
dump 快照之后通过 JProfiler 或 MAT 观察 Classes 的 Histogram(直方图)即可,或者直接通过命令即可定位, jcmd 打几次 Histogram 的图,看一下具体是哪个包下的 Class 增加较多就可以定位了。
jcmd <PID> GC.class_stats|awk '{print$13}'|sed 's/\(.*\)\.\(.*\)/\1/g'|sort |uniq -c|sort -nrk1经常会出问题的几个点有 Orika 的 classMap、JSON 的 ASMSerializer、Groovy 动态加载类等,基本都集中在反射、Javasisit 字节码增强、CGLIB 动态代理、OSGi 自定义类加载器等的技术点上。
过早晋升现象
分配速率接近于晋升速率,对象晋升年龄较小
Full GC 比较频繁,且经历过一次 GC 之后 Old 区的变化比例非常大
原因分析及策略
Young/Eden 区过小:一般情况下 Old 的大小应当为活跃对象的 2~3 倍左右,考虑到浮动垃圾问题最好在 3 倍左右,剩下的都可以分给 Young 区
分配速率过大:
偶发较大:通过内存分析工具找到问题代码,从业务逻辑上做一些优化
一直较大:当前的 Collector 已经不满足应用程序的期望了,这种情况要么增加应用程序的 机器,要么调整 GC 收集器类型或加大空间
CMS Old GC频繁现象
Old 区频繁的做 CMS GC,但是每次耗时不是特别长,整体最大 STW 也在可接受范围内,但由于 GC 太频繁导致吞吐下降比较多。
原因分析
基本都是一次 Young GC 完成后,负责处理 CMS GC 的一个后台线程 concurrentMarkSweepThread 会不断地轮询,使用 shouldConcurrentCollect() 方法做一次检测,判断是否达到了回收条件。如果达到条件(参考上文中CMS GC触发条件),使用 collect_in_background() 启动一次 Background 模式 GC。轮询的判断是使用 sleepBeforeNextCycle() 方法,间隔周期为 -XX:CMSWaitDuration 决定,默认为2s。
解决方案
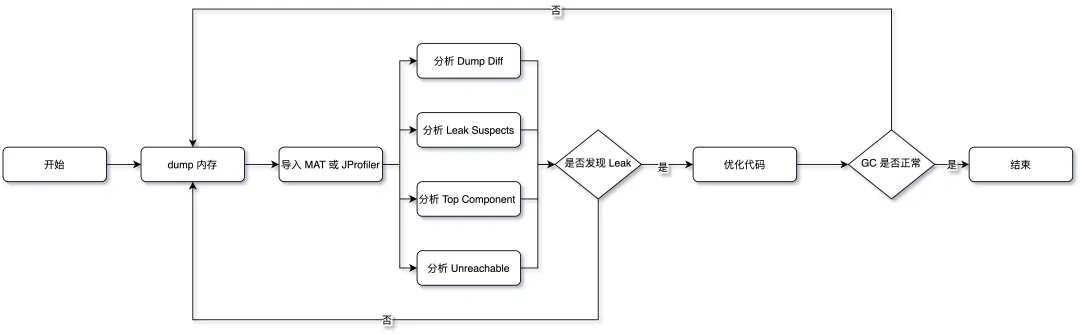
Dump Diff:分别在 CMS GC 的发生前后分别 dump 一次,进行dump文件差异分析
Leak Suspects:内存泄露报告
Top Component分析:按照对象、类、类加载器、包等多个维度观察 Histogram,同时使用 outgoing 和 incoming 分析关联的对象,另外就是 Soft Reference 和 Weak Reference、Finalizer 等也要看一下
Unreachable分析:不可达对象分析
单次 CMS Old GC 耗时长现象
CMS GC 单次 STW 最大超过 1000ms,不会频繁发生。但这种场景非常危险,某些场景下会引起“雪崩效应”,我们应该尽量避免出现。
原因分析
可能造成STW的情况如下:
Init Mark
整个过程比较简单,从 GC Root 出发标记 Old 中的对象,处理完成后借助 BitMap 处理下 Young 区对 Old 区的引用,整个过程基本都比较快,很少会有较大的停顿。
Final Mark
Final Remark 的开始阶段与 Init Mark 处理的流程相同,但是后续多了 Card Table 遍历、Reference 实例的清理,并将其加入到 Reference 维护的 pend_list 中,如果要收集元数据信息,还要清理 SystemDictionary、CodeCache、SymbolTable、StringTable 等组件中不再使用的资源。
STW前等待应用线程到达安全点(较少发生)
由此可见,大部分问题都出在 Final Remark 过程,观察详细 GC 日志,找到出问题时 Final Remark 日志,分析下 Reference 处理和元数据处理 real 耗时是否正常,详细信息需要通过 -XX:+PrintReferenceGC 参数开启。基本在日志里面就能定位到大概是哪个方向出了问题,耗时超过 10% 的就需要关注。
一般来说最容易出问题的地方就是 Reference 中的 FinalReference 和元数据信息处理中的 scrub symbol table 两个阶段,想要找到具体问题代码就需要内存分析工具 MAT 或 JProfiler 了,注意要 dump 即将开始 CMS GC 的堆。在用 MAT 等工具前也可以先用命令行看下对象 Histogram,有可能直接就能定位问题。
对 FinalReference 的分析主要观察 java.lang.ref.Finalizer 对象的 dominator tree,找到泄漏的来源。经常会出现问题的几个点有 Socket 的 SocksSocketImpl 、Jersey 的 ClientRuntime、MySQL 的 ConnectionImpl 等等。
scrub symbol table 表示清理元数据符号引用耗时,符号引用是 Java 代码被编译成字节码时,方法在 JVM 中的表现形式,生命周期一般与 Class 一致,当 _should_unload_classes 被设置为 true 时在 CMSCollector::refProcessingWork() 中与 Class Unload、String Table 一起被处理。
解决方案
一般不会大面积同时爆发,不过有很多时候单台 STW 的时间会比较长,如果业务影响比较大,及时摘掉流量,具体后续优化策略如下:
FinalReference:找到内存来源后通过优化代码的方式来解决,如果短时间无法定位可以增加 -XX:+ParallelRefProcEnabled 对 Reference 进行并行处理。