symbol table:观察 MetaSpace 区的历史使用峰值,以及每次 GC 前后的回收情况,一般没有使用动态类加载或者 DSL 处理等,MetaSpace 的使用率上不会有什么变化,这种情况可以通过 -XX:-CMSClassUnloadingEnabled 来避免 MetaSpace 的处理,JDK8 会默认开启 CMSClassUnloadingEnabled,这会使得 CMS 在 CMS-Remark 阶段尝试进行类的卸载。
内存碎片&收集器退化现象
并发的 CMS GC 算法,退化为 Foreground 单线程串行 GC 模式,STW 时间超长,有时会长达十几秒。其中 CMS 收集器退化后单线程串行 GC 算法有两种:
带压缩动作的算法,称为 MSC,上面我们介绍过,使用标记-清理-压缩,单线程全暂停的方式,对整个堆进行垃圾收集,也就是真正意义上的 Full GC,暂停时间要长于普通 CMS。
不带压缩动作的算法,收集 Old 区,和普通的 CMS 算法比较相似,暂停时间相对 MSC 算法短一些。
原型分析
晋升失败(Promotion Failed):old空间不足或者碎片导致晋升失败,由于concurrentMarkSweepThread 和担保机制的存在,发生的条件是很苛刻的
增量收集担保失败:分配内存失败后,会判断统计得到的 Young GC 晋升到 Old 的平均大小,以及当前 Young 区已使用的大小也就是最大可能晋升的对象大小,是否大于 Old 区的剩余空间。只要 CMS 的剩余空间比前两者的任意一者大,CMS 就认为晋升还是安全的,反之,则代表不安全,不进行Young GC,直接触发Full GC。
显示GC
并发模式失败(Concurrent Mode Failure)
解决方案
分析到具体原因后,我们就可以针对性解决了,具体思路还是从根因出发,具体解决策略:
内存碎片:通过配置 -XX:UseCMSCompactAtFullCollection=true 来控制 Full GC的过程中是否进行空间的整理(默认开启,注意是Full GC,不是普通CMS GC),以及 -XX: CMSFullGCsBeforeCompaction=n 来控制多少次 Full GC 后进行一次压缩(可以使用 -XX:PrintFLSStatistics 来观察内存碎片率情况,然后再设置具体的值)
增量收集:降低触发 CMS GC 的阈值,即参数 -XX:CMSInitiatingOccupancyFraction 的值,让 CMS GC 尽早执行,以保证有足够的连续空间,也减少 Old 区空间的使用大小,另外需要使用 -XX:+UseCMSInitiatingOccupancyOnly 来配合使用,不然 JVM 仅在第一次使用设定值,后续则自动调整。
浮动垃圾:视情况控制每次晋升对象的大小,或者缩短每次 CMS GC 的时间,必要时可调节 NewRatio 的值。另外就是使用 -XX:+CMSScavengeBeforeRemark 在过程中提前触发一次 Young GC,防止后续晋升过多对象。
堆外内存OOM现象
内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。
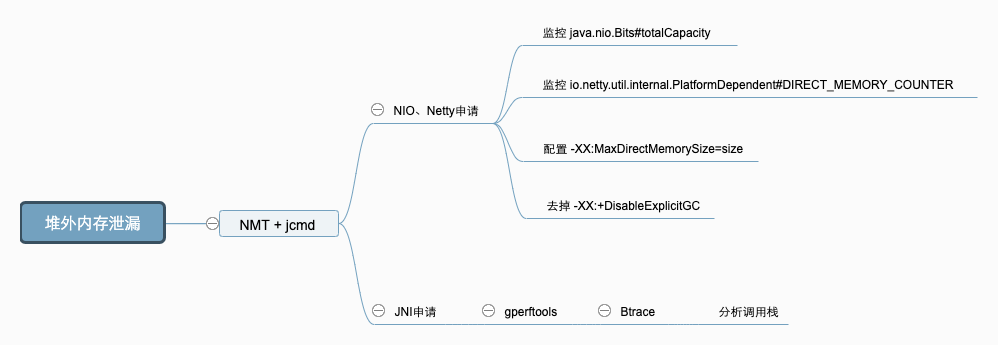
原因分析
JVM 的堆外内存泄漏,主要有两种的原因:
通过 UnSafe#allocateMemory,ByteBuffer#allocateDirect 主动申请了堆外内存而没有释放,常见于 NIO、Netty 等相关组件。
代码中有通过 JNI 调用 Native Code 申请的内存没有释放。
解决方案
首先可以使用 NMT(NativeMemoryTracking) + jcmd 分析泄漏的堆外内存是哪里申请,确定原因后,使用不同的手段,进行原因定位。