
allocTracer.cpp
//在每次发生 TLAB 外分配的时候,调用这个方法上报 void AllocTracer::send_allocation_outside_tlab(Klass* klass, HeapWord* obj, size_t alloc_size, Thread* thread) { JFR_ONLY(JfrAllocationTracer tracer(obj, alloc_size, thread);) //立刻生成 jdk.ObjectAllocationOutsideTLAB 这个事件 EventObjectAllocationOutsideTLAB event; if (event.should_commit()) { event.set_objectClass(klass); event.set_allocationSize(alloc_size); event.commit(); } //归一化分配数据并采样 jdk.ObjectAllocationSample 事件 normalize_as_tlab_and_send_allocation_samples(klass, static_cast<intptr_t>(alloc_size), thread); }再来看归一化分配数据并生成 jdk.ObjectAllocationSample 事件的具体内容:
static void normalize_as_tlab_and_send_allocation_samples(Klass* klass, intptr_t obj_alloc_size_bytes, Thread* thread) { //读取当前线程分配过的字节大小 const int64_t allocated_bytes = load_allocated_bytes(thread); assert(allocated_bytes > 0, "invariant"); // obj_alloc_size_bytes is already attributed to allocated_bytes at this point. //如果没有使用 TLAB,那么不需要处理,allocated_bytes 肯定只包含 TLAB 外分配的字节大小 if (!UseTLAB) { //采样 jdk.ObjectAllocationSample 事件 send_allocation_sample(klass, allocated_bytes); return; } //获取当前线程的 TLAB 期望大小 const intptr_t tlab_size_bytes = estimate_tlab_size_bytes(thread); //如果当前线程分配过的字节大小与上次读取的当前线程分配过的字节大小相差不超过 TLAB 期望大小,证明可能是由于 TLAB 快满了导致的 TLAB 外分配,并且大小不大,没必要上报。 if (allocated_bytes - _last_allocated_bytes < tlab_size_bytes) { return; } assert(obj_alloc_size_bytes > 0, "invariant"); //利用这个循环,如果当前线程分配过的字节大小越大,则采样次数越多,越容易被采集到。 do { if (send_allocation_sample_with_result(klass, allocated_bytes)) { return; } obj_alloc_size_bytes -= tlab_size_bytes; } while (obj_alloc_size_bytes > 0); }这里我们就观察到了 JDK 做的第一个上报优化算法:如果本次分配对象大小越大,那么这个循环次数就会越多,采样次数就越多,被采集到的概率也越大
接下来来看具体的采样方法:
通过这里的代码我们明白了:
ObjectClass 是 TLAB 外分配对象的 class,也是本次触发记录jdk.ObjectAllocationSample 事件的对象的 class
weight 是线程距离上次记录 jdk.ObjectAllocationSample 事件到当前这个事件时间内,线程分配的对象大小。
这里通常会误以为 weight 就是本次事件 ObjectClass 的对象大小。这个需要着重注意下。
那么如何判断的事件是否应该 commit? 这里走的是 JFR 通用逻辑:
jfrEvent.hpp
这里涉及 JfrEventThrottler 控制实现 throttle 配置。主要通过 EWMA 算法实现对于下次合适的采集时间间隔的不断估算优化更新,来采集到最合适的 jdk.ObjectAllocationSample,同时这种算法并不像滑动窗口那样记录历史数据导致占用很大内存,指数移动平均(exponential moving average),或者叫做指数加权移动平均(exponentially weighted moving average),是以指数式递减加权的移动平均,各数值的加权影响力随时间呈指数式递减,可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
假设每次采集数据为 P(n),权重衰减程度为 t,t 在 0~1 之间:
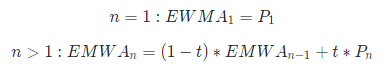
上面的公式,也可以写作: