
Spark Streaming:实时流数据处理框架(按时间片分成小批次,s级延迟),可以接收Kafka、Flume、HDFS等数据源的实时输入数据,经过处理后,将结果保存在HDFS、RDBMS、HBase、Redis、Dashboard等地方。
Storm:实时流数据处理框架,真正的流式处理,每条数据都会触发计算,低延迟(ms级延迟)。
Flink:更高级的实时流数据处理框架,相比Storm,延迟比storm低,而且吞吐量更高,另外支持乱序和调整延迟时间。
3.5 多维分析层Kylin:分布式分析引擎,能在亚秒内查询巨大的Hive表,通过预计算(用空间换时间)将多维组合计算好的结果保存成Cube存储在HBase中,用户执行SQL查询时,将SQL转换成对Cube查询,具有快速查询和高并发能力。
Druid:适用于实时数据分析的高容错、高性能开源分布式系统,可实现在秒级以内对十亿行级别的表进行任意的聚合分析。
04 大数据的通用处理流程了解了大数据平台的通用架构和技术体系后,下面再看下针对离线数据和实时数据,是如何运用大数据技术进行处理的?
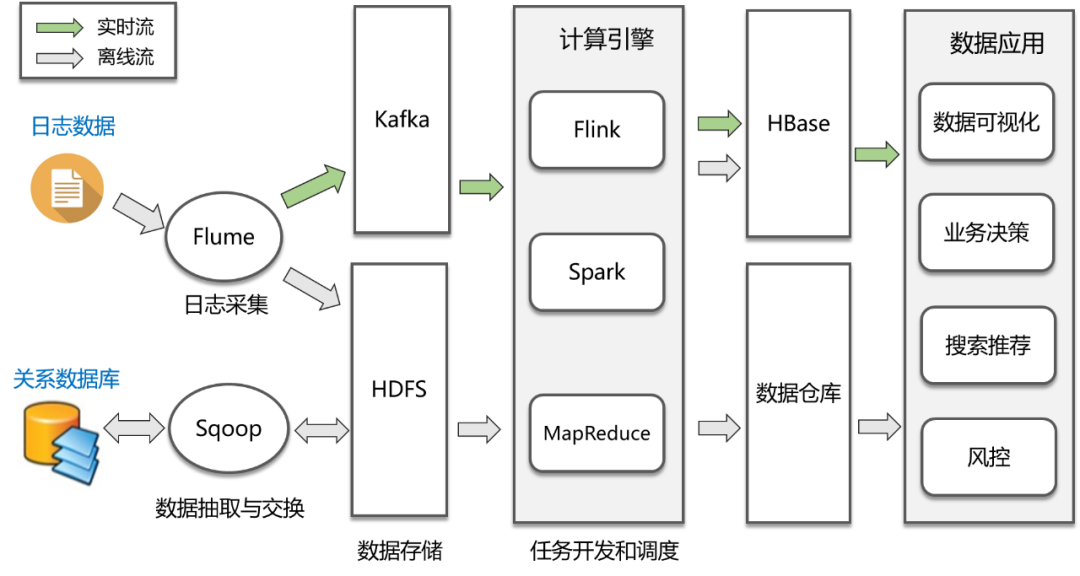
上图是一个通用的大数据处理流程,主要包括以下几个步骤:
数据采集:这是大数据处理的第一步,数据来源主要是两类,第一类是各个业务系统的关系数据库,通过Sqoop或者Cannal等工具进行定时抽取或者实时同步;第二类是各种埋点日志,通过Flume进行实时收集。
数据存储:收集到数据后,下一步便是将这些数据存储在HDFS中,实时日志流情况下则通过Kafka输出给后面的流式计算引擎。
数据分析:这一步是数据处理最核心的环节,包括离线处理和流处理两种方式,对应的计算引擎包括MapReduce、Spark、Flink等,处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
数据应用:包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
05 大数据下的数仓体系架构数据仓库是从业务角度出发的一种数据组织形式,它是大数据应用和数据中台的基础。数仓系统一般采用下图所示的分层结构。

可以看到,数仓系统分成了4层:源数据层、数据仓库层、数据集市层、数据应用层。采用这样的分层结构,和软件设计的分层思想类似,都是为了将复杂问题简单化,每一层职责单一,提高了维护性和复用性。每一层的具体作用如下:
ODS:源数据层,源表。
DW:数据仓库层,包含维度表和事实表,通过对源表进行清洗后形成的数据宽表,比如:城市表、商品类目表、后端埋点明细表、前端埋点明细表、用户宽表、商品宽表。
DM:数据集市层,对数据进行了轻粒度的汇总,由各业务方共建,比如:用户群分析表、交易全链路表。
ADS:数据应用层,根据实际应用需求生成的各种数据表。
另外,各层的数据表都会采用统一的命名规则进行规范化管理,表名中会携带分层、主题域、业务过程以及分区信息。比如,对于交易域下的一张曝光表,命名可以是这样:

上文对大数据的历史、核心概念、通用架构、以及技术体系进行了系统性总结。如果大家想深入学习大数据技术,建议参考这篇文章,同时结合下面的学习指南展开。

后续会持续带来大数据方向更深度的分享,如果感兴趣,欢迎关注我。