
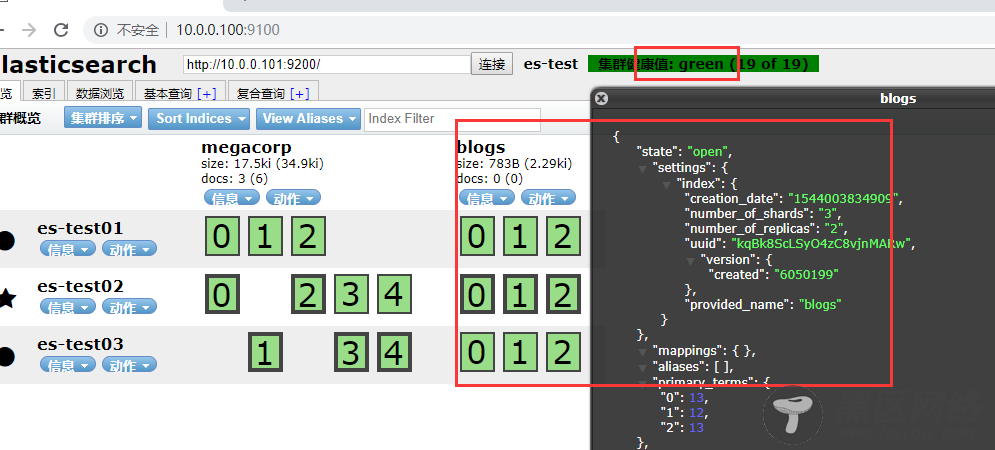
为什么集群状态是yellow 了,而不是green 了, 这里我设置了3个主分片,2个副本分片, 我在上面设置了blogs每个主分片需要对应2分副本分片, 正常这样设置的情况下, 应该有3个主分片6个副本分片, 但是现在有3个主分片, 3个副本分片,现在缺失副本分片了,所以此时的集群的状态会为yellow。
在重新启动es-test01 ,集群可以将缺失的副本分片再次进行分配。
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index 文档在哪存放
_type 文档表示的对象类别
_id 文档唯一标识
_index
_index 一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引 products中,而存储所有销售的交易到索引 sales 中
_type
数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 “electronics” 、”kitchen” 和 “lawncare”。
这些文档共享一种相同的(或非常相似)的模式:他们有一个标题、描述、产品代码和价格。他们只是正好属于“产品”下的一些子类
Elasticsearch 公开了一个称为 types (类型)的特性,它允许您在索引中对数据进行逻辑分区。不同types 的文档可能有不同的字段,但最好能够非常相似。
_id
ID 是一个字符串, 当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成。
1. 查询文档
例如
1
[root@ES-100 ~]# curl -XGET :9200/megacorp/employee/1?pretty

2. 返回文档一部分
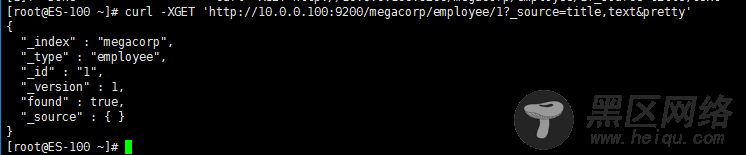
默认情况下, GET 请求 会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定
1
[root@ES-100 ~]# curl -XGET 'http://10.0.0.100:9200/megacorp/employee/1?_source=title,text&pretty'
3. 检查文档是否存在
如果只想检查一个文档是否存在 –根本不想关心内容–那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
1 2
[root@ES-100 ~]# curl -i -XHEAD :9200/website/blog/123 [root@ES-100 ~]# curl -i -XHEAD :9200/megacorp/employee/1
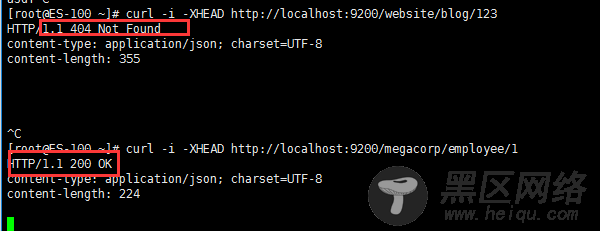
如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码:
4. 删除文档
删除文档 的语法和我们所知道的规则相同,只是 使用 DELETE 方法:
1
[root@ES-100 ~]# curl -i -XDELETE 'http://localhost:9200/megacorp/employee/1?pretty'
与上面与elasticsearch 交互那一块 可以看看
10 索引的CRUD1 . 删除一个索引编辑
也是用curl 方式
用以下的请求来 删除索引:
1
DELETE /my_index
也可以这样删除多个索引
1 2
DELETE /index_one,index_two DELETE /index_*
甚至可以这样删除 全部 索引:
1 2
DELETE /_all DELETE /*
对一些人来说,能够用单个命令来删除所有数据可能会导致可怕的后果。如果你想要避免意外的大量删除, 你可以在你的elasticsearch.yml 做如下配置:
1
action.destructive_requires_name: true
这个设置使删除只限于特定名称指向的数据, 而不允许通过指定 _all 或通配符来删除指定索引库。
2. 索引设置编辑