
快速排序用到了分治思想,同样的还有归并排序。乍看起来快速排序和归并排序非常相似,都是将问题变小,先排序子串,最后合并。不同的是快速排序在划分子问题的时候经过多一步处理,将划分的两组数据划分为一大一小,这样在最后合并的时候就不必像归并排序那样再进行比较。但也正因为如此,划分的不定性使得快速排序的时间复杂度并不稳定。
快速排序的基本思想:通过一趟排序将待排序列分隔成独立的两部分,其中一部分记录的元素均比另一部分的元素小,则可分别对这两部分子序列继续进行排序,以达到整个序列有序。
算法步骤快速排序使用分治法(Divide and conquer)策略来把一个序列分为较小和较大的2个子序列,然后递回地排序两个子序列。具体算法描述如下:
从序列中随机挑出一个元素,做为 “基准”(pivot);
重新排列序列,将所有比基准值小的元素摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个操作结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地把小于基准值元素的子序列和大于基准值元素的子序列进行快速排序。
图解算法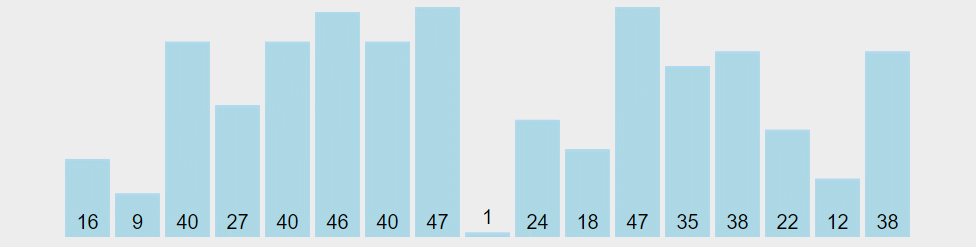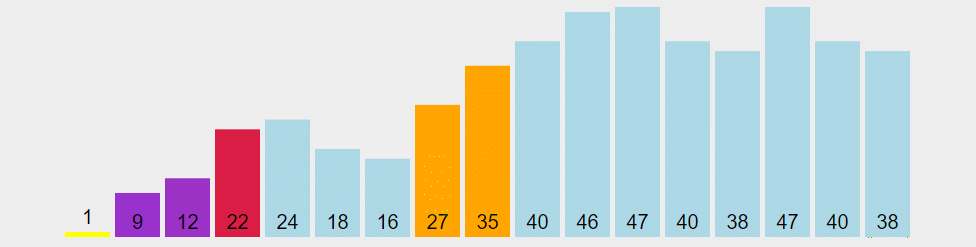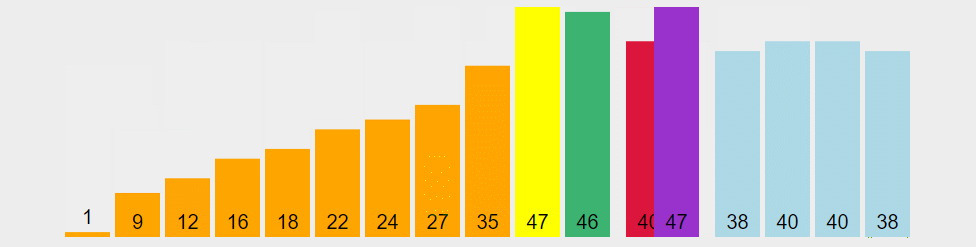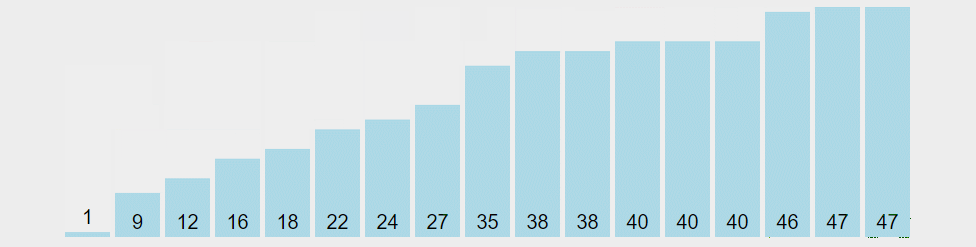
JAVA
/** * Swap the two elements of an array * @param array * @param i * @param j */ private static void swap(int[] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } /** * Partition function * @param arr * @param left * @param right * @return small_idx */ private static int Partition(int[] arr, int left, int right) { if (left == right) { return left; } // random pivot int pivot = (int) (left + Math.random() * (right - left + 1)); swap(arr, pivot, right); int small_idx = left; for (int i = small_idx; i < right; i++) { if (arr[i] < arr[right]) { swap(arr, i, small_idx); small_idx++; } } swap(arr, small_idx, right); return small_idx; } /** * Quick sort function * @param arr * @param left * @param right * @return arr */ public static int[] QuickSort(int[] arr, int left, int right) { if (left < right) { int pivotIndex = Partition(arr, left, right); sort(arr, left, pivotIndex - 1); sort(arr, pivotIndex + 1, right); } return arr; }Python
def QuickSort(arr, left=None, right=None): left = 0 if left == None else left right = len(arr)-1 if right == None else right if left < right: pivotIndex = Partition(arr, left, right) QuickSort(arr, left, pivotIndex-1) QuickSort(arr, pivotIndex+1, right) return arr def Partition(arr, left, right): if left == right: return left # 随机pivot swap(arr, random.randint(left, right), right) pivot = right small_idx = left for i in range(small_idx, pivot): if arr[i] < arr[pivot]: swap(arr, i, small_idx) small_idx += 1 swap(arr, small_idx, pivot) return small_idx def swap(arr, i, j): arr[i], arr[j] = arr[j], arr[i] 算法分析稳定性:不稳定
时间复杂度:最佳:O(nlogn) 最差:O(nlogn) 平均:O(nlogn)
空间复杂度:O(nlogn)
堆排序(Heap Sort)堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆的性质:即子结点的值总是小于(或者大于)它的父节点。
算法步骤将初始待排序列(R1, R2, ……, Rn)构建成大顶堆,此堆为初始的无序区;
将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1, R2, ……, Rn-1)和新的有序区(Rn),且满足R[1, 2, ……, n-1]<=R[n];
由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1, R2, ……, Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1, R2, ……, Rn-2)和新的有序区(Rn-1, Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
图解算法