
导读:数据总线DBus的总体架构中主要包括六大模块,分别是:日志抓取模块、增量转换模块、全量抽取程序、日志算子处理模块、心跳监控模块、Web管理模块。六大模块各自的功能相互连接,构成DBus的工作原理:通过读取RDBMS增量日志的方式来实时获取增量数据日志(支持全量拉取);基于Logstash,flume,filebeat等抓取工具来实时获得数据,以可视化的方式对数据进行结构化输出。本文主要介绍的是DBus中基于可视化配置的日志结构化转换实现的部分。
一、结构化日志的原理 1.1 源端日志抓取DBus可以对接多种log数据源,例如:Logstash、Flume、Filebeat等。上述组件都是业界比较流行的日志抓取工具,一方面便于用户和业界统一标准,方便用户技术方案的整合;另一方面也避免了无谓的重复造轮子。抓取的数据我们称为原始数据日志(raw data log),由抓取组件将其写入Kafka中,等待DBus后续处理。
1.2 可视化配置规则,使日志结构化用户可自定义配置日志源和目标端。同一个日志源的数据可以输出到多个目标端。每一条“日志源-目标端”线,用户可以根据自己的需要来配置相应的过滤规则。经过规则算子处理后的日志是结构化的,即:有schema约束,类似于数据库中的表。
1.3 规则算子DBus设计了丰富易用的算子,用于对数据进行定制化操作。用户对数据的处理可分为多个步骤进行,每个步骤的数据处理结果可即时查看、验证;并且可重复使用不同算子,直到转换、裁剪出自己需要的数据。
1.4 执行引擎将配置好的规则算子组应用到执行引擎中,对目标日志数据进行预处理,形成结构化数据,输出到Kafka,供下游数据使用方使用。系统流程图如下所示:

根据DBus log设计原则,同一条原始日志,可以被提取到一个或多个表中。每个表是结构化的,满足相同的schema约束。
每个表是一个规则算子组的集合,每个表可以拥有1个或多个规则算子组;
每个规则算子组,由一组规则算子组合而成,每个算子具有独立性;
对于任意一条原始数据日志(raw data log),它应该属于哪张表呢?
假如用户定义了若干张逻辑表(T1,T2…),用于抽取不同类型的日志,那么,每条日志需要与规则算子组进行匹配:
进入某张表T1的所有规则算子组的执行过程
符合条件的进入规则算子组,并且被执行引擎转换为结构化的表数据
不符合提取条件的日志尝试下一个规则算子组
对于T1的所有规则算子组,如果都不满足要求,则进入下一张表T2的执行过程,以此类推
如果该条日志不符合任何一张表的过滤规则,则进入_unknown_table_表
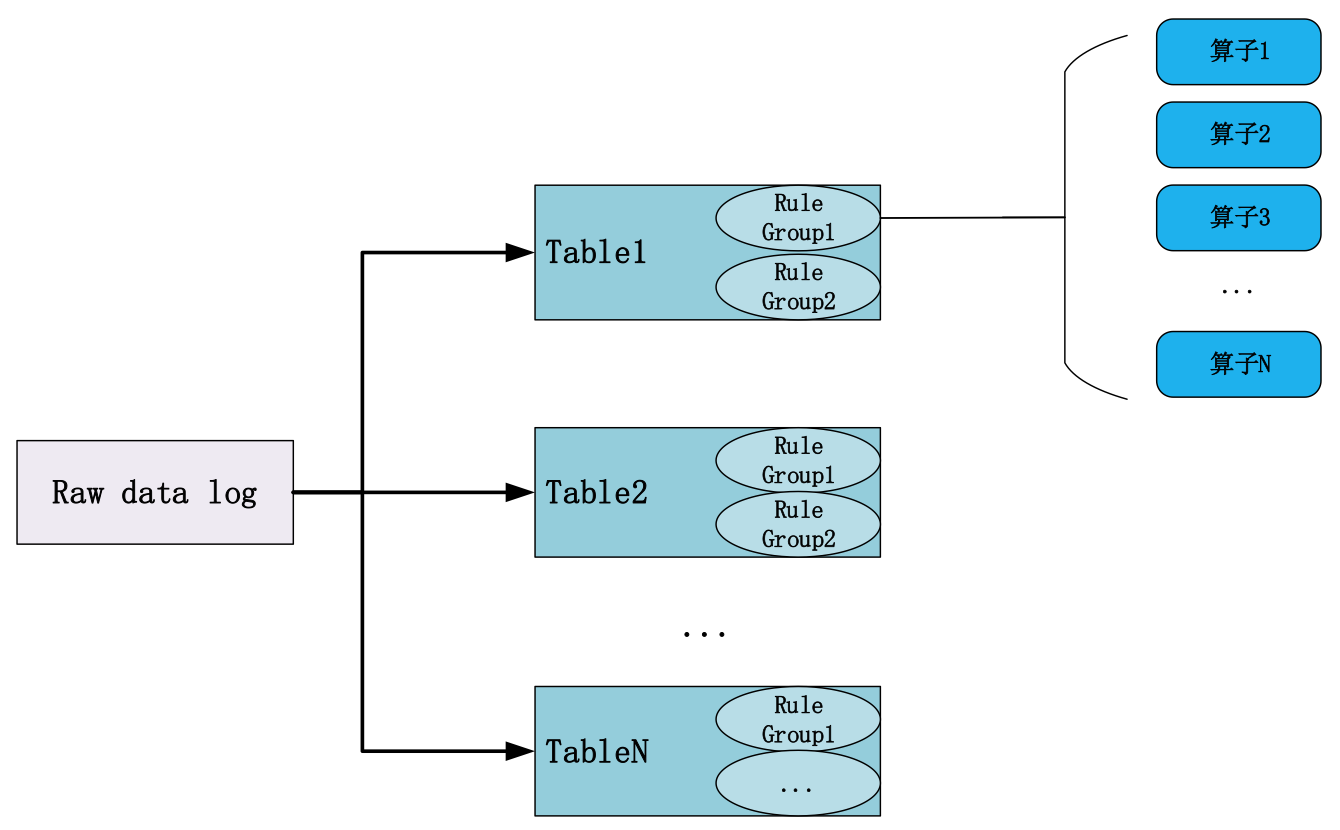
例如,对于同一条应用日志,其可能属于不止一个规则组或Table,而在我们定义的规则组或Table中,只要其满足过滤条件,该应用日志就可以被规则组提取,即保证了同一条应用日志可以同属于不同的规则组或Table。
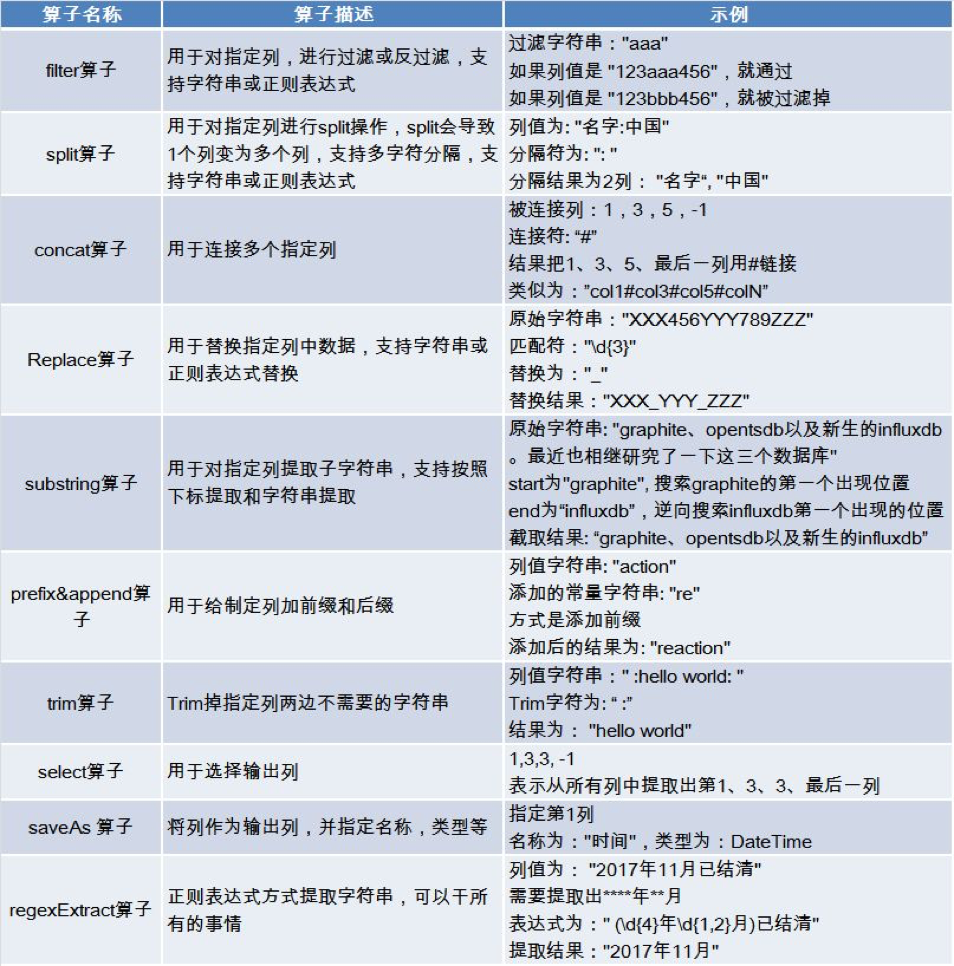
规则算子是对数据进行过滤、加工、转换的基本单元。常见的规则算子如上图所示。
算子之间具有独立性,算子之间可以任意组合使用,从而可以实现许多复杂的、高级的功能,通过对算子进行迭代使用,最终可以实现对任意数据进行加工的目的。用户可以开发自定义算子,算子的开发非常容易,用户只要遵循基本接口原则,就可以开发任意的算子。
二、DBus日志处理实例以DBus集群环境为例,DBus集群中有两台机器(即master-slave)部署了心跳程序,用于监控、统计、预警等,心跳程序会产生一些应用日志,这些应用日志中包含各类事件信息,假如我们想要对这些日志进行分类处理并结构化到数据库中,我们就可以采用DBus log程序对日志进行处理。
DBus可以接入多种数据源(Logstash、Flume、Filebeat等),此处以Logstash为例来说明如何接入DBus的监控和报警日志数据。

由于在dbus-n2和dbus-n3两台机器上分别存在监控和预警日志,为此我们分别在两台机器上部署了Logstash程序。心跳数据由Logstash自带的心跳插件产生,其作用是便于DBus对数据进行统计和输出,以及对源端日志抽取端(此处为Logstash)进行预警(对于Flume和Filebeat来说,因为它们没有心跳插件,所以需要额外为其定时产生心跳数据)。Logstash程序写入到Kafka中的数据中既有普通格式的数据,同时也有心跳数据。