,下面通过大数据平台的通用架构来了解下整个技术体系。
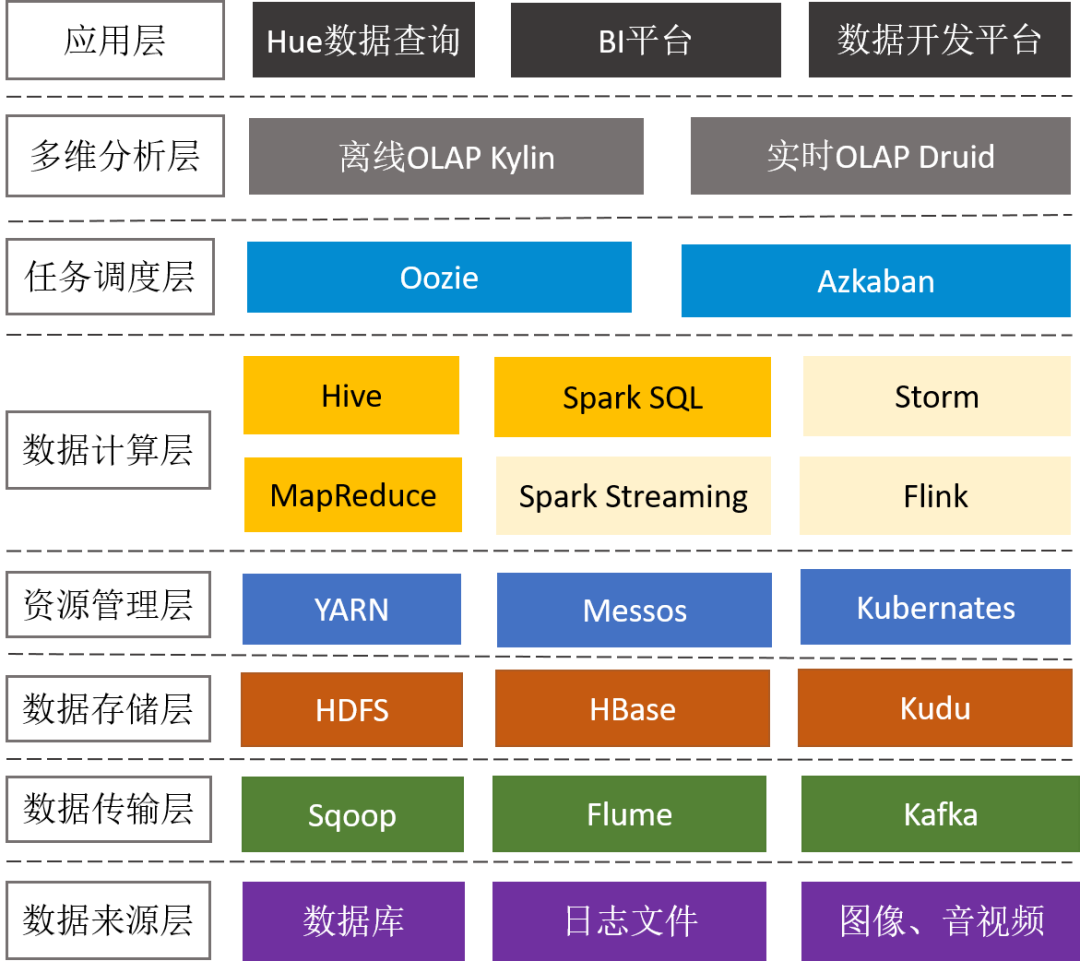
Sqoop:支持RDBMS和HDFS之间的双向数据迁移,通常用于抽取业务数据库(比如MySQL、SQLServer、Oracle)的数据到HDFS.
Cannal:阿里开源的数据同步工具,通过监听MySQL binlog,实现增量数据订阅和近实时同步。
Flume:用于海量日志采集、聚合和传输,将产生的数据保存到HDFS或者HBase中。
Flume + Kafka:满足实时流式日志的处理,后面再通过Spark Streaming等流式处理技术,可完成日志的实时解析和应用。
3.2 数据存储层HDFS:分布式文件系统,它是分布式计算中数据存储管理的基础,是Google GFS的开源实现,可部署在廉价商用机器上,具备高容错、高吞吐和高扩展性。
HBase:分布式的、面向列的NoSQL KV数据库, 它是Google BigTable的开源实现,利用HDFS作为其文件存储系统,适合大数据的实时查询(比如:IM场景)。
Kudu:折中了HDFS和HBase的分布式数据库,既支持随机读写、又支持OLAP分析的大数据存储引擎(解决HBase不适合批量分析的痛点)。
3.3 资源管理层Yarn:Hadoop的资源管理器,负责Hadoop集群资源的统一管理和调度,为运算程序(MR任务)提供服务器运算资源(CPU、内存),能支持MR、Spark、Flink等多种框架。
Kubernates:由Google开源,一种云平台的容器化编排引擎,提供应用的容器化管理,可在不同云、不同版本操作系统之间进行迁移。目前,Spark、Storm已经支持K8S。
3.4 数据计算层大数据计算引擎决定了计算效率,是大数据平台最核心的部分,它大致了经历以下4代的发展,又可以分成离线计算框架和实时计算框架。
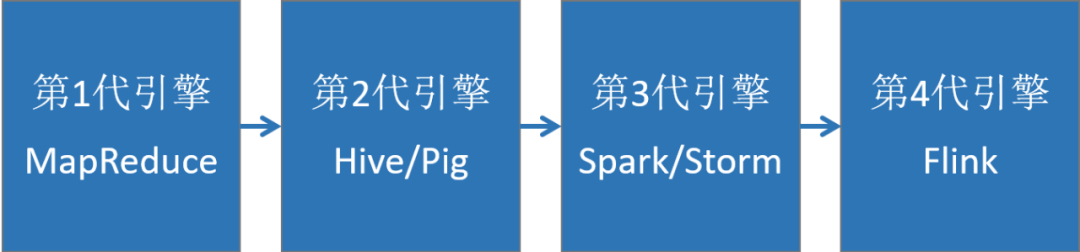
MapReduce:面向大数据并行处理的计算模型、框架和平台(将计算向数据靠拢、减少数据传输,这个设计思路非常巧妙)。
Hive:一个数据仓库工具,能管理HDFS存储的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能(实际运行时,是将Hive SQL翻译成了MapReduce任务),适用离线非实时数据分析。
Spark sql:引入RDD(弹性分布式数据集)这一特殊的数据结构,将SQL转换成RDD的计算,并将计算的中间结果放在内存中,因此相对于Hive性能更高,适用实时性要求较高的数据分析场景。
3.4.2 实时计算框架