
保存上一步配置好的规则组,日志数据经过DBus执行算子引擎,就可以生成相应的结构化数据了。目前根据项目实际,DBus输出的数据是UMS格式,如果不想使用UMS,可以经过简单的开发,实现定制化。
注:UMS是DBus定义并使用的、通用的数据交换格式,是标准的JSON。其中同时包含了schema和数据信息。更多UMS介绍请参考DBus开源项目主页的介绍。开源地址:https://github.com/bridata/dbus
以下是测试案例,输出的结构化UMS数据的样例:

为了便于掌握数据抽取、规则匹配、监控预警等情况,我们提供了日志数据抽取的可视化实时监控界面,如下图所示,可随时了解以下信息:
实时数据条数
错误条数情况(错误条数是指:执行算子时出现错误的情况,帮助发现算子与数据是否匹配,用于修改算子,DBus同时也提供了日志回读的功能,以免丢失部分数据)
数据延时情况
日志抽取端是否正常
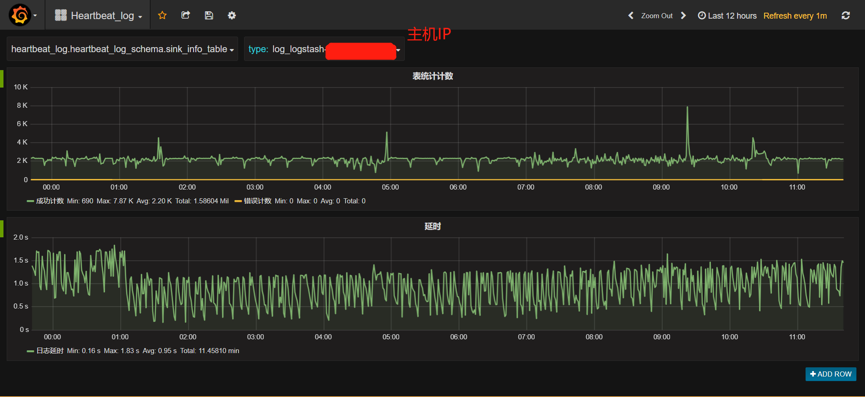
监控信息中包含了来自集群内各台主机的监控信息,以主机IP(或域名)对数据分别进行监控、统计和预警等。
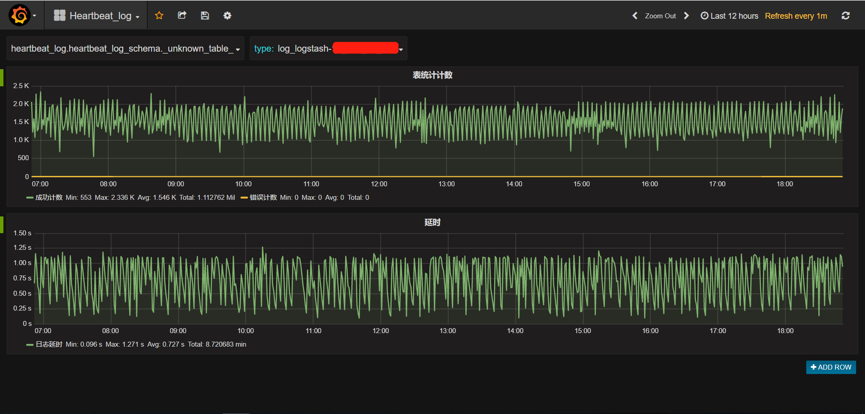
监控中还有一张表叫做_unkown_table_ 表明所有没有被匹配上的数据条数。例如:Logstash抓取的日志中有5种不同事件的日志数据,我们只捕获了其中3种事件,其它没有被匹配上的数据,全部在_unkown_table_计数中。
DBus同样可以接入Flume、Filebeat、UMS等数据源,只需要稍作配置,就可以实现类似于对Logstash数据源同样的处理效果,更多关于DBus对log的处理说明,请参考:
https://bridata.github.io/DBus/install-logstash-source.html
https://bridata.github.io/DBus/install-flume-source.html
https://bridata.github.io/DBus/install-filebeat-source.html
应用日志经过DBus处理后,将原始数据日志转换为了结构化数据,输出到Kafka中提供给下游数据使用方进行使用,比如通过Wormhole将数据落入数据库等。具体如何将DBus与Wormhole结合起来使用,请参考:如何设计实时数据平台(技术篇)。