
输出示例:
//main线程在初始化 JVM 的时候,分配了一些其他对象,所以这里 weight 很大 jdk.ObjectAllocationSample { startTime = 10:16:24.677 //触发本次事件的对象的类 objectClass = byte[] (classLoader = bootstrap) //注意,这个不是对象大小,而是该线程距离上次被采集 jdk.ObjectAllocationSample 事件到这个事件的这段时间,线程分配的对象总大小 weight = 15.9 MB eventThread = "main" (javaThreadId = 1) stackTrace = [ com.github.hashjang.jfr.test.TestObjectAllocationSample.main(String[]) line: 42 ] } jdk.ObjectAllocationSample { startTime = 10:16:25.690 objectClass = byte[] (classLoader = bootstrap) weight = 10.0 MB eventThread = "main" (javaThreadId = 1) stackTrace = [ com.github.hashjang.jfr.test.TestObjectAllocationSample.main(String[]) line: 42 ] } jdk.ObjectAllocationSample { startTime = 10:16:26.702 objectClass = byte[] (classLoader = bootstrap) weight = 1.0 MB eventThread = "Thread-0" (javaThreadId = 27) stackTrace = [ com.github.hashjang.jfr.test.TestObjectAllocationSample.lambda$main$0() line: 48 java.lang.Thread.run() line: 831 ] } jdk.ObjectAllocationSample { startTime = 10:16:27.718 objectClass = byte[] (classLoader = bootstrap) weight = 10.0 MB eventThread = "Thread-0" (javaThreadId = 27) stackTrace = [ com.github.hashjang.jfr.test.TestObjectAllocationSample.lambda$main$0() line: 48 java.lang.Thread.run() line: 831 ] }各位读者可以将采集频率改成 "100/s",就能看到基本所有代码里面的对象分配都被采集成为一个事件了。
底层原理与相关 JVM 源码首先我们来看下 Java 对象分配的流程:
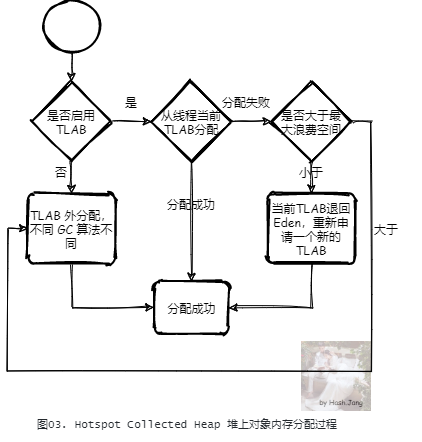
对于 HotSpot JVM 实现,所有的 GC 算法的实现都是一种对于堆内存的管理,也就是都实现了一种堆的抽象,它们都实现了接口 CollectedHeap。当分配一个对象堆内存空间时,在 CollectedHeap 上首先都会检查是否启用了 TLAB,如果启用了,则会尝试 TLAB 分配;如果当前线程的 TLAB 大小足够,那么从线程当前的 TLAB 中分配;如果不够,但是当前 TLAB 剩余空间小于最大浪费空间限制,则从堆上(一般是 Eden 区) 重新申请一个新的 TLAB 进行分配。否则,直接在 TLAB 外进行分配。TLAB 外的分配策略,不同的 GC 算法不同。例如G1:
如果是 Humongous 对象(对象在超过 Region 一半大小的时候),直接在 Humongous 区域分配(老年代的连续区域)。
根据 Mutator 状况在当前分配下标的 Region 内分配
jdk.ObjectAllocationSample 事件只关心 TLAB 外分配,因为这也是程序主要需要的优化点。throttle 配置,是限制在一段时间内只能采集这么多的事件。但是我们究竟怎么筛选采集哪些事件呢?假设我们配置的是 100/s,首先想到的是时间窗口,采集这一窗口内开头的 100 个事件。这样显然是不符合我们的要求的,我们并不能保证性能瓶颈的事件就在每秒的前 100 个,并且我们的程序可能每秒发生很多很多次 TLAB 外分配,仅凭前 100 个事件并不能很好的采集我们想看到的事件。所以,JDK 内部通过 EWMA(Exponential Weighted Moving Average)的算法估计何时的采集时间以及越大分配上报次数越多的这样的优化来实现更准确地采样。
如果是直接在 TLAB 外进行分配,才可能生成 jdk.ObjectAllocationSample 事件。
参考源码: