
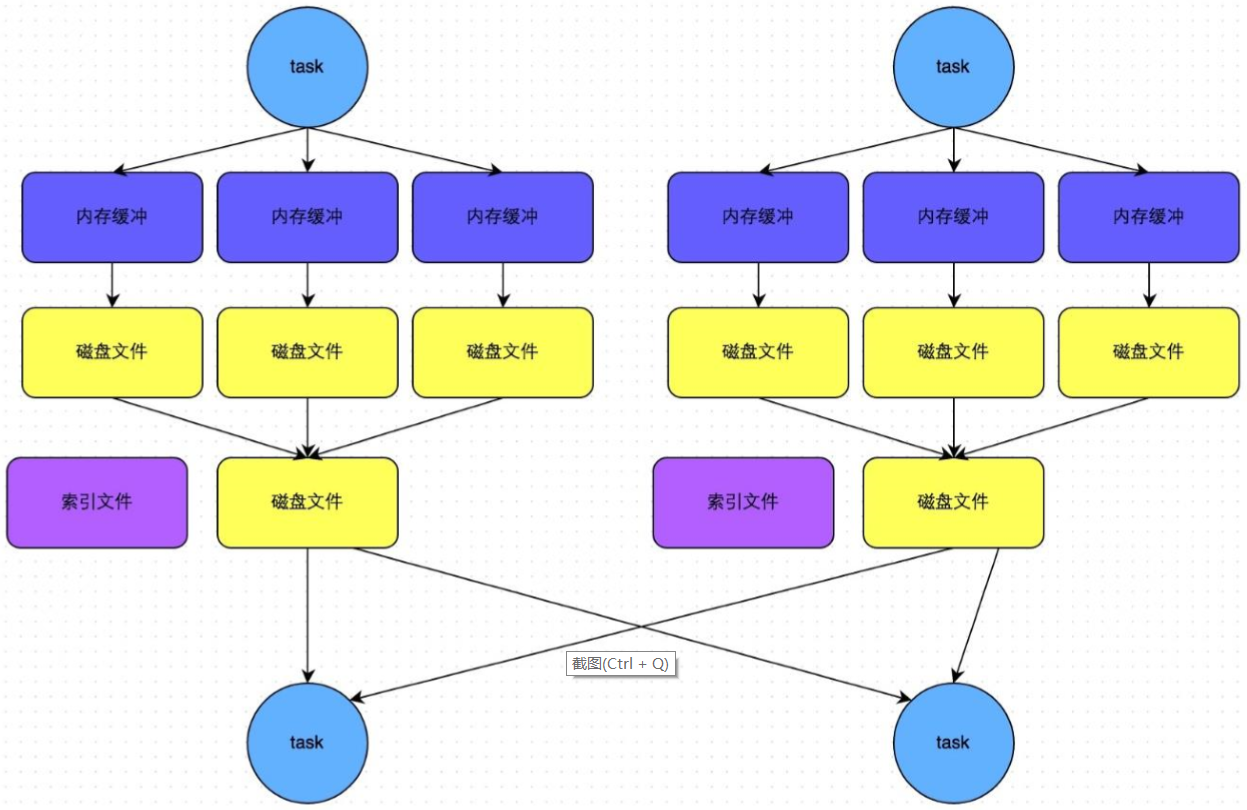
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,一次你还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
普通运行机制的SortShuffleManager工作原理如下图所示:

2、bypass运行机制
bypass运行机制的触发条件如下:
(1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
(2)不是聚合类的shuffle算子。
此时,每个task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffleread的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
普通运行机制的SortShuffleManager工作原理如下图所示:
在执行Spark应用程序时,Spark集群会启动Driver和Executor两种JVM进程,前者为主控进程,负责创建Spark上下文,提交Spark作业(Job),并将作业转化为计算任务(Task),在各个Executor进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给Driver,同时为需要持久化的RDD提供存储功能。
堆内和堆外内存规划
作为一个JVM进程,Executor的内存管理建立在JVM的内存管理之上,Spark对JVM的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
堆内内存受到JVM统一管理,堆外内存是直接向操作系统进行内存的申请和释放。
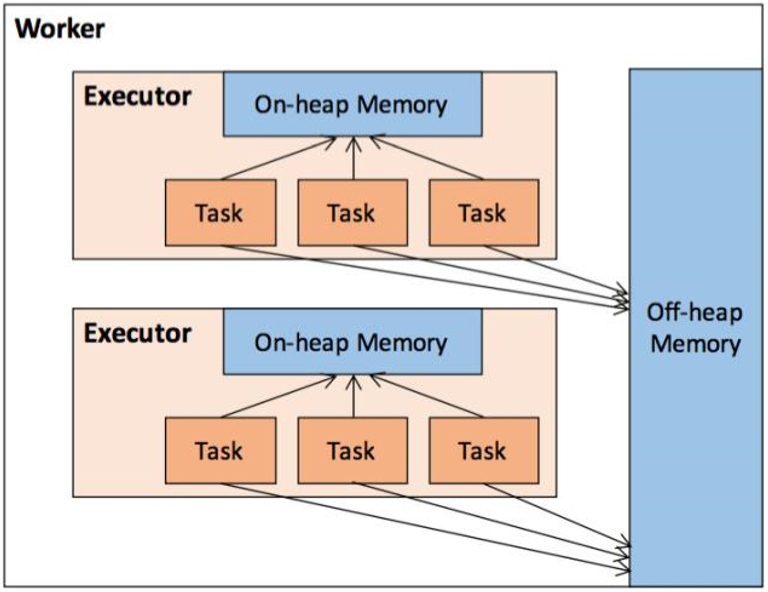
1、堆内内存
堆内内存的大小,由Spark应用程序启动时的- executor-memory或spark.executor.memory参数配置。Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行Shuffle时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户定义的Spark应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同。