前一章节,我们知道了如何利用RestTemplate+Ribbon和Feign的方式进行服务的调用。在微服务架构中,一个服务可能会调用很多的其他微服务应用,虽然做了多集群部署,但可能还会存在诸如网络原因或者服务提供者自身处理的原因,或多或少都会出现请求失败或者请求延迟问题,若服务提供者长期未对请求做出回应,服务消费者又不断的请求下,可能就会造成服务提供者服务崩溃,进而服务消费者也一起跟着不可用,严重的时候就发生了系统雪崩了。鉴于此,产生了断路器等一系列的服务保护机制。本章节,就来说下如何利用Hystrix进行容错处理。
一点知识
按照此系列的惯例,我们先来了解下一些相关的知识。
注:以下部分内容转至大佬纯洁的微笑:熔断器Hystrix。
容错处理手段容错处理是指软件运行时,能对由非正常因素引起的运行错误给出适当的处理或信息提示,使软件运行正常结束——百度百科
从百度百科的解释中可以看出,简单理解,所谓的容错处理其实就是捕获异常了,不让异常影响系统的正常运行,正如java中的try catch一样。
而在微服务调用中,自身异常可自行处理外,对于依赖的服务若发生错误,或者调用异常,或者调用时间过长等原因时,避免长时间等待,造成系统资源耗尽。
一般上都会通过设置请求的超时时间,如http请求中的ConnectTimeout和ReadTimeout;再或者就是使用熔断器模式,隔离问题服务,防止级联错误等。
在微服务架构中,存在很多的微服务单元,各个微服务之间通过网络进行通讯,难免出现依赖关系,若某一个单元出现故障,就很容易因依赖关系而引发故障的蔓延,产生“雪崩效应”,最终导致整个系统的瘫痪。
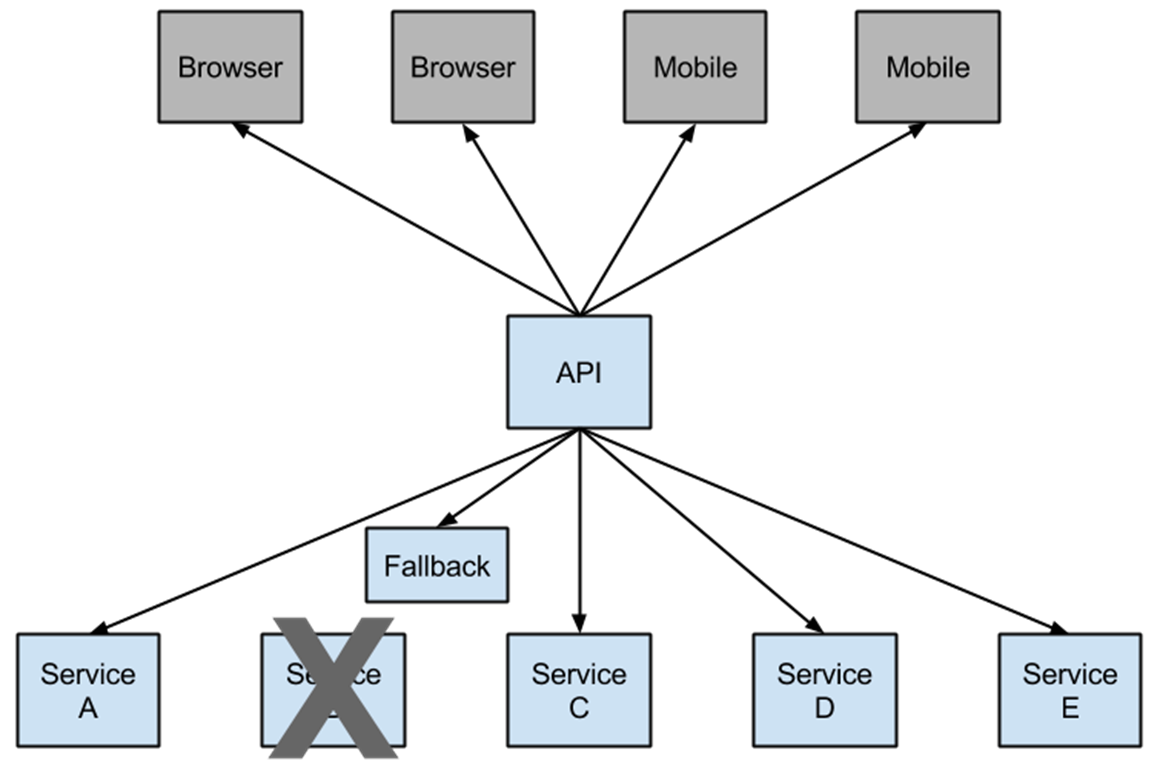
下面这张图,相比大家都有看过了。
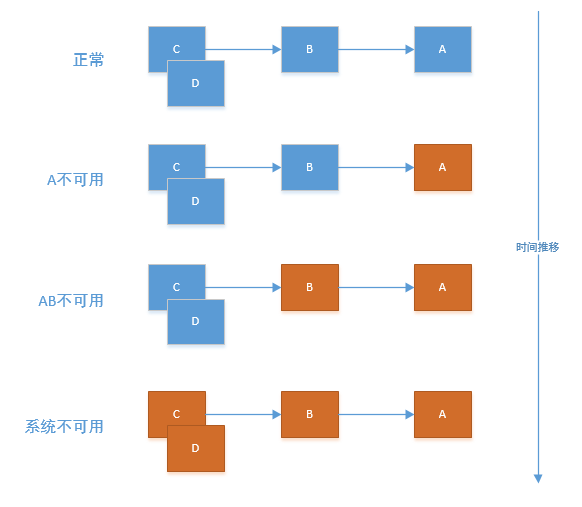
如图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了。也就应了那句话:星星之火,可以燎原!
熔断器熔断器,和现实生活中的空气开关作用很像。它可以实现快速失败,如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作,使得应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生。熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
熔断器模式就像是那些容易导致错误的操作的一种代理。这种代理能够记录最近调用发生错误的次数,然后决定使用允许操作继续,或者立即返回错误。
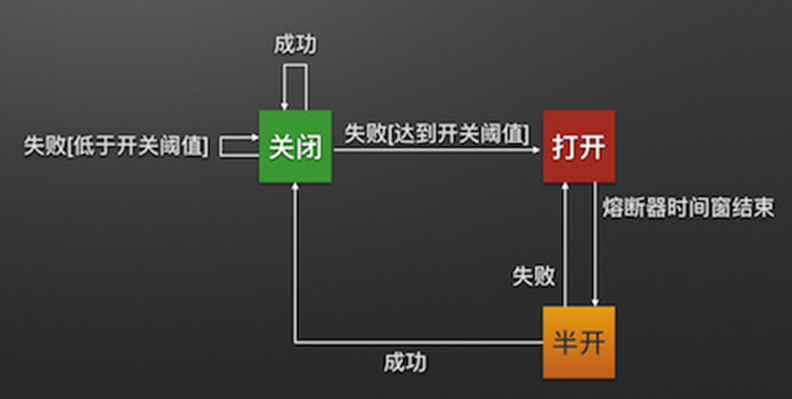
可以看出,熔断器一共有三种状态,之间转换关系如下:
关闭状态
当熔断器处于关闭状态时,请求是可以被放行的;
当熔断器统计的失败次数触发开关时,转为打开状态。
打开状态
当熔断器处于打开状态时,所有请求都是不被放行的,直接返回失败;
只有在经过一个设定的时间窗口周期后,熔断器才会转换到半开状态
半开状态
当熔断器处于半开状态时,当前只能有一个请求被放行;
这个被放行的请求获得远端服务的响应后,假如是成功的,熔断器转换为关闭状态,否则转换到打开状态。
个人觉得,主要还是快速失败,避免请求堆积,压垮服务器。进而起到保护服务高可用的目的。
Hystrix实践 何为HystrixHystrix是一个实现了超时机制和断路器模式的工具类库。
Hystrix是有Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或第三方库,防止级联失败,从而提升系统的可用性和容错性。
Hystrix容错机制:
包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行,这是用到了设计模式“命令模式”。
跳闸机制:当某服务的错误率超过一定阈值时,Hystrix可以自动或手动跳闸,停止请求该服务一段时间。
资源隔离:Hystrix为每个依赖都维护了一个小型的线程池,如果该线程池已满,发往该依赖的请求就被立即拒绝,而不是排队等候,从而加速判定失败。
监控:Hystrix可以近乎实时的监控运行指标和配置的变化。如成功、失败、超时、被拒绝的请求等。
回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。回退逻辑可自定义。
自我修复:断路器打开一段时间后,会自动进入半开状态,断路器打开、关闭、半开的逻辑转换。
下图就是Hystrix的回退策略,防止级联故障。