
返回结果与之前的查询一样,但还是可以看到有一些变化。其中之一是,不再使用 query-string 参数,而是一个请求体替代。这个请求使用 JSON 构造,并使用了一个 match 查询
搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询
+ View Code?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
curl -XGET 'localhost:9200/megacorp/employee/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
} '
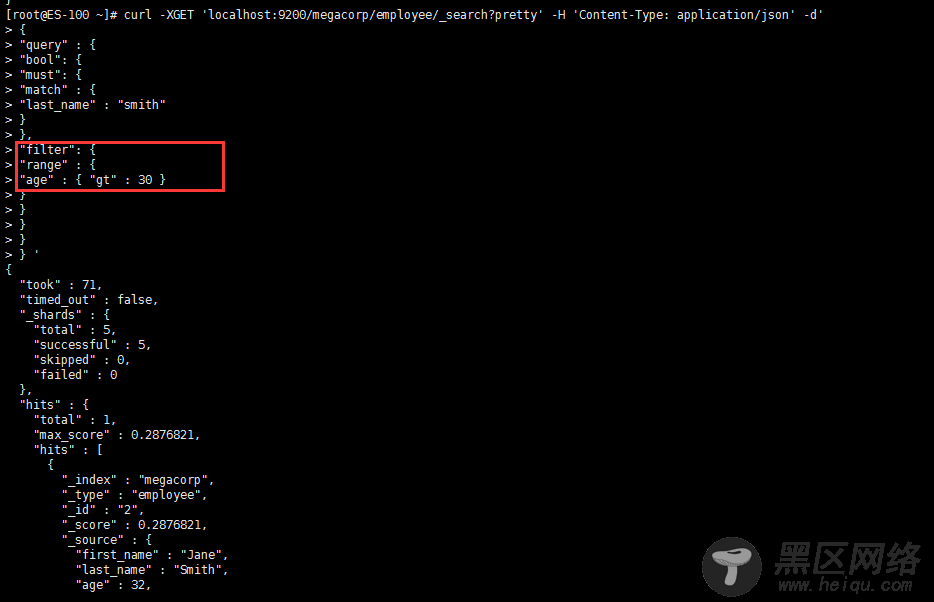
range 过滤器 , 它能找到年龄大于 30 的文档,其中 gt 表示_大于(_great than)
全文检索
搜索下所有喜欢攀岩(rock climbing)的雇员:
1 2 3 4 5 6 7 8
curl -XGET 'localhost:9200/megacorp/employee/_search?pretty' -H 'Content-Type: application/json' -d' { "query" : { "match_phrase" : { "about" : "rock climbing" } } }'

Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据
Elasticsearch 天生就是分布式的,并且在设计时屏蔽了分布式的复杂性。
Elasticsearch 尽可能地屏蔽了分布式系统的复杂性。这里列举了一些在后台自动执行的操作:
分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
将集群中任一节点的请求路由到存有相关数据的节点
集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。
而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red
+ View Code?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@ES-100 ~]# curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
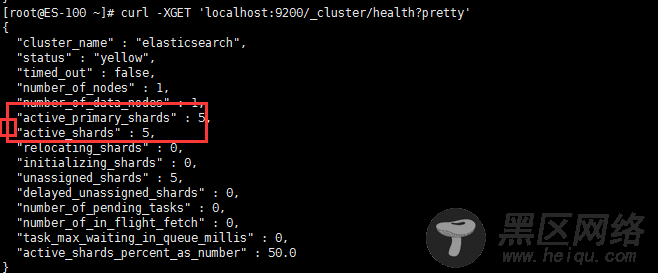
status 字段是要关注的
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下: