
最近又开了一个新坑,CMU的15445,这是一门介绍数据库的课程。我follow的是2018年的课程,因为2018年官方停止了对外开放实验源码,所以我用的2017年的实验,但是问题不大,内容基本没有变化。想要获取实验源码的同学可以上github搜,或者直接clone我的代码,找到最早的commit就ok了,仓库地址在文末。课程配套教材是《
Database System Concepts》,https://book.douban.com/subject/4740662/ 最好看原版的,中文版的貌似页数和课程中的对不上。
言归正传,本lab将实现一个Buffer Pool Manager,又分为三个子任务:
实现一个Extendible Hash Table
实现一个LRU Page Replacement Policy
实现Buffer Pool Manager
Extendible Hash TableExtendible Hash Table是动态hash的一种,动态是相对静态来说的。hash的原理是通过hash函数,f(key)->B,将key映射到一个Bucket地址集合中,如果B集合选的比较小,那么当key增多后,越来越多的key会落在同一个Bucket中,这样查找效率会下降。如果B集合一开始就选的很大,那么有很多Bucket处于未满状态,浪费空间。为了解决这个问题,就引入动态hash的概念。
静态hash存在上述问题主要是hash函数确定好后就不能再变了。动态hash就没有这个问题。
Extendible Hash Table数据结构如下:
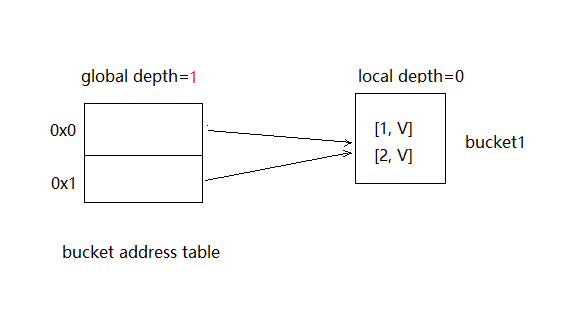
bucket address table是一个数组,保存bucket的地址。
global depth是一个整数值。
每个bucket都有一个local depth也是一个整数值,且小于等于global depth。每个bucket能装的键值对的最大值为bucketMaxSize。
查询比如要查找key=1对应的value值,首先取h(1)对应的二进制前global depth位,作为bucket address table的下标,找到存放该key的bucket,然后在相应的bucket中查找。
插入
如上图,假设bucketMaxSize为2.
最开始的情况如figure1,我们插入[1, v], [2, v],因为这时global depth=0所以,全部落在bucket1中,也就是figure2。
在figure2基础上,再插入[3, v],这时还是应该插到bucket1中,但是bucket1已经满了,同时bucket1的local depth = global depth = 1。这时先将bucket address table扩大一倍,同时global depth加1。然后重新创建两个新的bucket a, bucket b,local depth在原来local depth基础上加1(由0变为1),再将bucket 1中的[1, v], [2, v]分配到新的两个bucket中,分配规则如下:
如果h(key)的第local depth(1)位是0,那么放到bucket a中,如果为1那么放到bucket b中。分配完毕后,重新调整bucket address table中指向原来bucket 1的指针指向,这里index 0和1的指针原来都指向bucket 1,所以都需要调整,调整规则如下:
index的第local depth(1)位为0的指向bucket a, 为1的指向bucket b。
最后在插入[3, v], 假设h(3)的前global depth为1,那么插入到bucket b中。最终的效果如figure3。
在figure3基础上再插入[4, v],算法和前面一样,假设[4, v]本应插入到bucket a中,但是bucket a满了,且global depth = bucket 1的local depth。所以先将bucket address table扩大一倍。然后重新创建两个新的bucket, bucket c和bucket d,再将bucket a中的[1, v], [2, v]重新分配到bucket c和bucket d中。在调整buckert address table指针指向,最后再插入[4, v]。最终效果如figure 4。
在figure4基础上,再插入[5, v], [6, v],假设都落在bucket b中,那么插入[5, v]后bucket b将满,再插入[6, v]的时候bucket b已经满了。这时和前面不一样,此时global depth(2) > bucket b的local depth(1)。所以不需要扩大bucket address table。只需要创建两个新的bucket, bucket e和bucket f。将原来bucket b中的[3, v], [5, v]分配到bucket e和bucket f中。然后调整原来指向bucket b的指针指向bucket e和bucket f。最后在插入[6, v]。最终效果如figure 5。
LRU PAGE REPLACEMENT POLICY实现最近最少使用算法,说白了就是给你一些序列,比如1, 2, 3, 1,这时哪个是最近最少使用到的。可以画下图,越下面的越久没有使用到。先用了1,再用了2,那么2比1新,所以2在1上面,然后用了3,那么3应该在2的上面,最后用了1,那么把1从最下面调到最上面,同时2变到了最下面,至此2应该是最近最久没有使用的。
1 2 3 1 1 2 3 1 2那么用什么数据结构来存储呢?
先看下有哪些操作:
void Insert(const T &value); bool Victim(T &value); bool Erase(const T &value);Insert():将value加到最顶部,或者如果value已经在队列中,将其提取到最顶部。
Victim():提取最近最久没有使用的元素,将最底部的元素弹出。
Erase():删除某个元素。
首先想到的是单向链表。但是如果用单向链表的话,Victim()需要访问尾元素,单向链表每次都要从头到尾遍历一遍才能访问尾元素,性能可想而知。