
有了这个dubbo接口,我们就可以很容易的将数据传送给默认网关了。
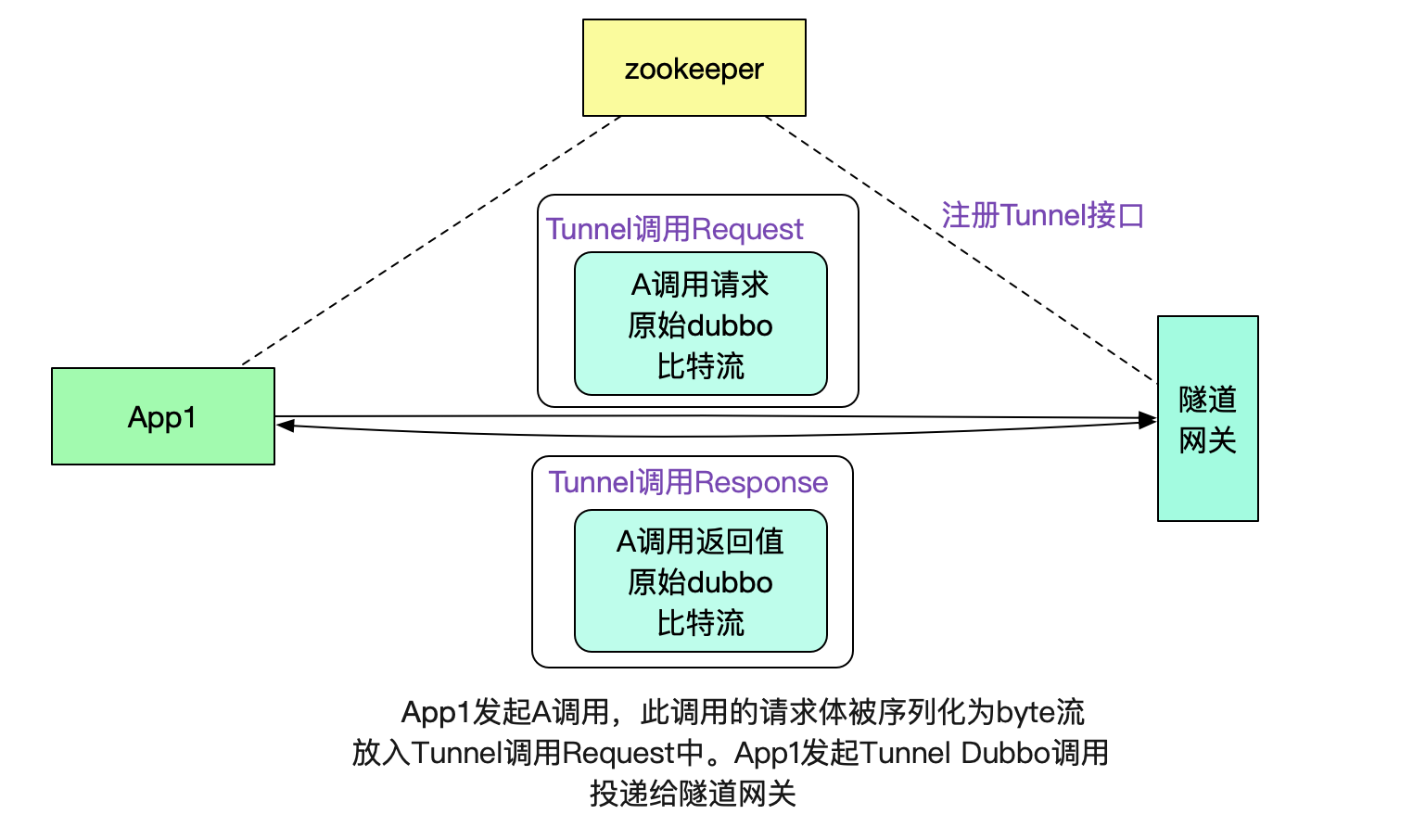
注意,这里其实也是做了一层隧道协议,即用dubbo协议承载dubbo协议,用这种类似套娃的方法有效的利用了dubbo本身的注册发现机制。 网关和网关之间通过http通信
由于不同集群之间通过专线进行通信,所以笔者采用了http通信来进行。在App1的请求到达隧道网关后,网关会将原始body比特流从TunnelInterfaceRequest中取出。然后放到一个http的请求中进行传递。如下图所示:

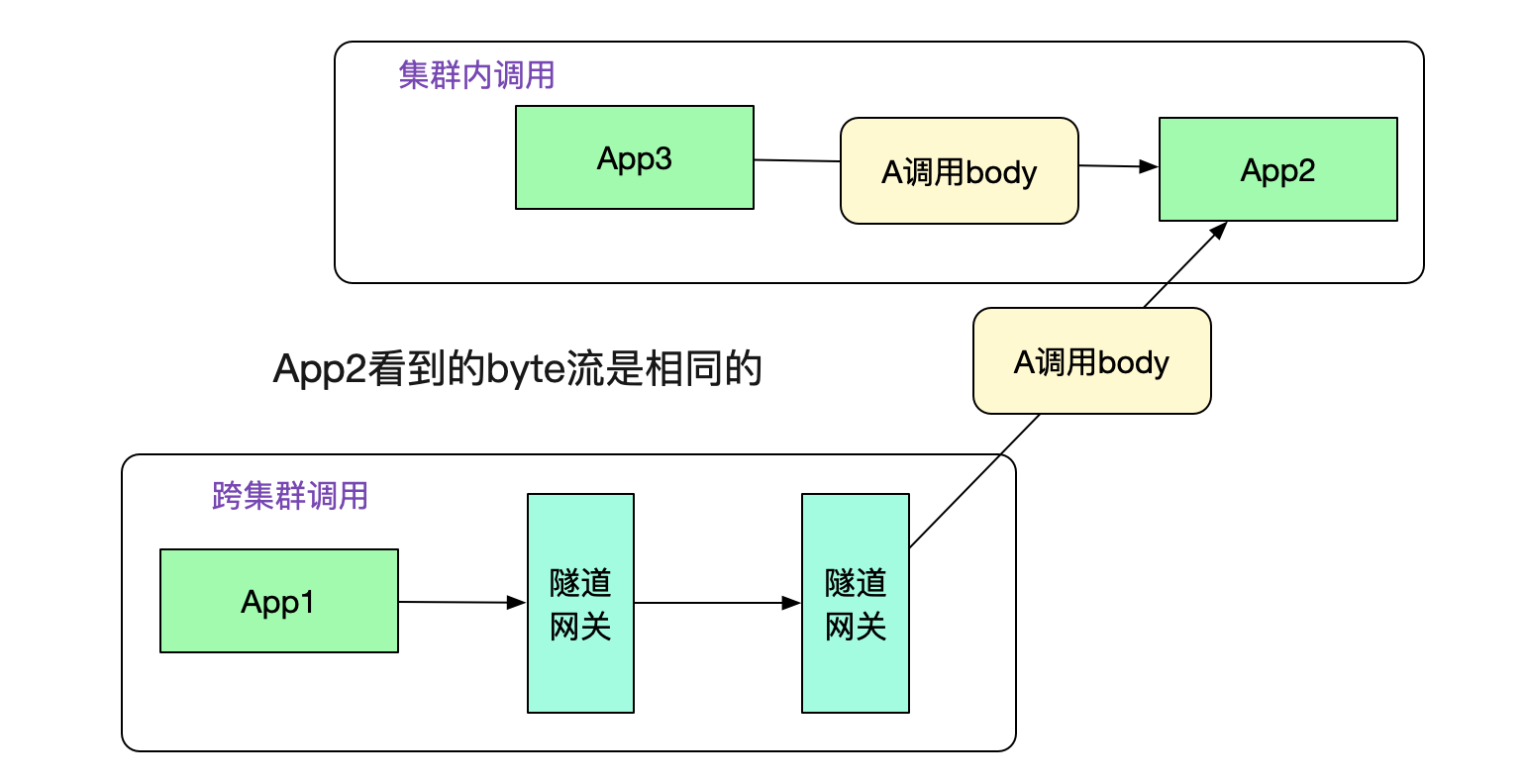
值得注意的是,由于传递的是byte流,没有携带任何业务信息(例如类型信息等),所以我们的隧道网关可以对任意dubbo请求进行隧道传输,而不像传统的网关那样需要添加各种业务对应的jar包并不停发布-_-!
在图中,投递到另一端的隧道网关后,其从http协议中取出调用元信息和原始调用byte流,通过调用元信息找到App2。然后给App2重放byte流,这样就可以进行dubbo调用了。事实上,App2从隧道网关看到的byte流和从集群内其它机器调用的byte流完全一致。如下图所示:
很明显的,我们的返回值也需要通过隧道机制。和Request一样,其也会走两次隧道协议,如下图所示:
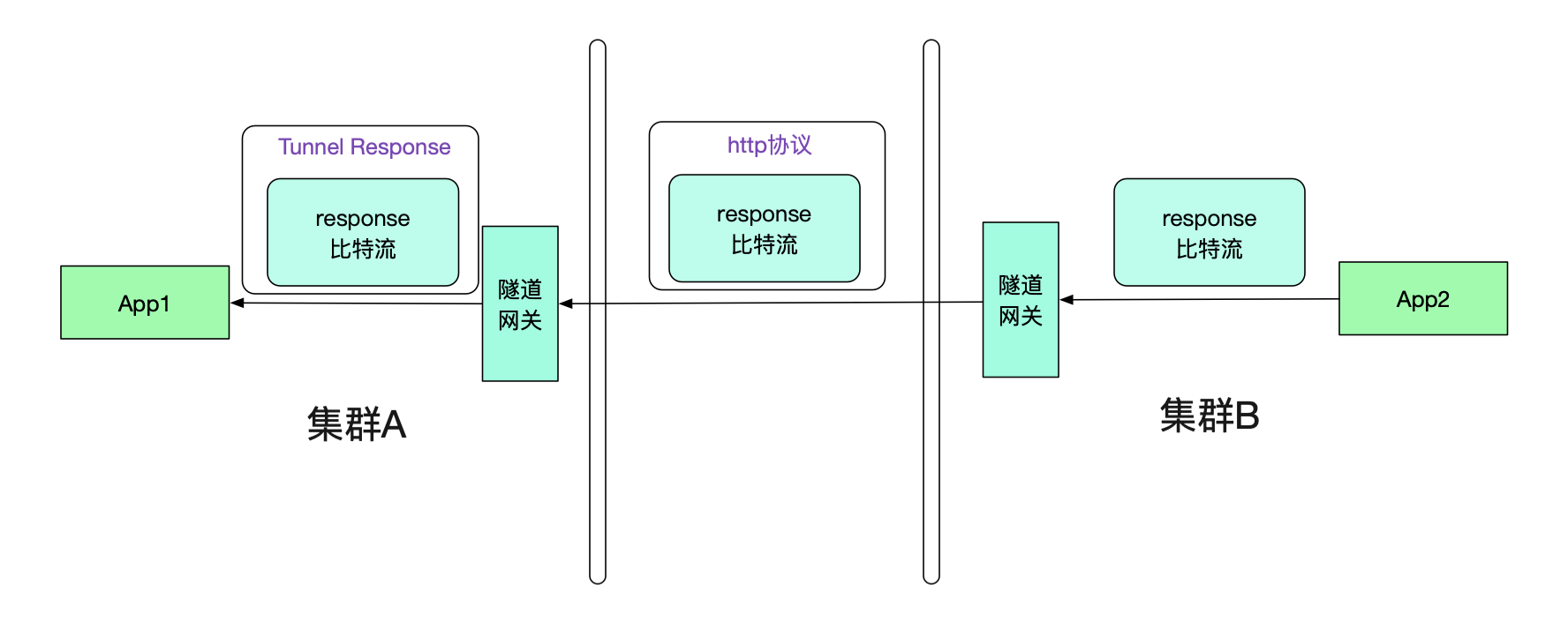
那么App1真正接收到的其实是Tunnel Response,怎么让其透明的接收原始response比特流呢?这就需要调用方接入笔者研发的轻量级jar包(其实,一开始的request的隧道也需要这样的jar包) 对dubbo进行扩展
由于dubbo有非常优秀的filter机制,可以在各种地方可以扩展。为了这个隧道机制,笔者就扩展了其中的invoke调用逻辑。如下图所示:

只要引入笔者写的jar包,就能够非常轻松的进行自动扩展,除了pom.xml加两行,其它业务代码完全无需修改。 隧道网关的接口发现
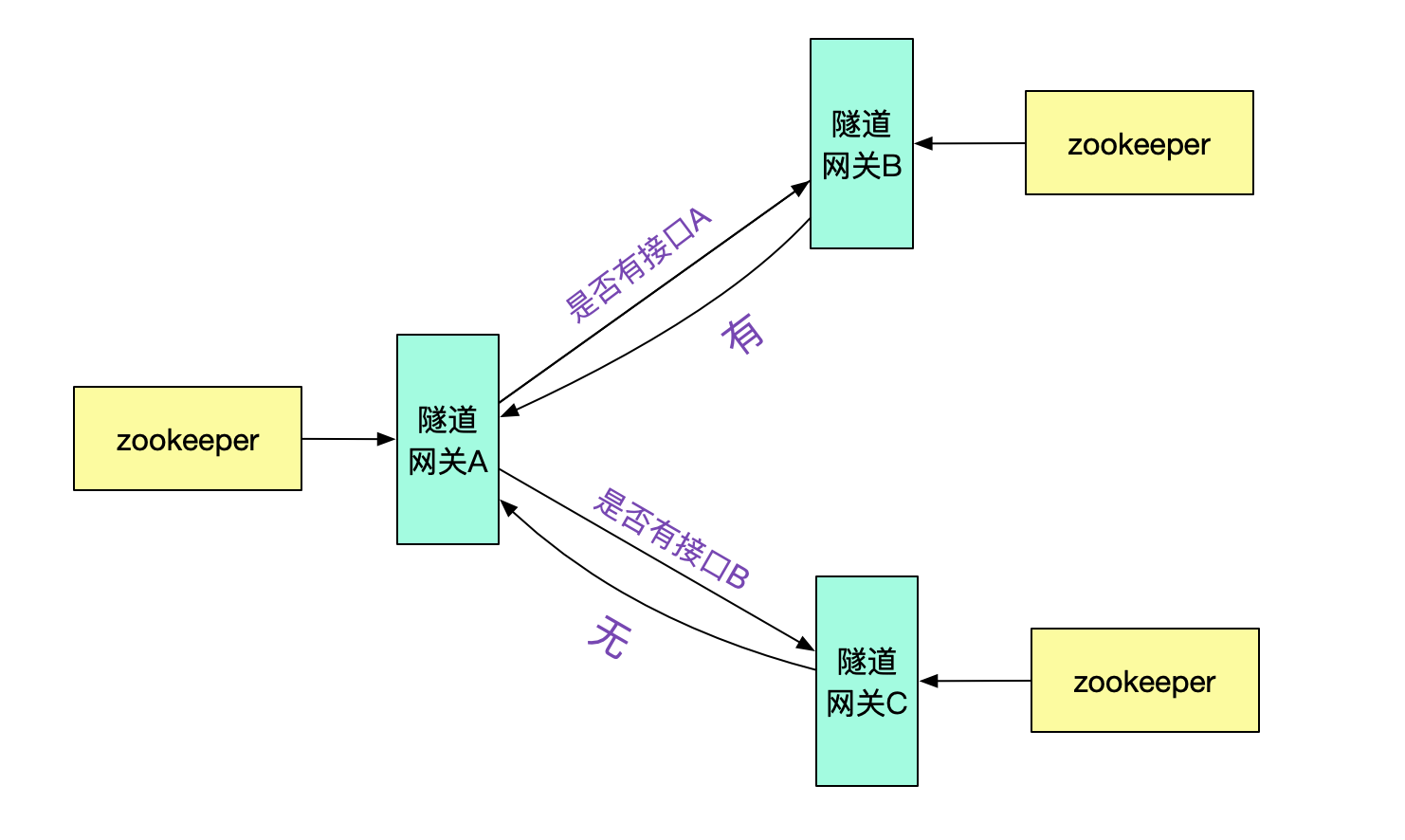
那么隧道网关A是怎么知道接口在集群B,从而投递给隧道网关B的呢?很明显的,我们需要隧道网关间的集群通信机制。
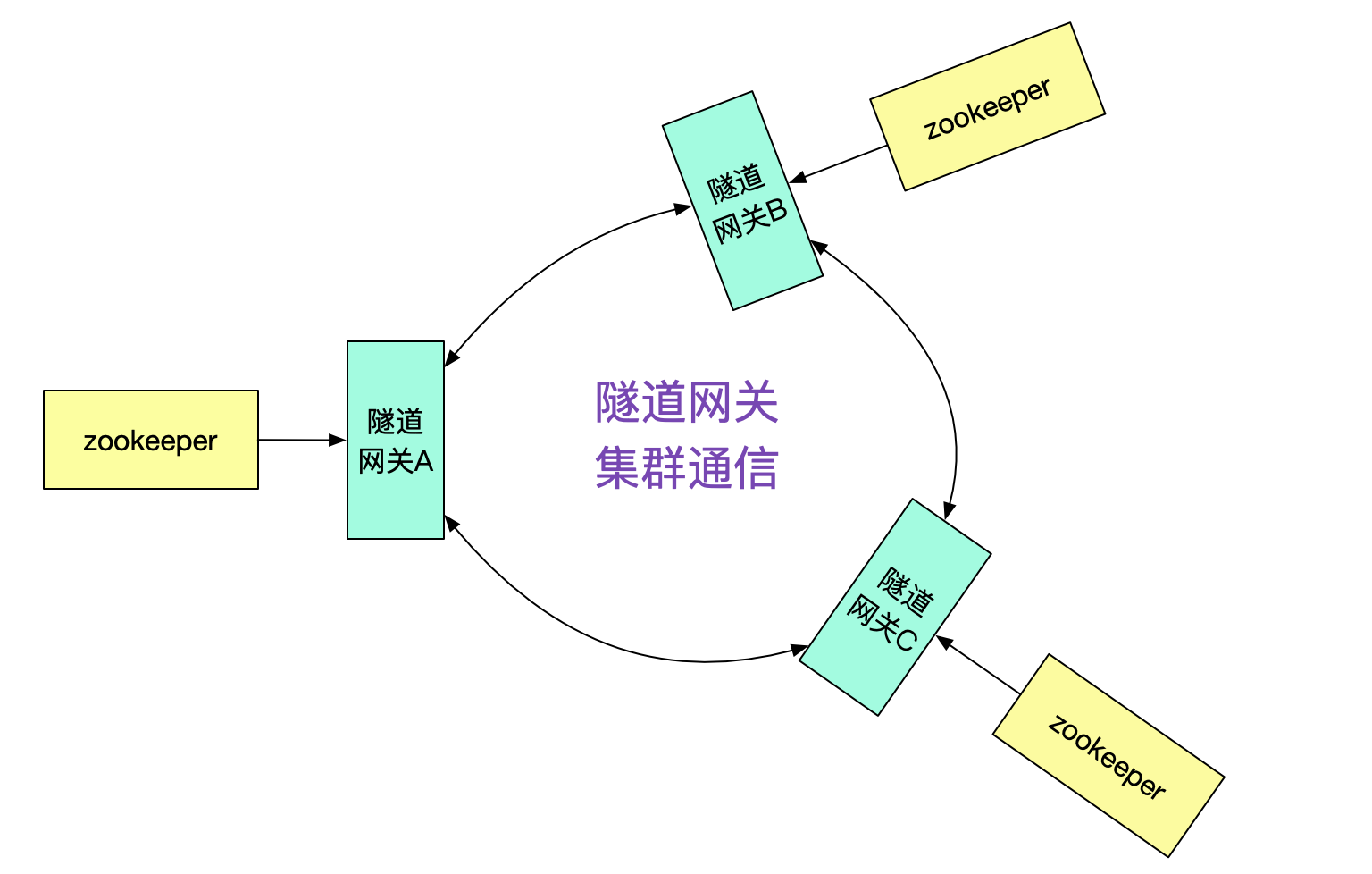
例如,由隧道网关向其它不同的隧道网关询问是否有此接口,并按一定策略做缓存即可。
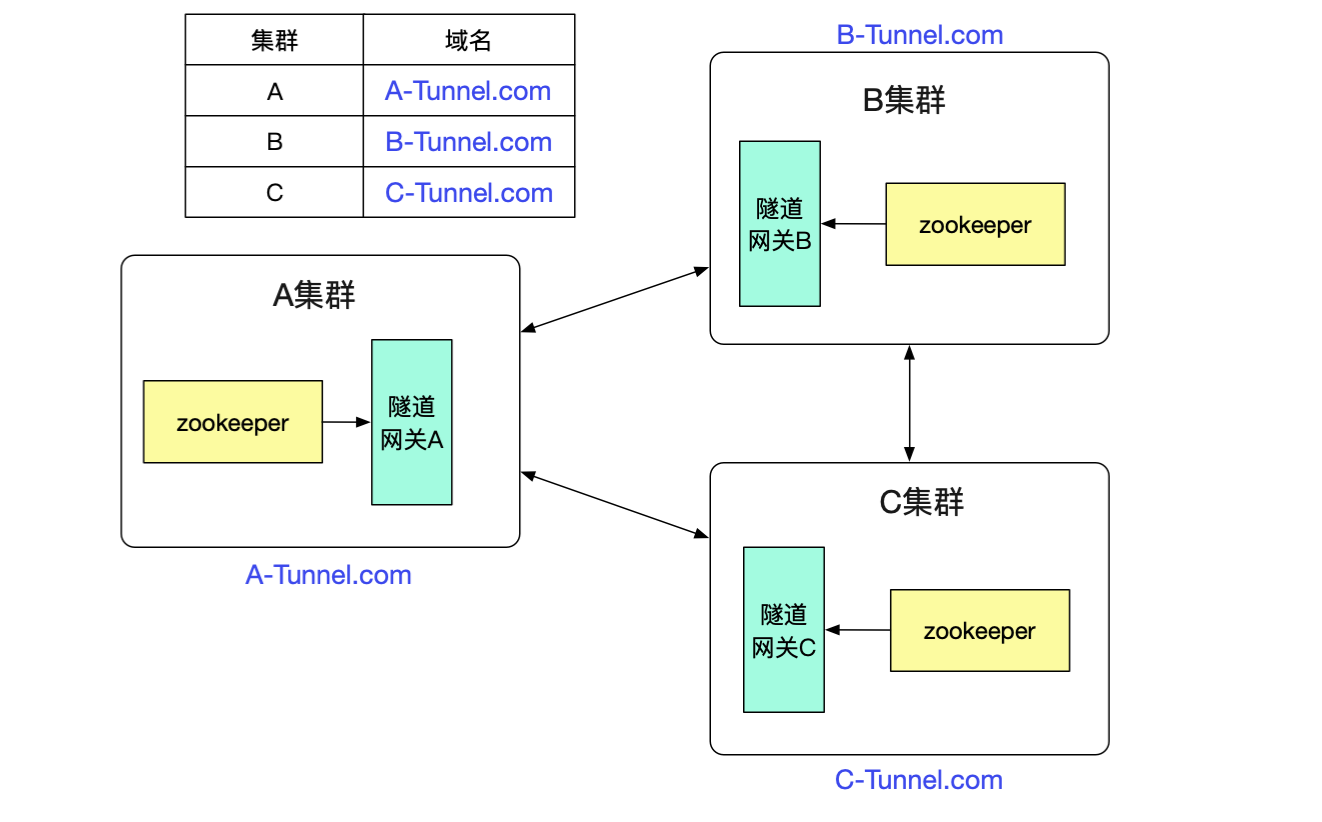
最后的问题就是隧道网关怎么知道其它的dubbo集群的了,由于相对于dubbo接口数量,集群的数量是很少且不经常改变。我们只需要找个地方简单的记录下即可,例如放到数据库里面。然后由于是http调用,直接通过DNS解析域名即可做负载均衡。
由于笔者的这套机制序列化和反序列化完全在Provider/Consumer端,完全没有对网关形成任何压力,所以网关的CPU消耗很低。在单个调用延迟上,由于多了两跳,不可避免的有所损耗,大概每个接口多了2ms左右。
总结这套机制从一开始构想,到完全能够在产线运行,并且性能损耗还很小,笔者还是花费了不少的精力。看到这样的结果,还是非常有成就感的。事实上,这套隧道机制在非常多的地方借鉴了网络上的概念。可谓它山之石可以攻玉!不同技术之间确实可以相互迁移,他们只是在不同的层级上解决了本质相通的问题!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!
