
可以通过在Properties中指定spark.scheduler.pool属性,指定调度池中的某个调度池作为TaskSetManager的父调度池,如果根调度池不存在此属性值对应的调度池,会创建以此属性值为名称的调度池作为TaskSetManager的父调度池,并将此调度池作为根调度池的子调度池。
在FAIR模式中,需要先对子Pool进行排序,再对子Pool里面的TaskSetMagager进行排序,因为Pool和TaskSetMagager都继承了Schedulable特质,因此使用相同的排序算法。
排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性:runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare值以及weight值。
注意,minShare、weight的值均在公平调度配置文件fairscheduler.xml中被指定,调度池在构建阶段会读取此文件的相关配置。
1)如果A对象的runningTasks大于它的minShare,B对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks比minShare小的先执行)
2)如果A、B对象的runningTasks都小于它们的minShare,那么就比较runningTasks与minShare的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行)
3)如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
4)如果上述比较均相等,则比较名字。
整体上来说就是通过minShare和weight这两个参数控制比较过程,可以做到让minShare使用率和权重使用率少(实际运行task比例较少)的先运行。
FAIR模式排序完成后,所有的TaskSetManager被放入一个ArrayBuffer里,之后依次被取出并发送给Executor执行。
从调度队列中拿到TaskSetManager后,由于TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
本地化调度
DAGScheduler切割Job,划分Stage,通过调用submitStage来提交一个Stage对应的tasks,submitStage会调用submitMissingTasks,submitMissingTasks确定每个需要计算的task的preferredLocations,通过调用getPreferrdeLocations()得到partition的优先位置,由于一个partition对应一个task,此partition的优先位置就是task的优先位置,对于要提交到TaskScheduler的TaskSet中的每一个task,该task优先位置与其对应的partition对应的优先位置一致。从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有task,并负责管理调度这些task。根据每个task的优先位置,确定task的Locality级别,Locality一共有五种,优先级由高到低顺序:
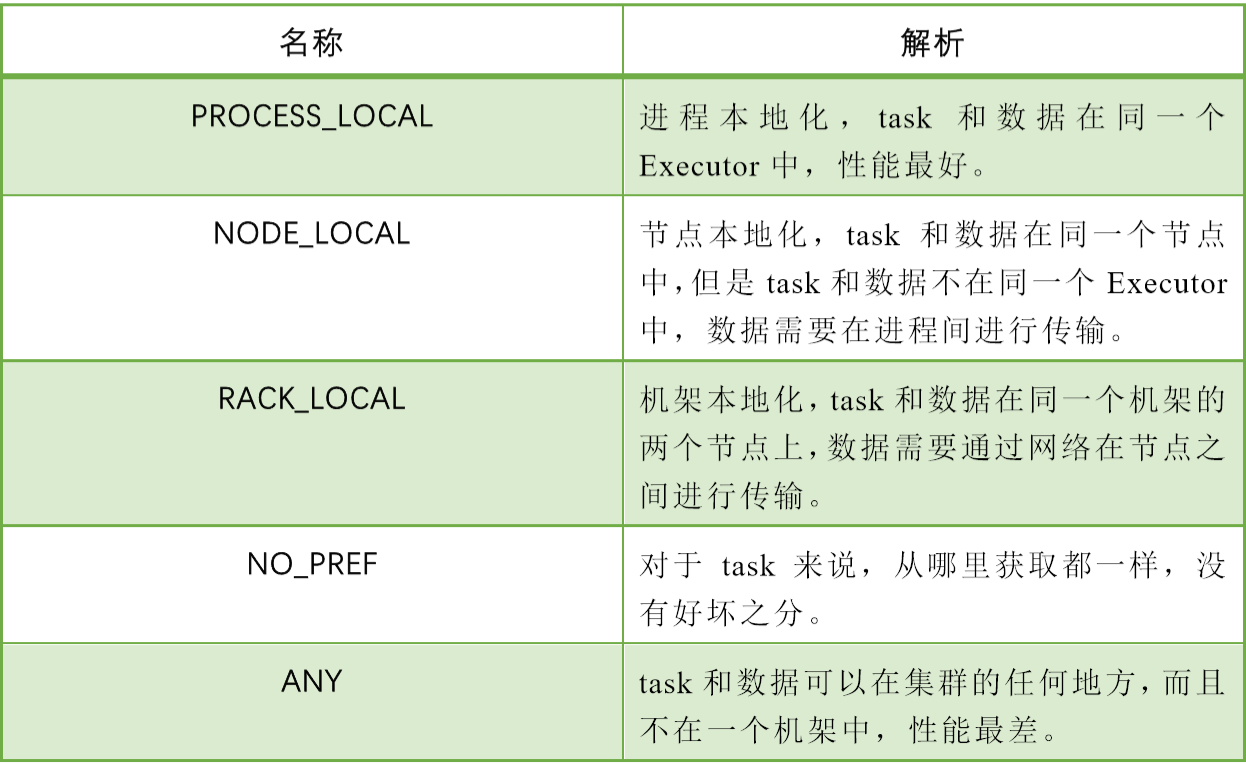
在调度执行时,Spark调度总是会尽量让每个task以最高的本地性级别来启动,当一个task以X本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以X本地性级别来启动该task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的Executor可能就会有相应的资源去执行此task,这就在在一定程度上提到了运行性能。
失败重试与黑名单机制
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。在记录Task失败次数过程中,会记录它上一次失败所在的ExecutorId和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的ExecutorId和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
七、Spark Shuffle解析ShuffleMapStage与FinalStage

在划分stage时,最后一个stage成为FinalStage,它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。
ShuffleMapStage的结束伴随着shuffle文件的写磁盘。
ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束。
Shuffle中的任务个数
map端task个数的确定
Shuffle过程中的task个数由RDD分区数决定,而RDD的分区个数与参数spark.default.parallelism有密切关系。
在Yarn Cluster模式下,如果没有手动设置spark.default.parallelism,则有:
Others: total number of cores on all executor nodes or 2, whichever is larger. spark.default.parallelism = max(所有executor使用的core总数,2)
如果进行了手动配置,则:
spark.default.parallelism = 配置值
还有一个重要的配置:
The maximum number of bytes to pack into a single partition when reading files. spark.files.maxPartitionBytes = 128 M (默认)
代表着rdd的一个分区能存放数据的最大字节数,如果一个400MB的文件,只分了两个区,则在action时会发生错误。
当一个spark应用程序执行时,生成sparkContext,同时会生成两个参数,由上面得到的spark.default.parallelism推导出这两个参数的值:
sc.defaultParallelism = spark.default.parallelism
sc.defaultMinPartitions = min(spark.default.parallelism,2)
当以上参数确定后,就可以推算RDD分区数目了。
(1)通过scala集合方式parallelize生成的RDD
val rdd = sc.parallelize(1 to 10)
这种方式下,如果在parallelize操作时没有指定分区数,则有:
rdd的分区数 = sc.defaultParallelism
(2)在本地文件系统通过textFile方式生成的RDD
val rdd = sc.textFile("path/file")
rdd的分区数 = max(本地file的分片数,sc.defaultMinPartitions)
(3)在HDFS文件系统生成的RDD
rdd的分区数 = max(HDFS文件的Block数目,sc.defaultMinPartitions)
(4)从HBase数据表获取数据并转换为RDD
rdd的分区数 = Table的region个数
(5)通过获取json(或者parquet等等)文件转换成的DataFrame
rdd的分区数 = 该文件在文件系统中存放的Block数目
(6)Spark Streaming获取Kafka消息对应的分区数
基于Receiver: